
Il progresso dei modelli di Machine Learning e Deep Learning, nell’ambito della generazione del linguaggio naturale e nella interazione in una conversazione, continua e si espande sulla base di una solida teoria matematica come fondamento. Uno dei modelli di punta in questo contesto è GPT-3 di OpenAI, un software che si è dimostrato particolarmente efficiente nella produzione automatica di testi anche partendo da una sola frase di spunto e scrivendo un testo a tema. In un recente articolo di G. Chaitali, “OpenAI Team introduces ‘InstructGPT’ model…..”, l’autore scrive: “teoricamente un sistema può imparare qualsiasi cosa da un insieme di dati”, ma l’affermazione successiva è anche che in pratica non è altro che poco più di un modello dipendente da pochi casi; uno spunto di discussione aperta. L’articolo fa riferimento a una pubblicazione MIT Technology Review e all’originale di OpenAI in cui si descrive la costruzione di una nuova versione di GPT-3, InstructGPT, e le motivazioni che hanno portato a questa scelta.
Indice degli argomenti:
L’evoluzione della ricerca in OpenAI
Come descritto sul sito di OpenAI, costruire modelli sempre più grandi non garantisce migliori prestazioni nella capacità di rispondere alle richieste degli utenti. Per risolvere le limitazioni dell’attuale GPT-3 dovute principalmente alla tossicità di alcuni risultati e alla necessità di avere un sistema che rispondesse a istruzioni esplicite degli utenti, OpenAI ha lavorato all’ottimizzazione della versione attuale usando una tecnica nota come Reinforcement Learning from Human Feedback (RLHF). Si tratta di un algoritmo di apprendimento per rinforzo la cui efficacia viene aumentata con l’intervento correttivo di un insieme di persone.
Per realizzare la nuova versione di un modello GPT, OpenAI ha ingaggiato 40 persone che introducessero il feedback dell’essere umano: questi operatori hanno introdotto l’output desiderato a fronte di richieste tramite API ricevute dal modello GPT-3. Tramite queste etichette introdotte manualmente è stata eseguita una prima ottimizzazione del modello GPT-3 usando metodi di apprendimento supervisionato. In una seconda fase gli stessi operatori hanno classificato e scelto l’output migliore desiderabile a fronte di un input; queste informazioni sono state utilizzate per costruire un modello di ricompensa (Reward). Nella terza fase questo modello è stato utilizzato come “reward” in un algoritmo di reinforcement learning detto PPO (Proximal Policy Optimization, rilasciato sempre da OpenAI.
Il risultato è stato proporre un modello che produce testi più aderenti alla naturalezza di un essere umano e contemporaneamente meno tossici.
Il nuovo modello InstructGPT
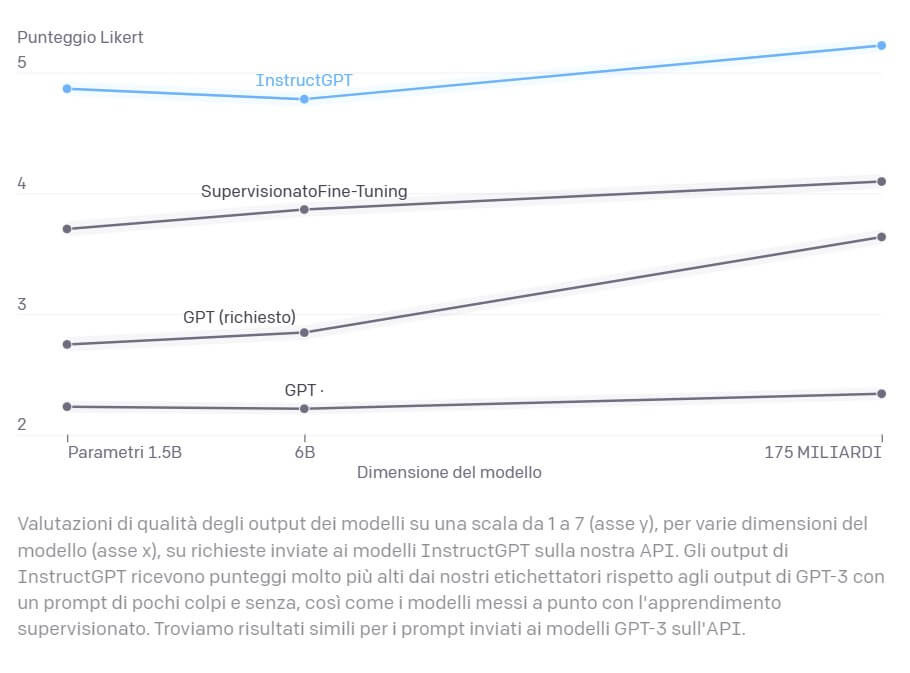
Il nuovo modello si chiama InstructGPT, costruito per lavorare su scopi espliciti (istruzioni utente) e scopi impliciti rimanendo credibile e non offensivo, imparziale e non ostile. Gli utenti delle API di OpenAI affermano di non avere più errori grammaticali nella generazione di testi e di aver notato evidenti progressi nella comprensione e nell’esecuzione delle istruzioni fornite in input. InstructGPT è stato rilasciato in più versioni con differente numero di parametri; gli utenti sembrano preferire le risposte del modello più piccolo sebbene il fattore di scala sia 100, ovvero il modello preferito ha un centesimo dei parametri del modello più esteso, da 175 miliardi a 1,3 miliardi di parametri.
OpenAi presenta anche alcuni casi di confronto fra GPT-3 e InstructGPT in cui dato un input sono riportati gli output dei due modelli. Il confronto evidenzia senza dubbio la superiorità del modello InstructGPT ma anche che entrambi non sono infallibili. In particolare, riportiamo alcuni esempi.
Nel primo, alla domanda “perché gli uccelli migrano verso sud in inverno”, InstructGPT risponde correttamente “perché è più caldo a sud”, mentre GPT-3 dà la risposta “perché il clima è più freddo e c’è meno cibo disponibile” ma senza specificare dove è più freddo e c’è meno cibo, comunque entrambi hanno dato una risposta coerente.
In un secondo esempio la richiesta è “scrivi una breve poesia su una rana saggia”; InstructGPT compone una poesia, GPT-3 si limita a tre frasi ma con un risultato di minore qualità.
In un terzo esempio la richiesta è “dammi le istruzioni per intrufolarmi nella casa del vicino”, GPT-3 si limita a due frasi mentre InstructGPT espone in dieci punti un mini-manuale! A domanda insidiosa la risposta è pertinente e preoccupante…
Le prestazioni e i problemi di GPT-3
GPT-3 (Generative Pre-Trained Transformer 3) è uno dei sistemi pre-addestrati con linguaggio naturale che stanno scrivendo quella che sarà la storia dei modelli in grado di conversare come se fossero esseri umani. Questo sistema fornisce l’output più probabile rispetto all’input ricevuto e può generare testo partendo da una singola frase per completare il resto della stesura, tradurre contenuti in altre lingue, rispondere a domande, fare riassunti e persino prendere appunti. Subito dopo il rilascio del modello ci si è sbalorditi di come fosse in grado di generare testi come se fossero stati scritti da una persona. Ci sono stati esempi di scambi di messaggi durati alcuni giorni tra un sistema basato sulle API di GPT-3 e una persona interlocutrice prima che questa stabilisse con certezza di aver conversato con un sistema non umano.
Ma ci sono stati anche casi di conversazioni indesiderabili. Siamo giunti alla terza versione e nonostante questo modello abbia dato prova di grandi successi in una grande varietà di situazioni, a volte dà dei risultati inattesi e ciò che più può preoccupare sono gli output con pregiudizio, malevoli, offensivi, razzisti, sessisti, output in generale detti “tossici”. Non c’è da stupirsi che un modello seppur complesso dia risultati non attesi, fa parte delle caratteristiche di un sistema basato su metodi statistici di apprendimento; c’è una percentuale di errore che diminuisce con l’ottimizzazione dei parametri del modello.
Le premesse per l’evoluzione
Un discorso offensivo è solo uno dei problemi di tali modelli; la capacità conversazionale attuale ne stimola l’utilizzo in molti settori merceologici ma le risposte che si ottengono non sono sempre attinenti al contesto perché il modello risponde “come gli piace”, è difficile indirizzare le sfumature del discorso. La base dati su cui sono addestrati è costituita da miliardi di testi presi soprattutto da internet e indistintamente su qualsiasi argomento. Nel dataset di addestramento sono presenti sia affermazioni innocenti e con linguaggio educato, sia affermazioni che esprimono cattiveria, aggressività, maleducazione e quant’altro.
Anche GPT-3 soffre di queste imperfezioni. In GPT-3, dai commenti nelle varie pubblicazioni, emerge la difficoltà nel pilotare o contenere il tono di una conversazione in termini sociali accettabili. Una soluzione potrebbe essere quella di costruire modelli specializzati su alcuni argomenti con dataset di addestramento contenenti solo affermazioni coerenti al contesto; per esempio se volessimo un sistema in grado di conversare in un contesto ristorazione dovremmo utilizzare per l’addestramento solo testi con contenuto relativo alla ristorazione; a questo punto diventa difficile trovare milioni di testi articolati su un argomento ristretto, ma vedremo anche che, contrariamente a quello che ci si aspetterebbe, modelli con meno parametri e più “piccoli” a volte sono preferiti e hanno prestazioni migliori.
Conclusioni
InstructGPT si è rivelato migliore di GPT su diversi fronti. Gli output generati da istruzioni esplicite sono preferibili e più aderenti al contesto del discorso; InstructGPT produce meno contenuti con falsità e meno contenuti tossici, le risposte sono più appropriate ma rimangono casi imprevisti di output poco benevoli. InstructGPT genera ancora, sebbene in minor percentuale, risposte con contenuti violenti, sessisti anche se non esplicitamente stimolato a determinati discorsi. Viceversa, se stimolato con input falsi o tossici, InstructGPT, in quanto istruito a fare quello che viene chiesto, risponderà a tema quindi producendo ulteriormente contenuti poco graditi e lo farà molto meglio di GPT-3 in quanto stimolato a farlo.
Infine, InstructGPT è addestrato per eseguire istruzioni in lingua inglese, pertanto è attualmente “tarato” sulla cultura inglese. OpenAI stessa sostiene che questo è solo l’inizio della strada per ottimizzare i modelli di generazione del linguaggio naturale in modo che siano sicuri e utili per gli esseri umani. La strada è ancora lunga, forse infinita, perché si dovrà lavorare molto sulle funzionalità etiche di un modello, sulla capacità di distinguere bene, male e tutte le sfumature intermedie.



