
L’intelligenza artificiale, grazie al deep learning, si è ritagliata un posto nella nostra vita, se solo pensiamo ad Alexa o alle funzioni di guida autonoma delle auto. Il deep learning, ormai da anni, aiuta a classificare recensioni, a riconoscere un capo di abbigliamento in una foto (per esempio usando il dataset Fashion-MNIST reperibile su github, zalandoresearch/fashion-mnist) e persino a identificare tumori dagli esami radiologici.
Keras è una libreria scritta in Python (compatibile con Python2.7-3.6 e rilasciata sotto licenza MIT). Si tratta di software open source per l’apprendimento automatico e le reti neurali e supporta come back-end fra l’altro TensorFlow (dal 2017). Keras offre moduli utili per organizzare differenti livelli. Il tipo principale di modello è quello sequenziale, ovvero una pila lineare di livelli.
Keras consente una prototipazione facile e veloce, supporta sia reti convoluzionali (CNN) che reti ricorrenti (RNN) o combinazioni di entrambi, supporta schemi di connettività come multi-input e multi-output e funziona sia su CPU che GPU.
Indice degli argomenti:
Deep learning con Python
Il deep learning (apprendimento profondo) è un sottocampo specifico dell’apprendimento automatico: una nuova interpretazione delle rappresentazioni dell’apprendimento dai dati che pone l’accento sull’apprendimento di livelli successivi di rappresentazioni significative. Il “deep” in deep learning non è un riferimento a nessun tipo di comprensione più profonda raggiunta dall’approccio; piuttosto, rappresenta questa idea di strati successivi di rappresentazioni. Quanti livelli contribuiscono a un modello di dati è chiamato profondità del modello. Altri nomi appropriati per il campo avrebbero potuto essere “apprendimento delle rappresentazioni a strati” o “apprendimento delle rappresentazioni gerarchiche”. Il moderno apprendimento profondo coinvolge spesso decine o addirittura centinaia di strati successivi di rappresentazioni. Ma altri approcci all’apprendimento automatico tendono a focalizzarsi sull’apprendimento solo di uno o due strati di rappresentazioni dei dati; si parla in questo caso di “apprendimento superficiale”.
Nell’apprendimento profondo, queste rappresentazioni a strati vengono (quasi sempre) apprese tramite modelli chiamati reti neurali, strutturati in strati sovrapposti uno sull’altro. Fra i linguaggi più popolari per il deep learning c’è Python. Le librerie per Python che ci permettono di creare reti neurali artificiali sono varie, fra queste ad esempio Pandas (usata per l’analisi dei dati) o Numpy (libreria per il calcolo numerico, che ci permette di operare su matrici e vettori) o scikit-learn (usata per funzioni sui dataset).
Tensorflow e Keras
Keras quindi è una libreria di alto livello, mentre Tensorflow (come Theano o CNTK) è una libreria di basso livello denominata backend, proprio per il ruolo che svolge nella pila software.
Fonte: https://keras.io/why_keras/
Keras è spesso citato nella letteratura scientifica perché utilissimo per le sperimentazioni veloci e poco costose: si passa velocemente dall’idea al risultato. Esempi di oggetti Keras sono i modelli (ad esempio Sequential), i layer (come Dropout), gli ottimizzatori (come Adam).
I parametri di una distribuzione “a priori” sono chiamati iperparametri, per distinguerli dai parametri del modello stesso. Nella foto qui sotto, notiamo due cluster di dati.
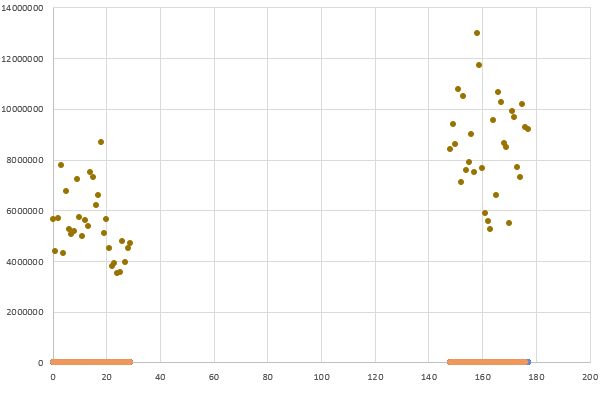
Gli algoritmi di clustering hanno l’obiettivo di minimizzare la varianza totale all’interno del gruppo. L’algoritmo “k-means” in particolare, converge velocemente e riesce a suddividere un insieme di oggetti in k gruppi agendo su dati generati da distribuzioni gaussiane. K in questo caso è proprio l’iperparametro, variando il quale si riesce ad individuare in un insieme di dati il corretto numero di cluster. Vediamo un caso di ottimizzatore, quello usato per ottimizzare gli iperparametri (grazie alla libreria Hyperopt).
L’esempio più basilare di applicazione è quello che contempla due funzioni, una che “allena” una semplice rete neurale ed una che ne valuta le prestazioni. Grazie alle funzioni di ottimizzazione della libreria Hyperopt (opt da option, scelta), per ogni configurazione di iperparametri da provare alleniamo un modello sulla parte rimanente di training, e ne valutiamo le prestazioni su quella di validazione. Si parte sempre dal definire uno spazio di ricerca, che si compone di scelte fatte in un range discreto (la grandezza del layer) e di un learning rate esponenziale (altro iperparametro). Per un problema semplice, dopo poche decine di iterazioni si raggiunge subito un’accuratezza elevata.
Qui sotto la pagina GitHub di Hyperopt:
Keras: dipendenze e installazione
Keras sfrutta tutta una serie di dipendenze, fra le quali: scipy, pyyaml, HDF5 o scikit-image e cuDNN.
Ci sono vari modi per installare Keras, uno dei più semplici presuppone l’utilizzo di Github (presupponendo che sia installato e funzionante).
Il primo step è clonare Keras con il comando git che segue:
[root@host ~]# git clone https://github.com/keras-team/keras.git
Ci spostiamo poi sotto la folder Keras e lanciamo il comando seguente:
[root@host ~]# cd keras
[root@host ~]# python setup.py install
Se vogliamo usare Tensorflow come backend ricordiamoci di verificare che sia configurato. Il file .json si trova nella $HOME. Verifichiamo che sia impostato il corretto backend.
{
“image_data_format”: “channels_last”,
…
“backend”: “tensorflow”
}
Impostato “tensorflow” (o un backend alternativo, come“cntk,” “theano”) siamo pronti per il primo run di Keras.


