
Presentiamo una nuova metodologia di AI applicabile nella produzione cinematografica, frutto di recentissime elaborazioni sperimentali e tutt’ora in fase di studio. Una metodologia differente, per diversi motivi, da quelle illustrate in un altro articolo. Il nuovo approccio, difatti, si avvale di diversi strumenti di deep learning in parallelo e in serie (VGG16, MLP, transfer learning) e adopera differenti tipologie di dataset (immagini con feature diverse messe in risalto) al fine di poter classificare in modo accurato e robusto (senza Overfitting o Underfitting) le inquadrature cinematografiche e permetterne così un utilizzo professionale e operativo nel processo di film making o nell’attività di indicizzazione dei contenuti streaming. In sostanza, stiamo parlando di AI applicata all’image processing.
Indice degli argomenti:
Il deep learning applicato all’image processing
In generale, la tecnica qui presentata corrisponde a un ensemble learning[1] in versione stacking learning[2] rivisitata[3], che combina i set di predizioni provenienti da tre reti VGG16 (first classifier) tramite un meta-classificatore (una rete semplice
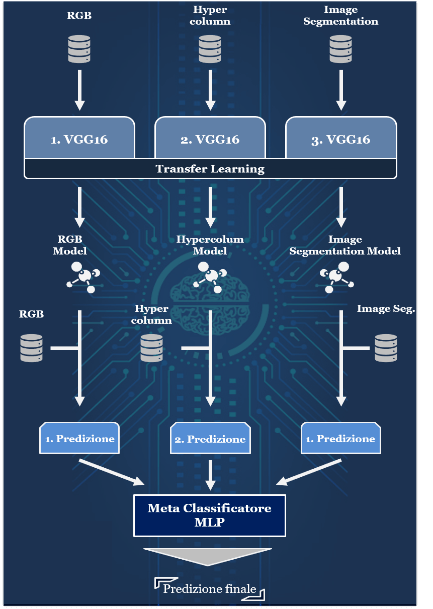
Rappresentazione dell’approccio di Stacking Ensemble Learning presentata
Entrando nel dettaglio, le VGG16 vengono riaddestrate tramite tecnica di transfer learning su tre set di dati con caratteristiche differenti; attraverso tale utilizzo questo metodo di training crea un notevole vantaggio permettendo di utilizzare, per questa task, reti performanti come le VGG16 addestrate in modo robusto su dataset di grandi dimensioni (e.g. imageNet[4]), tramite un rapido re-training degli ultimi layer con campioni di dati anche di dimensioni non eccessive.
Il primo dei tre campioni (RGB), composto da oltre 9mila immagini a colori (cardinalità aumentata rispetto agli approcci presenti in letteratura), è frutto di un lavoro di etichettatura nelle diverse classi di inquadratura e di un iter di pre-processing (ridimensionamento, cambio formato a 16:9[5] e bilanciamento dei bianchi[6]) utile a rendere l’immagine più leggibile dalle reti (omogenee per dimensioni, formato e tonalità) e quindi più efficace in fase di addestramento.
I restanti set sono invece derivanti da Deep Learning transformation ad hoc effettuate sullo stesso primo campione di immagini RGB e quindi presentano la stessa cardinalità e lo stesso preprocessing all’interno della loro pipeline di utilizzo. Le trasformazioni implementate (Hypercolumn extraction[7], Semantic image segmentation[8]) hanno la finalità non solo di aumentare di tre volte il campione totale di dati adoperati (tre dataset da 9mila campioni contenenti ognuno una versione della stessa immagine per un totale di oltre 27mila inquadrature) e quindi effettuare una Data Augmentation[9] che permetta di superare i problemi di overfitting, ma anche di avere campioni che mettano in risalto le feature fondamentali delle inquadrature (ipercolonne) o che semplifichino le immagini (dati high dimensional) e riducano il “rumore di fondo” (segmentazione), ponendo in primo piano gli elementi più utili a fornire la giusta classificazione di un’immagine in una classe di inquadratura (e.g. una figura umana ben delineata porta l’algoritmo a classificarla all’interno di una delle classi in cui è presente in primo piano).

Esempi delle diverse versioni di immagine
Image processing: analisi del comportamento locale delle reti
Un’analisi del comportamento locale delle reti VGG16 addestrate su questi tre set di dati tramite un potente strumento di visual explanable AI, LIME[10], ci permette di comprendere, nelle diverse versioni, la regione dell’immagine che viene presa maggiormente in considerazione dalla rete per fornire la giusta predizione e quindi la corretta classificazione.
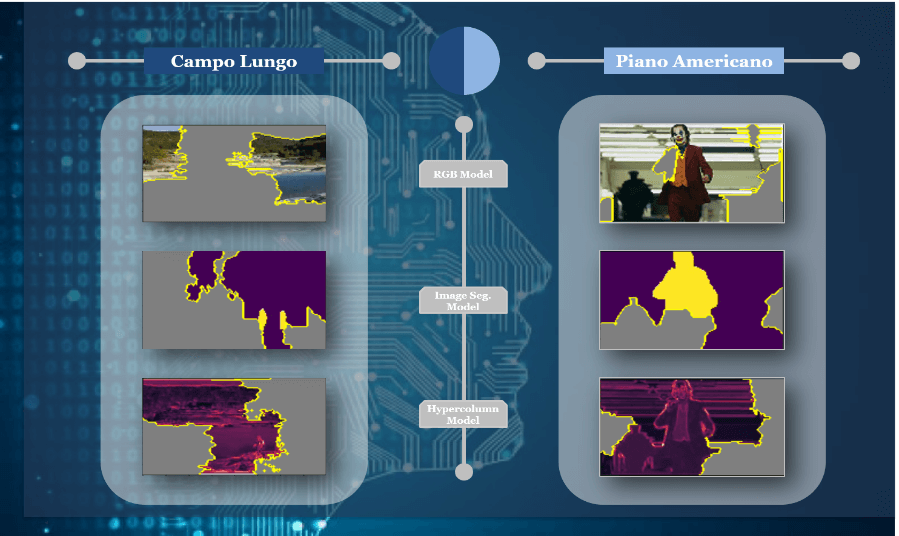
Analisi locale tramite LIME delle immagini nelle diverse versioni (RGB, Image Segmentation, Hypercolum) per due tipologie di inquadratura (campo lungo e piano americano)
Nell’image processing osserviamo come le regioni più rilevanti per effettuare la giusta predizione siano differenti per i tre modelli e ciò rende evidente come l’utilizzo di tre versioni delle stesse immagini con specifiche features in risalto per addestrare i classificatori VGG16 sia una mossa vincente all’interno della metodologia: la “ricombinazione” di tali regioni di evidenza (le regioni denotano la predizione che il modello effettuerà e queste saranno poi ricombinate dal meta classificatore come da pipeline dello stacking ensemble learning) porterà sicuramente a una migliore classificazione e ad una riduzione della probabilità di incorrere in Overfitting o Underfitting.
Oltre all’addestramento delle tre reti tramite transfer learning, questo approccio prevede una fase in cui vengono fornite alle VGG16 altri tre campioni di dati mai processati e non facenti parte dei dataset iniziali di training, su cui queste effettueranno contemporaneamente le predizioni di classificazione, ognuna sulla corretta versione dell’immagine su cui era stata addestrata. L’insieme di queste predizioni per ogni immagine costituiranno il set di addestramento del meta classificatore che, ricombinando queste informazioni (tre predizioni per ogni immagine), permette di migliorare l’accuracy e a stabilizzare il training, evitando qualsiasi problema di generalizzazione di apprendimento che lo renderebbe inutilizzabile.
I risultati ottenuti da questa tecnica di image processing sono molto incoraggianti. Dopo un primo layer in cui le tre VGG16 (first classifier in questo caso) raggiungono una test set accuracy tra il 70 e il 75% ed evidenziano un gap con l’accuratezza sul training set (>90%) il quale denota Overfitting, abbiamo un secondo livello di algoritmo in cui il meta-classificatore MLP, addestrato sul set di predizioni provenienti dalle VGG16, raggiunge un valore che si avvicina al 90%, non solo in training accuracy, ma anche in test accuracy. Ciò denota come, oltre al notevole aumento di performance, questa metodologia porti alla stabilizzazione dell’apprendimento, elemento fondamentale per un uso operativo in campo cinematografico.
Gli studi effettuati dimostrano, pertanto, come l’uso operativo in campo cinematografico di questa classificazione si attaglia in modo ottimale a tutti gli scenari di applicazione precedentemente esposti. Il risultato a cui si giunge, infatti, è quello di una suddivisione automatica dei video in classi di inquadratura: il video viene processato dall’algoritmo che, analizzando i frame e intuendo quale tipologia di scatto cinematografico è più presente al suo interno, lo etichetterà tramite metadati con la giusta classe.
Tale suddivisione, ottenuta con l’image processing, non è difficile immaginare quanto sia utile al video editor per riorganizzare nella giusta sequenza la mole di scene che si trova a gestire: se i video sono arricchiti del metadato rappresentante la tipologia di inquadratura, l’addetto non avrà necessità di vagliare tutti i file ma ricercherà solo all’interno della classe gli scatti di suo interesse.
Inoltre, la classificazione delle inquadrature cinematografiche risulterà essere vantaggiosa all’interno del cruscotto di algoritmi di Deep Learning utilizzati per il riconoscimento del genere, del contenuto e dell’autore. L’uso di alcune specifiche inquadrature è spesso, come noto, tratto distintivo per un genere cinematografico (e.g. in un film western sono utilizzati spesso scatti come il campo medio per permettere allo spettatore di vedere le mosse di entrambi i pistoleri durante un duello e come il piano americano per catturare il momento dell’estrazione della pistola) e per lo stile di un determinato regista (Stanley Kubrick, ad esempio, in quanto sempre alla ricerca del legame emotivo tra protagonista e spettatore, utilizzava moltissimo il primo piano che gli permetteva, in film come Shining, di focalizzare l’attenzione su un determinato particolare).
Naturalmente i video che compongono le scene riprese non sono costituiti solamente da una sequenza di inquadrature, ma sono caratterizzati anche da note audio che compongono il background sonoro, da accostamenti di colori, attori ecc. Pertanto, è necessario, che la classificazione automatizzata delle inquadrature lavori in sinergia con altri algoritmi di deep learning in grado di focalizzarsi su colori, note audio e riconoscimento facciale; così facendo potrebbe permettere di riconoscere il genere di un film e persino di riconoscere e identificare l’impronta del direttore di regia e quindi la paternità di una pellicola con una buona accuratezza, al fine di implementare l’indicizzazione intelligente.
Conclusioni
Non ce ne voglia Renè Ferretti con la sua mascotte Boris e il suo noto “elogio alla superficialità” (per chi conosce la popolare serie tv), ma l’industria del cinema ha un disperato bisogno di intelligenza artificiale. Un’intelligenza artificiale non improvvisata.
Attraverso questo studio (che è il frutto non del tutto maturo di una sperimentazione tutt’ora in corso) abbiamo dimostrato che la metodologia di deep learning consente una efficace classificazione automatica delle tipologie di inquadrature utilizzate nel mondo cinematografico, grazie all’image processing.
Non si tratta, certamente, di un punto di arrivo, ma il risultato raggiunto traccia la via verso una movie industry più high tech.
Sicuri che gli sforzi profusi non andranno perduti, ne attendiamo curiosi le strabilianti evoluzioni e gli effetti soprannaturali. Del resto “Il cinema è il modo più diretto per entrare in competizione con Dio” (F. Fellini).
Note
- L’ensemble learning è una tecnica di apprendimento automatico che si basa sulla elaborazione di più ipotesi (collezione), È un sistema complesso nel quale la macchina, partendo da un insieme di dati di addestramento (training set), costruisce un insieme di ipotesi (decision tree) e poi consulta tutti gli alberi decisionali che ha estrapolato. Tale sistema utilizza diversi classificatori i quali, collaborando fra loro mediante specifiche operazioni, consentono di ottimizzare la prestazione poiché vengono sfruttati i punti di forza di ogni modello e ne vengono limitate le debolezze. Esistono diverse tipologie di Ensemble Learning: Bagging (modelli dello stesso tipo vengono addestrati su dataset diversi, ognuno ottenuto dal campionamento iniziale e i risultati vengono riaggregati (hard voting e soft voting) per ridurre la variabilità e migliorare le performance), Boosting (persegue l’obiettivo di creare un modello che riduca la distorsione prodotta dai weak classifier. Tale metodologia si basa su modelli allenati iterativamente in step diversi dipendenti tra loro e posti in ordine sequenziale) e lo stacking (vedi nota 25) ↑
- Lo stacking learning usa modelli eterogenei. Inoltre, questa tecnica non prevede, come il Bagging, che il risultato di output derivi da una votazione ma combina le previsioni di singoli algoritmi servendosi di un ulteriore classificatore detto meta-classificatore. ↑
- Adopera tre modelli uguali addestrati su tre dataset con caratteristiche differenti e un meta-classificatore (tipico dello stacking) invece di prevedere tre tecniche di classificazione diverse, uno stesso campione dati di partenza e un ultimo classificatore ↑
- La VGG16 rete deve il suo successo al traguardo raggiunto nei test di accuratezza di classificazione del dataset “ImageNet” composto da più di 15 milioni di immagini ad alta risoluzione reperite su internet e suddivise in più di 1000 classi. (https://neurohive.io/en/popular-networks/vgg16/) ↑
- La ratio 16:9 risulta essere la più utilizzata in ambito cinematografico e tecnicamente il formato più semplice a cui ricondurre qualsiasi altra immagine con diversa ratio (4:3, …) ↑
- Il bilanciamento del bianco è la procedura grazie alla quale siamo in grado di interpretare in modo corretto la “luce della scena” e ottenere una scala di colori veritieri. L’operazione si basa sulla temperatura colore di una sorgente di luce e a valle di questa, è possibile eliminare sfumature innaturali dei colori e risalire alla colorazione originale dell’immagine (https://www.xn--photocaf-80a.it/bilanciamento-del-bianco/) ↑
- Ipercolonne è un termine proveniente dalla neuroscienza per definire un gruppo di neuroni di tipo V1 (corteccia visiva primaria) con una spiccata sensibilità nel riconoscere i bordi con orientamento a frequenze multiple e struttura a colonne. L’estrazione delle ipercolonne è una tecnica utile per mettere in risalto le feature fondamentali di un’immagine e quindi ottimizzare il processo di pattern recognition di un modello di Deep Learning ↑
- La Semantic Image Segmentation ha lo scopo di etichettare tutti i pixel di un’immagine con una relativa classe di appartenenza e quindi categorizzare e suddividere i pixel delineando curve, angoli ed elementi fondamentali di un oggetto presente all’interno attraverso predizioni effettuate su ogni pixel contenuto nel campione ↑
- Espansione del set di dati grazie alla generazione di diverse versioni delle stesse immagini ↑
- LIME (Local Interpretable Model-agnostic Explanation) è uno strumento molto adoperato nell’image processing ed è utilizzabile a valle di ogni modello di Deep Learning per catturare la regione dell’immagine che più è associata all’etichetta che la rete ha posto sul dato al termine della predizione (Tan, Hui Fen, K. Song, Madeilene Udell, Yiming Sun and Yujia Zhang. “”Why Should You Trust My Explanation?” Understanding Uncertainty in LIME Explanations.” arXiv: Learning (2019)) ↑


