
Ancora un competitor sulla strada di OpenAI. A poche settimane dalla sfida lanciata dalla società madre di Facebook, Meta AI, che ha pubblicato – con tanto di dettagli di implementazione – il modello linguistico OPT (Open Pretrained Transformer) in diretta competizione con GPT-3 (Generative Pretrained Transformer), Google Brain ha appena rilasciato Imagen, un generatore di immagini da testo che vuole contendere il primato dell’altro modello di OpenAI, DALL-E 2.
Secondo quanto riportato nell’articolo degli sviluppatori di Google Brain, dopo un’attenta valutazione con metriche standard (come il Frechet Inception Distance score sul dataset COCO) e giudizi umani, Imagen batterebbe DALL-E 2 ed altri competitor minori (ad esempio: VQ-GAN+CLIP, Latent Diffusion Models e GLIDE) sia in termini di qualità del campione che di allineamento immagine-testo.
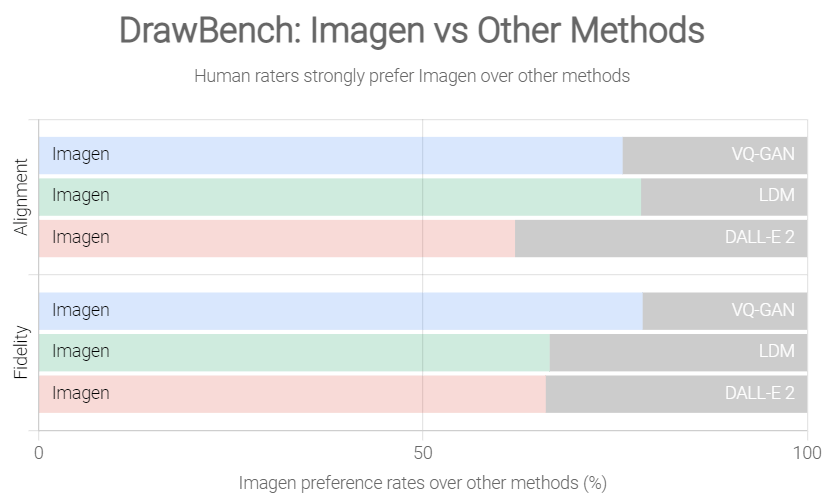
Fonte: Imagen
Indice degli argomenti:
Come funziona Imagen
Ma come funziona Imagen? Il sistema si basa su modelli generativi a diffusione, ispirati al principio termodinamico del non equilibrio, secondo cui se in un ambiente vi è un’alta concentrazione di una sostanza (come un profumo), questa sostanza tenderà a diffondersi per raggiungere un equilibrio omogeneo.
Nello specifico, questa architettura consiste in numerosi strati di neuroni, i quali aggiungono del rumore all’immagine che ricevono in input, rendendola sempre meno chiara. Se gli strati in questo processo di diffusione (chiamato forward diffusion process) fossero infiniti, l’immagine risultante sarebbe rumore puro, ma poiché viene usato un numero limitato di strati, l’immagine risultante è solo un’approssimazione del rumore puro, ancora contenente qualche segnale dell’immagine originale.
Una volta che questi strati sono addestrati, una nuova rete neurale impara l’inverso del processo di diffusione (ovvero il backward diffusion process), ovvero impara il rumore che deve essere rimosso a ogni strato per ottenere un’immagine più chiara.
Grazie a questo sistema di training, le architetture a diffusione hanno il vantaggio di essere molto più realistiche di quelle basate sulle Generative Adversarial Networks (GANs), come il primo DALL-E. D’altro canto, però, perdono in termini di creatività, dove le GANs eccellono (ad esempio nella generazione di disegni e fumetti).

A questo punto, però, il generatore a diffusione inversa deve essere in grado di creare le proprie immagini sulla base delle istruzioni linguistiche fornite dall’utente. Per insegnargli a fare ciò, il generatore viene condizionato – tramite una serie di processi attenzionali – a delle rappresentazioni semantiche generate da un potente modello linguistico, come T5-XXL.
Usare un modello linguistico di questa portata anziché addestrarne uno direttamente sulle descrizioni delle immagini è stata la scelta vincente di Google Brain. Infatti, T5-XXL, avendo conosciuto molta più variazione linguistica di quella presente nelle descrizioni, può generare delle rappresentazioni semantiche molto più raffinate, le quali stimolano il generatore a creare immagini a più alta definizione. Detta con le parole degli autori dell’articolo citato sopra:
La nostra scoperta chiave è che i modelli linguistici generici di grandi dimensioni (ad esempio T5), pre-addestrati su corpora di solo testo, sono sorprendentemente efficaci nella codifica del testo per la sintesi di immagini: l’aumento delle dimensioni del modello linguistico in Imagen aumenta sia la fedeltà del campione che l’allineamento immagine-testo molto più che l’aumento delle dimensioni del modello di diffusione dell’immagine.
Immagini con un elevato realismo
Un piccolo trucco viene poi svolto in fase d’inferenza per accrescere l’impatto del testo durante la generazione. Anziché generare una sola immagine, Imagen ne genera due, una a partire da nessuna descrizione e una a partire dalla descrizione in input. A questo punto, viene calcolata la differenza, così da imparare in che direzione muoversi per trasformare l’immagine senza descrizione in immagine con descrizione. Questa differenza viene poi scalata (ingrandita) significativamente e reintegrata, così da ottenere un’immagine ancora più fedele alla descrizione testuale.
Dalla combinazione del modello a diffusione, del modello linguistico e del trucchetto, Imagen genera immagini con un realismo mai visto prima, nonché una capacità innata di comprensione del linguaggio.
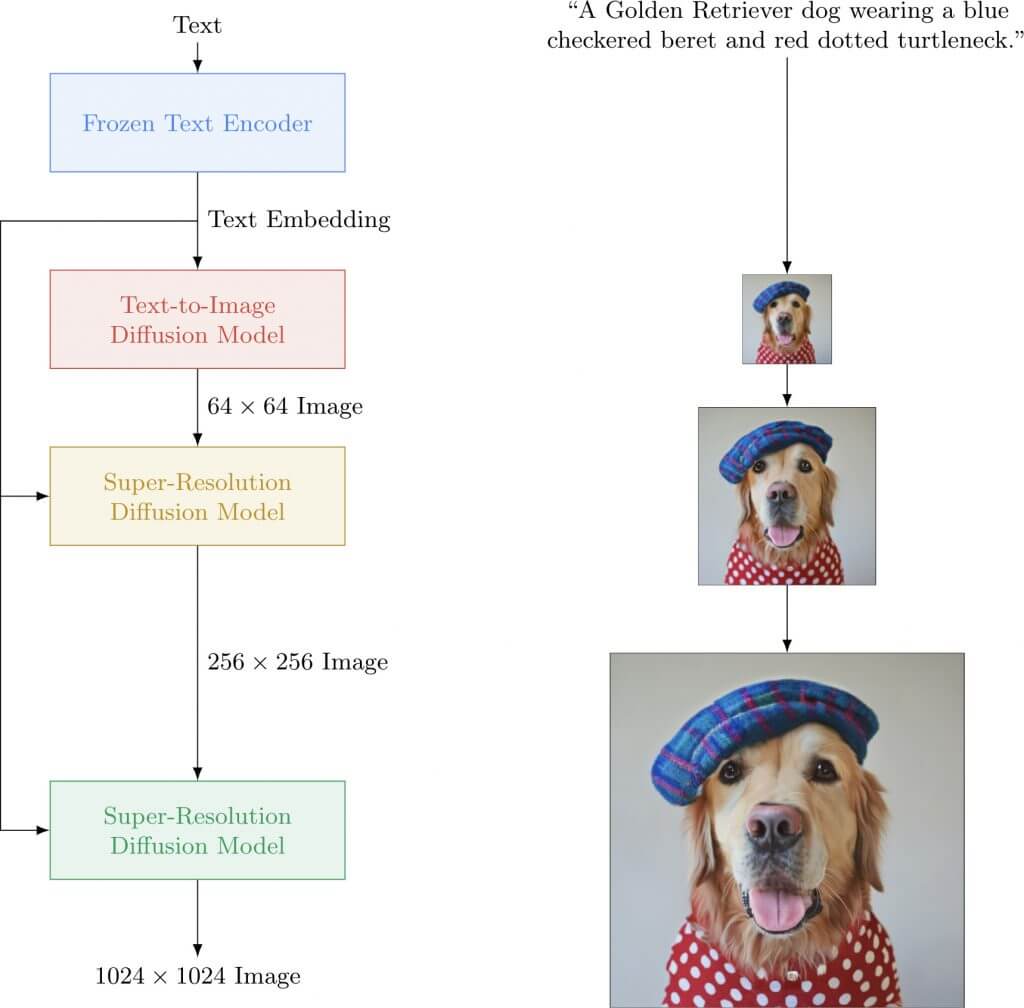
Fonte: Imagen
Non mancano però le limitazioni. Le immagini selezionate per promuovere questi modelli sono state scelte di proposito, dopo averne escluse molte altre. Questo per diversi motivi, sia tecnici che etici. In riferimento ai primi, per esempio, si deve tenere conto che la composizionalità è ancora una delle sfide più grandi per questi modelli, per cui non di rado le immagini vengono corrotte proprio laddove più entità interagiscono. In riferimento ai secondi, alcuni ricercatori hanno evidenziato come le immagini diffuse da Google Brain (ma anche da Open AI per DALL-E) riportino spesso gattini e cagnolini in contesti divertenti, ma raramente riportino persone. La motivazione dietro a tale scelta è che non solo i giudizi umani sono generalmente più severi quando i soggetti delle immagini sono persone, ma anche che questi modelli generativi imparano pregiudizi e riferimenti tossici durante l’addestramento e li continuano a perpetuare nella generazione di immagini.
Ed è proprio citando questi problemi etici che Google Brain ha deciso di non rilasciare il modello, menzionando anche il rischio che potesse essere utilizzato per scopi poco nobili. Crediamo sarebbe stato meglio che il modello fosse stato rilasciato alla comunità scientifica, come ha coraggiosamente fatto Meta AI con OPT. Sarebbero stati proprio gli stessi ricercatori a lavorare per rendere il modello non solo più potente ma anche più equo e gentile.



