
Nel settore dell’intelligenza artificiale, gli ultimi anni sono stati senza dubbio gli anni dei grandi modelli linguistici.
Gli annunci dei vari attori presenti sulla scena internazionale si sono succeduti con un ritmo alquanto elevato.
Abbiamo voluto riunirli e presentarli tutti.
Riepilogo dei modelli attuali: Visualizza i dati completi (fogli Google – Fonte: LifeArchitect.ai)
Scarica versione Pdf
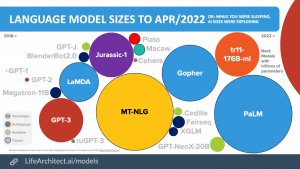
Dimensioni del modello linguistico
Indice degli argomenti:
Aumento delle dimensioni dei set di dati 2018-2022
Nel quinquennio 2018-2022 c’è stato un aumento delle dimensioni dei set di dati.
Contenuto di GPT-3 & the Pile v1

Contenuto di modelli cinesi

Dimensioni e previsioni del modello linguistico
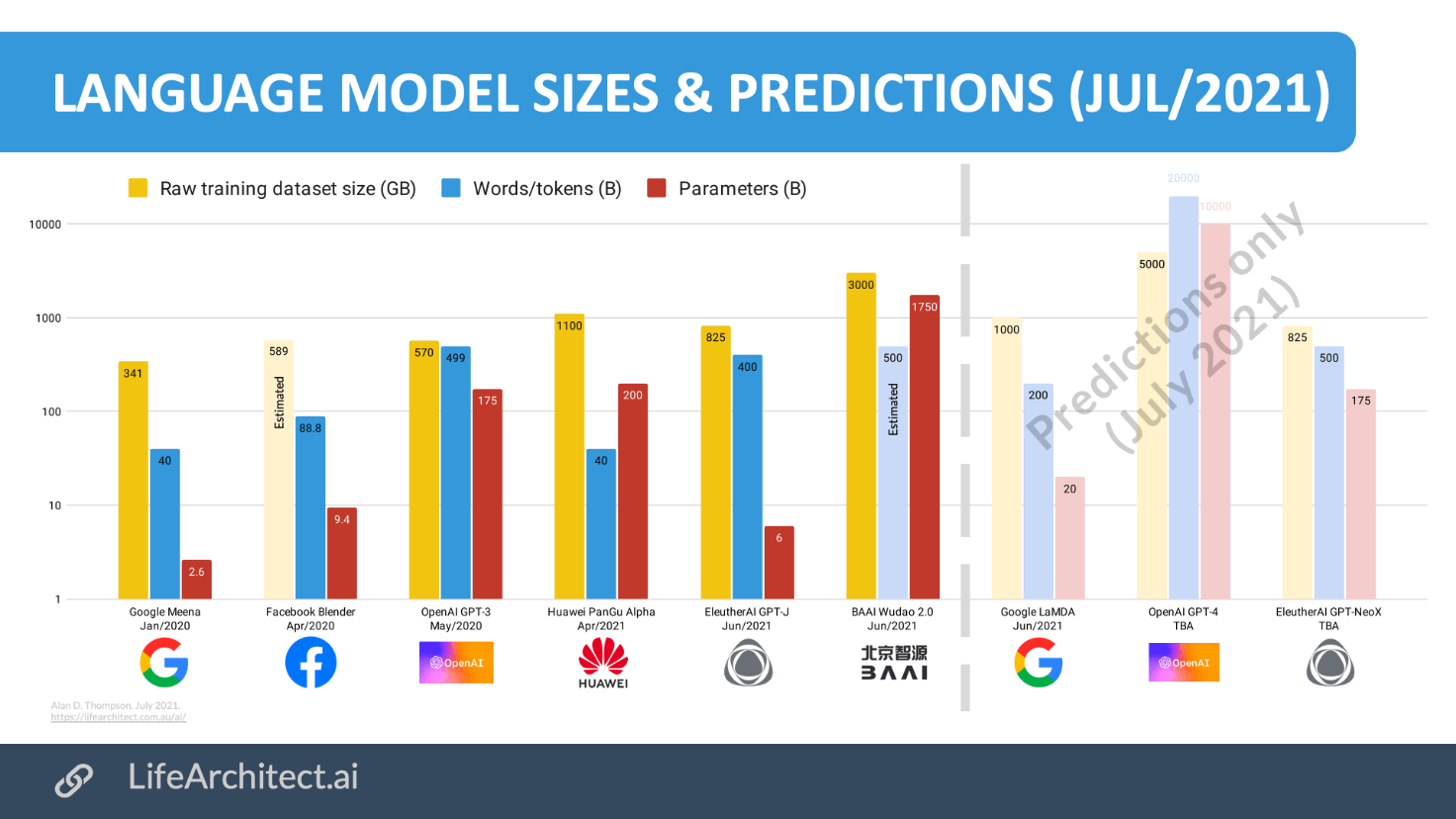
Facebook BlenderBot 2.0
Lanciato a luglio 2021, BlenderBot 2.0 è pre-addestrato, messo a punto su ConvAI2, Empathetic Dialogues e Wizard of Wikipedia (WoW). I due set di dati aggiuntivi sono Multi-Session Chat e Wizard of the Internet (WizInt). Per addestrare la sicurezza, utilizza il set di dati BAD. Infine, in tempo reale, è in grado di aggiungere risultati in tempo reale “generando le proprie query di ricerca, leggendo i risultati e tenendone conto quando si formula una risposta”.
GPT-3
Nel marzo 2021, GPT-3 stava digitando 3,1 milioni di parole al minuto, non-stop, 24×7. Con la disponibilità generale del modello, ci si aspetta che il numero sia molto più alto ora…
Ogni giorno, GPT-3 genera l’equivalente di un’intera biblioteca pubblica statunitense (80.000 libri) di nuovi contenuti.
- al giorno = 4,5 miliardi)
- all’ora = 187,5 milioni)
- al minuto = 3,125 milioni
“Oltre 300 applicazioni utilizzano ora GPT-3 e decine di migliaia di sviluppatori in tutto il mondo stanno costruendo sulla nostra piattaforma. Attualmente generiamo una media di 4,5 miliardi di parole al giorno e continuiamo a scalare il traffico di produzione”. (Blog OpenAI, marzo 2021) . Utilizzando una media di 55mila parole per libro = 81.818 libri al giorno. “Nel 2017, c’erano 9.045 biblioteche pubbliche negli Stati Uniti con un totale di 715 milioni di libri e volumi seriali” (statistiche statunitensi) = 79.049 libri per biblioteca.)
“GitHub afferma che per alcuni linguaggi di programmazione, circa il 30% del codice appena scritto viene suggerito dallo strumento di programmazione AI dell’azienda Copilot”. (Axios, ottobre 2021)
“Il supercomputer sviluppato per OpenAI [a partire da maggio 2020] è un singolo sistema con oltre 285.000 core CPU, 10.000 GPU [supponiamo che le GPU NVIDIA Tesla V100 rilasciate a maggio / 2017, sostituite dalle GPU NVIDIA Ampère A100 a maggio / 2020] e 400 gigabit al secondo di connettività di rete per ciascun server GPU.”
“L’addestramento di GPT-3 con 175 miliardi di parametri richiederebbe circa 288 anni con una singola GPU NVIDIA V100″.
“… il modello è una grande scatola nera, non possiamo dedurre le sue convinzioni”. – Documento InstructGPT, 2022
“Nonostante l’imminente diffusione di modelli di base [linguistici], attualmente non abbiamo una chiara comprensione di come funzionano, quando falliscono e di cosa sono persino capaci a causa delle loro proprietà emergenti”. – Documento di Stanford, 2021.
Si noti che ci sono alcune sfide con la scrittura di libri utilizzando GPT-3 a causa dei limiti del token di output . 2,048 token è circa:
- 1.430 parole (il token è 0,7 parole).
- 82 frasi (la frase è di 17,5 parole).
- 9 paragrafi (il paragrafo è di 150 parole).
- 2,8 pagine di testo (la pagina è di 500 parole).
Esistono modi intelligenti per aumentare questo output alimentando l’ultimo o più importante output a un nuovo prompt.
Giurassico-1 (178B)
Lanciato il 12 agosto 2021.
Il nostro modello è stato addestrato… su token 300B tratti da risorse pubblicamente disponibili, tentando, in parte, di replicare la struttura dei dati di addestramento come riportato in Brown et al. (2020) [il set di dati GPT-3, che è dettagliato nella visualizzazione sopra a LifeArchitect.ai/models].— Il documento Jurassic-1 di AI21
BLOOM di BigScience
Modello multilingue a parametri 176B. Addestrato a marzo-luglio 2022.
BLOOM è l’acronimo di BigScience Language Open-source Open-access multilingue.
Il progetto BigScience per la ricerca aperta è un’iniziativa della durata di un anno (2021-2022) che mira allo studio di modelli e set di dati di grandi dimensioni. L’obiettivo del progetto è quello di ricercare modelli linguistici in un ambiente pubblico al di fuori delle grandi aziende tecnologiche. Il progetto ha 600 ricercatori provenienti da 50 paesi e più di 250 istituzioni. Il progetto BigScience è stato avviato da Thomas Wolf a Hugging Face.
Il set di dati di GPT-2 era solo WebText inglese, che è popolare link Reddit in uscita con più di due upvote. È 40GB.
I set di dati BLOOM contengono 46 lingue con le seguenti proporzioni:—Lingue Niger-Congo (0,035%) : Chi Tumbuka (0,00002%), Kikuyu (0,00004%), Bambara (0,00004%), Akan (0,00007%), Xitsonga (0,00007%), Sesotho (0,00007%), Chi Chewa (0,0001%), Twi (0,0001%), Setswana (0.0002%), Lingala (0.0002%), Northern Sotho (0.0002%), Fon (0.0002%), Kirundi (0.0003%), Wolof (0.0004%), Luganda (0.0004%), Chi Shona (0.001%), Isi Zulu (0.001%), Igbo (0.001%), Xhosa (0.001%), Kinyarwanda (0.003%), Yoruba (0.006%), Swahili (0.02%)
Lingue indiane (2%): Assamese (0,01%), Odia (0,04%), Gujarati (0,04%), Marathi (0,05%), Punjabi (0,05%), Kannada (0,06%), Nepalese (0,07%), Telugu (0,09%), Malayalam (0,1%), Urdu (0,1%), Tamil (0,2%), Bengalese (0,5%), Hindi (0,7%)
Altre lingue: basco (0,2%), indonesiano (1,1%), catalano (1,1%), vietnamita (2,5%), arabo (3,3%), portoghese (5%), spagnolo (10,7%), francese (13,1%), cinese (17,7%), inglese (30,3%)
Linguaggi non umani: Codice [C++, C#, Go, Java, JavaScript, Lua, PHP, Python, Ruby, Rust, Scala, TypeScript] (13%)
Google ha fatto qualcosa di simile con mT5 a giugno 2021 .
Dato che OSCAR proviene da CommonCrawl, potrebbe essere lecito supporre che anche tutte le altre lingue provengano dal CC. Jesse e il team di Allen AI hanno trovato 101 lingue nell’enorme set di dati CommonCrawl.
M6 di Alibaba
Multi-Modality to MultiModality Multitask Mega-transformer (M6). Parametri da 100B a 1T a 10T in meno di un anno!
“M6-Corpus per il pretraining in cinese, che consiste in oltre 1,9 TB di immagine e 292 GB di testo. Il set di dati ha un’ampia copertura su domini, tra cui enciclopedia, risposta alle domande, discussione sul forum, scansione comune, ecc.
Megatron
A causa della complessità di questo trasformatore e dei relativi modelli linguistici, Megatron ha una propria pagina che mostra un riepilogo della timeline, dei laboratori coinvolti e di altri dettagli.
InstructGPT da OpenAI one-pager

*L’acronimo HHH è stato coniato da Anthropic e dimostrato in InstructGPT
Set di domande di esempio WebGPT di OpenAI
Contenuto: Visualizza i dati (fogli Google)
PaLM di Google
PaLM ha parametri 540B. È multilingue.
Contents: View the data (Google sheets)
Luminous di Aleph Alpha
Il modello di testo Luminous è stato annunciato in una conferenza a novembre 2021, in cui il conteggio dei parametri per Luminous (supponendo Luminous-World, in corso ad aprile 2022) è stato dichiarato essere 200B.
Il modello Luminous annunciato utilizza fino a 200 miliardi di parametri ed è considerato altrettanto potente nella parte testuale di GPT, la cui terza versione include fino a 175 miliardi di parametri. A differenza della controparte americana, luminosa può essere combinata con qualsiasi numero di immagini, il modello è disponibile in cinque lingue (tedesco, inglese, francese, italiano, spagnolo) ed è stato addestrato nel contesto culturale europeo.
I modelli di DeepMind
I modelli di DeepMind sono: Gopher, Chinchilla, Flamingo e Gato.

Google Imagen
Google Imagen ha 2B parametri immagine + 1B parametri upscale + 4.6B parametri LLM (codifica testo) tramite T5-XXL. Google Imagen è stato rilasciato dai team di Google Research e Google Brain a Toronto, in Canada.
BriVL di RUC, Cina (giugno 2022)
BriVL sembra essere principalmente una trovata pubblicitaria, per guidare il marketing alla ricerca di Pechino come leader dell’AI.
BriVL un anno fa (marzo 2021)
“La prima versione del nostro modello BriVL ha 1 miliardo di parametri, è pre-addestrato sul set di dati RUC-CAS-WenLan con 30 milioni di coppie immagine-testo … Nel prossimo futuro, il nostro modello BriVL sarà ampliato a 10 miliardi di parametri, che saranno pre-addestrati con 500 milioni di coppie di imagetext.
BriVL oggi (giugno 2022)
“Con 112 GPU NVIDIA A100 in totale, ci vogliono circa 10 giorni per pre-addestrare il nostro modello BriVL sul nostro WSCD di 650 milioni di coppie immagine-testo.” – Nature Communications
CLIP aveva 400 mln di coppie immagine-testo addestrate a 63 mln parametri. DALL-E aveva 250 milioni di coppie e 12B di parametri. BriVL è quindi una discreta evoluzione.



