
- Il Deep Learning è una sottocategoria del Machine Learning che utilizza reti neurali artificiali complesse per riconoscere relazioni nascoste nei dati. Questa tecnologia consente alle macchine di apprendere e migliorare autonomamente attraverso l’elaborazione di grandi volumi di dati.
- Il Deep Learning ha numerose applicazioni, tra cui la visione artificiale, il riconoscimento vocale, la bioinformatica e la guida autonoma. Le reti neurali profonde sono particolarmente efficaci nel risolvere problemi complessi grazie alla loro capacità di costruire livelli gerarchici di astrazione, migliorando le prestazioni man mano che aumentano i dati disponibili.
- Framework come TensorFlow e PyTorch sono ampiamente utilizzati per sviluppare applicazioni di Deep Learning. Tuttavia, l’addestramento di reti neurali profonde richiede enormi capacità computazionali e grandi quantità di dati etichettati, rendendo il processo costoso e complesso.
La traduzione letterale è apprendimento profondo, ma il Deep learning, sottocategoria del Machine learning e del più ampio mondo dell’intelligenza artificiale, sottende a qualcosa di molto più ampio del semplice apprendimento su più livelli delle macchine. Cerchiamo allora di capire cos’è il Deep Learning, come funziona e che tipo di applicazioni può avere.
Indice degli argomenti:
Deep learning, un primo approccio
Il Deep learning è una tipologia di Machine learning che si concentra sull’utilizzo di reti neurali più complesse per riconoscere le relazioni tra input diversi, osservando strutture nascoste dei dati. Una rete neurale è una rete di neuroni artificiali interconnessi, che vengono usati per risolvere problemi ed eseguire le operazioni necessarie.
Le reti neurali sono state progettate per funzionare come il cervello umano: l’input viene elaborato da strati di neuroni, che producono un output più complesso. La potenza della rete neurale deriva dal fatto che il numero di strati aumenta con l’aumentare delle informazioni fornite alla rete.
Gli algoritmi di apprendimento profondo possono essere utilizzati per riconoscere modelli nei grandi volumi di dati, oltre che per implementare previsioni che potrebbero non essere immediatamente evidenti. Questa tecnologia è stata ampiamente utilizzata nel campo dell’intelligenze artificiali, della visione artificiale e del riconoscimento vocale.
Le reti neurali possono essere applicate anche ai processi decisionali in cui i dati sono complessi o in cui la logica non è immediatamente evidente. Il loro uso può aiutare ad analizzare i dati, riconoscere le tendenze e prevedere risultati. Le reti neurali possono essere anche utilizzate per creare sistemi di controllo che reagiscono automaticamente a determinate situazioni, come la guida autonoma di veicoli o il controllo del traffico aereo.
Inoltre, le reti neurali possono essere utilizzate per migliorare la produttività in un’organizzazione sebbene i processi e le procedure siano già automatizzati.
Cos’è il Deep learning
Il Deep learning indica quella branca dell’intelligenza artificiale che fa riferimento agli algoritmi ispirati alla struttura e alla funzione del cervello, chiamate reti neurali artificiali.
Dal punto di vista scientifico, si potrebbe affermare che il Deep learning rappresenti l’apprendimento delle macchine attraverso l’elaborazione di dati appresi utilizzando principalmente algoritmi di calcolo statistico.
Il Deep learning (noto anche come apprendimento strutturato profondo o apprendimento gerarchico), infatti, fa parte di una più ampia famiglia di metodi di Machine learning basati sull’assimilazione di rappresentazioni di dati, al contrario degli algoritmi per l’esecuzione di task specifici.
Le architetture di Deep learning (con le quali oggi si riporta all’attenzione anche del grande pubblico il concetto di rete neurale artificiale) sono per esempio state applicate nella computer vision, nel riconoscimento automatico della lingua parlata, nell’elaborazione del linguaggio naturale, nel riconoscimento audio e nella bioinformatica, ovvero l’utilizzo di strumenti informatici per descrivere dal punto di vista numerico e statistico determinati fenomeni biologici come le sequenze di geni, la composizione e la struttura delle proteine, i processi biochimici nelle cellule.
Abbiamo raccolto le diverse interpretazioni di alcuni tra i più noti ricercatori e scienziati nel campo dell’apprendimento profondo:
- Andrew Yan-Tak Ng, docente associato all’università di Stanford e già fondatore di Google Brain e Chief Scientist di Baidu;
- Ian J. Goodfellow, ricercatore al DeepMind e inventore delle reti GAN;
- Yoshua Bengio, autorità nel campo del Deep learning;
- Ilya Sutskever, Co-founder e Chief Scientist di OpenAI;
- Geoffrey Everest Hinton, una delle figure chiave del Deep learning e dell’Intelligenza artificiale, primo ricercatore ad aver dimostrato l’uso di un algoritmo di backpropagation generalizzato per l’addestramento di reti neurali multistrato.
Possiamo quindi definire il Deep learning come un sistema che sfrutta una classe di algoritmi di apprendimento automatico che:
- usano vari livelli di unità non lineari a cascata per svolgere compiti di estrazione di caratteristiche e di trasformazione. Ciascun livello successivo utilizza l’uscita del livello precedente come input. Gli algoritmi possono essere sia di tipo supervisionato sia non supervisionato e le applicazioni includono l’analisi di pattern (apprendimento non supervisionato) e classificazione (apprendimento supervisionato);
- sono basati sull’apprendimento non supervisionato di livelli gerarchici multipli di caratteristiche (e di rappresentazioni) dei dati. Le caratteristiche di più alto livello vengono derivate da quelle di livello più basso per creare una rappresentazione gerarchica;
- fanno parte della più ampia classe di algoritmi di apprendimento della rappresentazione dei dati all’interno dell’apprendimento automatico (Machine learning);
- apprendono multipli livelli di rappresentazione che corrispondono a differenti livelli di astrazione; questi livelli formano una gerarchia di concetti.
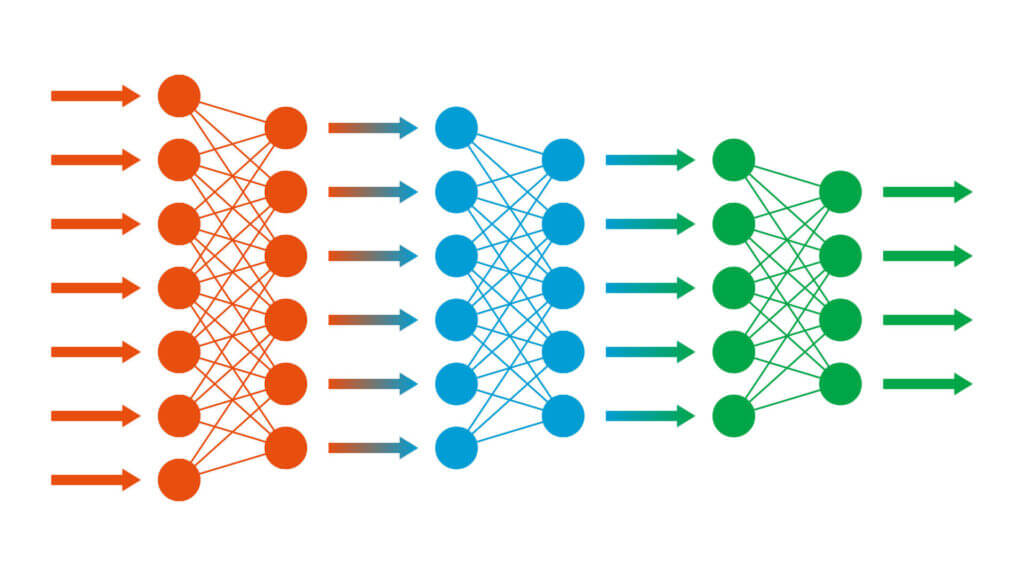
Applicando il Deep learning, avremo quindi una macchina che riesce autonomamente a classificare i dati e a strutturarli gerarchicamente, trovando quelli più rilevanti e utili alla risoluzione di un problema (esattamente come fa la mente umana), migliorando le proprie prestazioni con l’apprendimento continuo.
Le reti neurali artificiali, base del Deep learning
Come accennato nel paragrafo precedente, il deep learning, o apprendimento profondo, si basa sulla classificazione e selezione dei dati più rilevanti per raggiungere una conclusione.
Questo processo richiama il funzionamento del nostro cervello biologico, in cui i neuroni e le connessioni neurali vengono attivati per formulare risposte, dedurre ipotesi logiche e risolvere problemi.
Infatti, neuroni biologici interconnessi formano le nostre reti neurali cerebrali, che permettono a ciascun individuo di ragionare, fare calcoli in parallelo, riconoscere suoni, immagini, volti, imparare e agire.
Il Deep Learning si comporta allo stesso modo e sfrutta le reti neurali artificiali, modelli di calcolo matematico-informatici basati sul funzionamento delle reti neurali biologiche, ossia modelli costituiti da interconnessioni di informazioni.
Una rete neurale di fatto si presenta come un sistema adattivo in grado di modificare la sua struttura (i nodi e le interconnessioni) basandosi sia su dati esterni sia su informazioni interne che si connettono e passano attraverso la rete neurale durante la fase di apprendimento e ragionamento.
Come funziona il Deep learning
Con il Deep learning vengono simulati i processi di apprendimento del cervello biologico attraverso sistemi artificiali (le reti neurali artificiali, appunto) per insegnare alle macchine non solo ad apprendere autonomamente ma a farlo in modo più “profondo” come sa fare il cervello umano dove profondo significa su più livelli (vale a dire sul numero di layer nascosti nella rete neurale – chiamati hidden layer: quelle tradizionali contengono 2-3 layer, mentre le reti neurali profonde possono contenerne oltre 150).
L’immagine di seguito (tratta dall’eBook disponibile online gratuitamente Neural Networks and Deep learning) può aiutare a comprendere meglio la struttura delle reti neurali profonde.
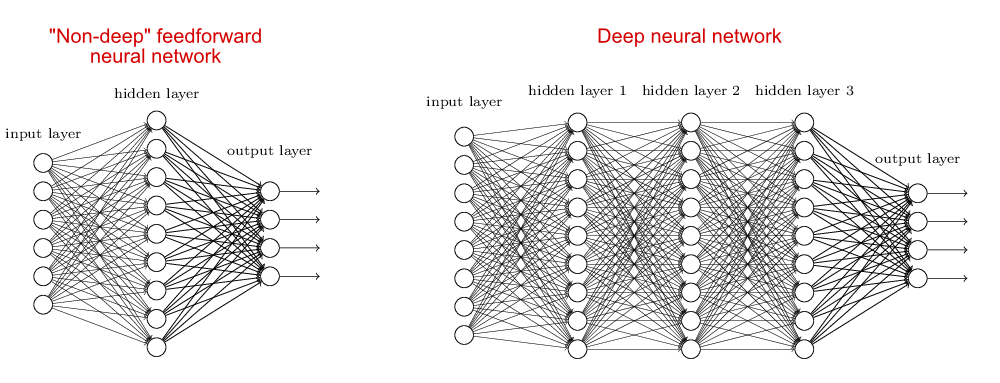
La struttura delle reti neurali profonde
Le reti neurali profonde sfruttano un numero maggiore di strati intermedi (hidden layer) per costruire più livelli di astrazione, proprio come si fa nei circuiti booleani, i modelli matematici di computazione usati nello studio della teoria della complessità computazionale che, in informatica, studia le risorse minime necessarie – principalmente tempo di calcolo e memoria – per la risoluzione di un problema.
Proviamo a fare un esempio concreto di funzionamento di una rete neurale profonda con il riconoscimento visivo dei pattern: i neuroni del primo strato potrebbero imparare a riconoscere i bordi. I i neuroni nel secondo strato potrebbero imparare a riconoscere forme più complesse, ad esempio triangoli o rettangoli, create dai bordi. Il terzo strato riconoscerebbe forme ancora più complesse, il quarto ulteriori dettagli e così via.
I molteplici livelli di astrazione possano dare alle reti neurali profonde un vantaggio enorme nell’imparare a risolvere complessi problemi di riconoscimento di schemi, proprio perché a ogni livello intermedio aggiungono informazioni e analisi utili a fornire un output affidabile.
È abbastanza facile intuire che quanti più livelli intermedi ci sono in una rete neurale profonda (quindi quanto più è grande la rete neurale stessa) tanto più efficace è il risultato. Di contro, la scalabilità della rete neurale è strettamente correlata ai dataset, ai modelli matematici e alle risorse computazionali.
Scalabilità del Deep learning
Anche se la richiesta di immense capacità computazionali rappresenta un ostacolo, la scalabilità del Deep learning, grazie all’aumento dei dati disponibili e degli algoritmi, è ciò che lo distingue dal Machine Learning.
I sistemi di Deep learning, infatti, migliorano le proprie prestazioni a mano a mano che i dati aumentano, mentre le applicazioni di Machine learning, noti anche come sistemi di apprendimento superficiale, una volta raggiunto un determinato livello di performance, non sono più scalabili nemmeno aggiungendo esempi e dati di training alla rete neurale.
Questo perché nei sistemi di Machine learning le caratteristiche di un determinato oggetto (nel caso di sistemi di riconoscimento visivo) vengono estratte e selezionate manualmente e servono per creare un modello in grado di categorizzare gli oggetti (in base alla classificazione e al riconoscimento di quelle caratteristiche).
Nei sistemi di Deep learning, invece, l’estrazione delle caratteristiche avviene in modo automatico: la rete neurale apprende in modo autonomo come analizzare dati grezzi e come svolgere un compito (per esempio classificare un oggetto riconoscendone, autonomamente, le caratteristiche).
Se dal punto di vista delle potenzialità il Deep learning può sembrare più affascinante e utile del Machine learning, va precisato che il calcolo computazionale richiesto per il loro funzionamento è davvero impattante, anche dal punto di vista economico: le CPU più avanzate e le GPU top di gamma utili a reggere i workload di un sistema di Deep learning costano ancora migliaia di dollari.
Il ricorso a capacità computazionali via Cloud attenuano solo in parte il problema perché la formazione di una rete neurale profonda richiede spesso l’elaborazione di grandi quantità di dati utilizzando cluster di GPU di fascia alta per molte, molte ore (non è detto quindi che acquistare as a service la capacità di calcolo necessaria risulti economico).
Come si addestra un sistema di Deep learning
Un semplicissimo quanto efficace esempio per capire il reale funzionamento di un sistema di Machine learning (e la differenza con un sistema di Deep learning) ci viene fornito da Tech Target:
«Mentre gli algoritmi di apprendimento automatico tradizionali sono lineari, gli algoritmi di apprendimento profondo sono impilati in una gerarchia di crescente complessità e astrazione. Per capire l’apprendimento profondo, immaginiamo un bambino la cui prima parola è “cane”. Il bambino impara cos’è un cane (e cosa non lo è) indicando oggetti e dicendo la parola cane. Il genitore dice “Sì, quello è un cane” o “No, non è un cane”. Mentre il bambino continua a puntare agli oggetti, diventa più consapevole delle caratteristiche che tutti i cani possiedono. Ciò che il bambino fa, senza saperlo, è chiarire un’astrazione complessa (il concetto di cane) costruendo una gerarchia in cui ogni livello di astrazione viene creato con la conoscenza che è stata acquisita dallo strato precedente della gerarchia».
A differenza del bambino, che impiegherà settimane o addirittura mesi per comprendere il concetto di cane e lo farà con l’aiuto del genitore (quello che viene definito apprendimento supervisionato), una applicazione che utilizza algoritmi di Deep learning può mostrare e ordinare milioni di immagini, identificando con precisione quali immagini contengono i set di dati, in pochi minuti pur non avendo avuto alcun tipo di indirizzamento sulla correttezza o meno dell’identificazione di determinate immagini nel corso del training.
Nel Deep learning i dati sono etichettati
Solitamente, nei sistemi di Deep learning, l’unica accortezza degli scienziati è etichettare i dati (con i meta tag), per esempio inserendo il meta tag “cane” all’interno delle immagini che contengono un cane ma senza spiegare al sistema come riconoscerlo: è il sistema stesso, attraverso livelli gerarchici multipli, che intuisce cosa caratterizza un cane (le zampe, la cosa, il pelo, ecc.) e quindi come riconoscerlo.
Questi sistemi si basano, in sostanza, su un processo di apprendimento trial-and-error ma perché l’output finale sia affidabile sono necessarie enormi quantità di dati.
Pensare subito ai Big data e alla facilità con cui oggi si producono e distribuiscono dati di qualsiasi forma e da qualsiasi fonte come facile risoluzione sarebbe però un errore: l’accuratezza dell’output richiede, almeno nella prima fase di addestramento, l’utilizzo di dati etichettati (contenenti dei meta tag) che significa che l’utilizzo di dati non strutturati potrebbero rappresentare un problema. I dati non strutturati possono essere analizzati da un modello di apprendimento profondo una volta formato e raggiunto un livello accettabile di accuratezza, ma non per la fase di training del sistema.
Non solo, i sistemi basati su Deep learning sono difficili da addestrare a causa del numero stesso di strati nella rete neurale. Il numero di strati e collegamenti tra i neuroni nella rete è tale che può diventare difficile calcolare le “regolazioni” che devono essere apportate in ogni fase del processo di addestramento (un problema indicato come problema della scomparsa del gradiente).
Questo perché per il training comunemente si usano i cosiddetti algoritmi di retropropagazione dell’errore (backpropagation) attraverso il quale si rivedono i pesi della rete neurale (le connessioni tra i neuroni) in caso di errori (la rete propaga all’indietro l’errore in modo che i pesi delle connessioni vengano aggiornati in modo più appropriato). Un processo che continua in modo iterativo finché il gradiente (l’elemento che dà la direzione verso cui l’algoritmo deve muoversi) è nullo.
Deep Learning Framework: da TensorFlow a PyTorch
Uno dei framework specifici per il Deep learning più in uso tra ricercatori, sviluppatori e data scientist è TensorFlow, nota libreria software open source (progetto supportato da Google) per l’apprendimento automatico che fornisce moduli testati e ottimizzati per la realizzazione di algoritmi da impiegare in diversi tipi di software e con diversi tipi di linguaggi di programmazione, da Python, C/C++, Java, Go, RUST, R, … (in particolare per compiti percettivi e per la comprensione del linguaggio naturale).
Dal 2019 si è fatto strada PyTorch, un progetto open source sviluppato da Facebook e oggi parte della galassia Linux.
Inizialmente (e per diversi anni) gli sviluppatori di Meta hanno utilizzato un framework noto come Caffe2, che è stato adottato anche da molte università e ricercatori. Nel 2018 però Facebook aveva annunciato che stava lavorando ad un altro tipo di framework accessibile alla comunità open source, che combinasse il meglio di Caffe2 e ONNX in un nuovo framework (PyTorch).
ONNX sta per Open Neural Network Exchange ed è un framework interoperabile cui anche Microsoft e AWS contribuiscono attivamente fornendo supporto per Microsoft CNTK e Apache MXNet. PyTorch 1.0, di fatto, combina il meglio di Caffe2 e ONNX (è uno dei primi framework con supporto nativo per i modelli ONNX).
Ciò su cui si sono concentrati gli sviluppatori di Meta (ma non solo) è stata la creazione di un framework molto più semplice ed accessibile rispetto a TensorFlow. PyTorch, per esempio, utilizza una tecnica nota come calcolo dinamico che semplifica l’addestramento delle reti neurali.
Non solo, il modello di esecuzione di PyTorch imita il modello di programmazione convenzionale noto a uno sviluppatore medio di Python. Offre inoltre formazione distribuita, profonda integrazione in Python e un vivace ecosistema di strumenti e librerie (come Keras).
Da settembre 2022, Meta ha annunciato la nascita della PyTorch Foundation, un’organizzazione indipendente all’interno della Linux Foundation.
Casi d’uso e i tipi di applicazioni del Deep learning
Nonostante le problematiche che abbiamo illustrato, i sistemi di Deep learning hanno compiuto enormi passi evolutivi e sono migliorati moltissimo negli ultimi anni, soprattutto per la grandissima quantità di dati a disposizione ma soprattutto per la disponibilità di infrastrutture ultra performanti (CPU e GPU in particolare).
Nell’ambito della ricerca sull’artificial intelligence, l’apprendimento automatico ha riscosso un notevole successo negli ultimi anni, consentendo ai computer di superare o avvicinarsi alle prestazioni umane corrispondenti in aree che vanno dal riconoscimento facciale al quello vocale e linguistico. L’apprendimento profondo invece consente ai computer di fare un passo in avanti, in particolare di risolvere una serie di problemi complessi.
Da semplici cittadini non esperti di tecnologia, è possibile notare diversi casi d’uso ed ambiti di applicazione:
- la computer vision per le auto senza conducente,
- i robot droni impiegati per la consegna di pacchi o l’assistenza in emergenza (per esempio per la consegna di cibo o farmaci in zone di crisi);
- il riconoscimento e la sintesi vocale e linguistica per chatbot e robot di servizio;
- il riconoscimento facciale per sorveglianza in paesi come la Cina;
- il riconoscimento immagini per la diagnostica come radiologiche o l’individuazione di sequenze genetiche o di molecole farmaceutiche;
- sistemi di analisi per la manutenzione predittiva su una infrastruttura o un impianto analizzando i dati dei sensori IoT.
I compiti che una macchina può svolgere grazie al Deep learning
- colorazione automatica delle immagini in bianco e nero: per la rete neurale significa riconoscere bordi, sfondi, dettagli e conoscere i colori tipici di una farfalla, per esempio, sapendo esattamente dove collocare il colore corretto;
- aggiunta automatica di suoni a filmati silenziosi: per il sistema di Deep learning significa sintetizzare suoni e collocarli correttamente all’interno di una situazione particolare riconoscendo immagini ed azioni, per esempio inserendo il suono del martello pneumatico, della rottura dell’asfalto e i sottofondi di una strada cittadina trafficata in un video in cui si vedono dei lavoratori che stanno rompendo l’asfalto con il martello pneumatico;
- traduzione simultanea: per il sistema di Deep learning significa ascoltare e riconoscere il linguaggio naturale, riconoscere la lingua parlata e tradurre il significato in un’altra lingua;
- classificazione degli oggetti all’interno di una fotografia:il sistema in questo caso è in grado di riconoscere e classificare tutto ciò che vede in un’immagine, anche molto complessa dove per esempio c’è un paesaggio di sfondo, per esempio delle montagne, persone che camminano lungo un sentieri, degli animali al pascolo, ecc.;
- generazione automatica della grafia: ci sono già oggi sistemi di Deep learning capaci di utilizzare la grafia umana per scrivere addirittura apprendendo gli stimi della scrittura a mano degli esseri umani ed imitandola;
- generazione automatica di testo: è un processo in cui i sistemi apprendono a scrivere correttamente nella lingua prescelta, rispettando ortografia, punteggiatura e grammatica. Oltre a ciò, questi sistemi imparano anche a utilizzare diversi stili di scrittura, a seconda degli obiettivi, come la produzione di articoli giornalistici o racconti.
- generazione automatica di didascalie: in questo caso il riconoscimelo delle immagini, l’analisi del contesto e la capacità di scrittura consentono a un sistema di scrivere in automatico le didascalie di una immagine descrivendone perfettamente la scena;
- gioco automatico: Abbiamo scoperto le potenzialità di un sistema in grado di imparare autonomamente a giocare a un determinato gioco grazie a DeepMind, oggi parte di Google. Attraverso il suo sistema di Deep learning chiamato AlphaGo, non solo ha imparato a giocare al complessissimo gioco Go, ma ha anche sconfitto il campione mondiale umano. Questa straordinaria dimostrazione di intelligenza artificiale ha aperto nuove prospettive nel campo del machine learning e ha suscitato grande fascino e interesse in tutto il mondo.
Alcuni dei campi di applicazione del Deep learning
Driverless car
Traffic Sign Detection (TDS) è una funzione presente su molte auto di nuova fabbricazione che permette di riconoscere i segnali stradali. Si tratta di una applicazione di machine learning che utilizza le reti neurali convoluzionali e framework come Tensorflow.
Cinema
All’inizio del 2021 è stata presentata una nuova metodologia di AI applicabile nella produzione cinematografica. Il nuovo approccio sfrutta una combinazione parallela e sequenziale di vari strumenti di deep learning come VGG16, MLP e transfer learning.
Utilizzando dataset diversificati e mettendo in risalto differenti caratteristiche delle immagini, si mira a ottenere una classificazione accurata delle inquadrature cinematografiche.
Questo permette un utilizzo professionale e operativo nel processo di creazione cinematografica e nell’indicizzazione dei contenuti streaming. Parliamo di AI applicata all’image processing.
Quantum Intelligence
Sul quantum computing si concentrano grandi aspettative. Un innovativo paradigma di elaborazione richiede non solo nuove tecnologie hardware, algoritmi avanzati, ma anche soluzioni all’avanguardia. La sua caratteristica principale risiede nella capacità di semplificare notevolmente la soluzione di problemi complessi, riducendone la complessità esponenziale.
Prendiamo ad esempio la determinazione dei fattori di un numero, un problema fondamentale nell’ambito della crittografia e con numerose applicazioni nel campo della sicurezza informatica. Questo paradigma apre nuove prospettive e spalanca le porte a un mondo di opportunità senza precedenti.
Ologrammi
Uno studio condotto sugli ologrammi nel 2021 dai ricercatori del Massachussets Institute of Technology (MIT) ha dimostrato che grazie all’innovativa tecnica di deep chiamata olografia tensoriale è possibile generare istantaneamente video olografici sfruttando la potenza di calcolo di un comune computer.
L’aspetto unico di questa tecnologia risiede nell’utilizzo di tensori addestrabili, capaci di apprendere come elaborare informazioni visive e di profondità in modo simile al cervello umano. Questo permette di ottenere risultati straordinari, con un realismo e un dettaglio senza precedenti.




