
Gato è un nuovo sistema AI multimodale di DeepMind in grado di svolgere centinaia di task diversi usando sempre la stessa rete neurale. C’è chi pensa che la strada verso l’intelligenza artificiale di livello umano sia ormai tracciata, adesso sarebbe solo una questione di aumentare le risorse computazionali, chi invece frena perché mancherebbero ancora molti requisiti. La straordinaria capacità di gestire task molto diversi fra loro rende comunque Gato un sistema AI diverso dagli altri, che se da una parte non è ancora quell’intelligenza artificiale generale che tutti si aspettano, dall’altra è comunque un sistema innovativo per il modo in cui riesce a far elaborare dati molto diversi dalla stessa architettura di deep learning.
Indice degli argomenti:
AI stretta, AI generale e AI multimodale
Finora una delle distinzioni principali nel complesso mondo dell’intelligenza artificiale era la differenza fra AI debole, anche detta AI “stretta”, e AI forte, anche detta AI “generale”. Si trattava di un modo abbastanza semplice per dirimere subito la questione delle macchine pensanti. L’AI stretta è quel tipo di intelligenza artificiale che svolge solo un compito, come ad esempio programmare un percorso, fornire risultati di ricerca rilevanti o intrattenere una conversazione scritta. L’AI generale, invece, è quel genere di intelligenza artificiale che vediamo nei film, che ragiona come un essere umano, che esegue molti compiti contemporaneamente creando fra loro utili sinergie. L’acronimo per queste macchine simili all’essere umano è AGI, Artificial General Intelligence. Per la maggior parte dei ricercatori una chimera, in teoria possibile ma che non raggiungeremo presto.
Tuttavia, questa distinzione oggi scricchiola e inizia a essere sempre meno semplice da spiegare. Negli ultimi anni, infatti, la ricerca si è spinta verso la creazione di modelli di intelligenza artificiale sempre più generalisti, senza però sfociare nella scoperta dell’AGI. Si sta creando, dunque, una specie di terra di mezzo, dove troviamo modelli AI che riescono a svolgere numerosi compiti di diversa natura, tanto da non poter più essere descritti come AI “stretta”, ma che allo stesso tempo non mostrano quell’intelligenza causale né quella presa di coscienza che per molti esperti dovrebbero essere insite in una AGI.
Possiamo chiamare questo tipo di intelligenza artificiale “generalista” o forse più correttamente “multimodale”, poiché vi sono diversi modi per interagire con essa. Per fare un esempio, un sistema AI multimodale sarebbe in grado di reperire le previsioni del tempo per la nostra zona (ricerca e selezione del risultato migliore), comunicarci che oggi pioverà (elaborazione del linguaggio naturale e sintesi vocale) e verificare se stiamo uscendo con o senza l’ombrello (visione artificiale). Inoltre, una delle caratteristiche principali di un sistema multimodale è quello di “ingerire” dati di tipo diverso – ad esempio immagini e testo – sapendo trarre informazioni utili da entrambi. Come risultato ci sembrerà di avere a che fare con una vera intelligenza, in realtà sono solo molteplici modelli AI messi “in batteria” e in sinergia fra loro.
Lo zoo di DeepMind
Per quanto concerne la ricerca verso l’AI multimodale, nelle ultime settimane l’azienda londinese DeepMind, che – lo ricordiamo – fa parte della galassia di Google, ha rilasciato due sistemi AI che hanno fatto molto parlare di sé. Il primo si chiama Flamingo, ed è un modello in grado di risolvere “task multimodali”, ovvero compiti che possono avere informazioni in entrata veicolate attraverso diverse modalità, come immagini, video e testo, anche in combinazione fra loro. Flamingo è un modello di linguaggio visivo (VLM, visual language model) che può gestire informazioni di classificazione, gestione delle didascalie, risposte a domande basate sulle immagini, il tutto fornendo solo pochi campioni di input/output (il cosiddetto “few-shot learning”).
Scopo del modello è quello di “comprendere” la situazione di un’immagine o di un video, descrivendola correttamente con il suo sistema linguistico e rispondendo correttamente a domande relative a quello che “vede”.
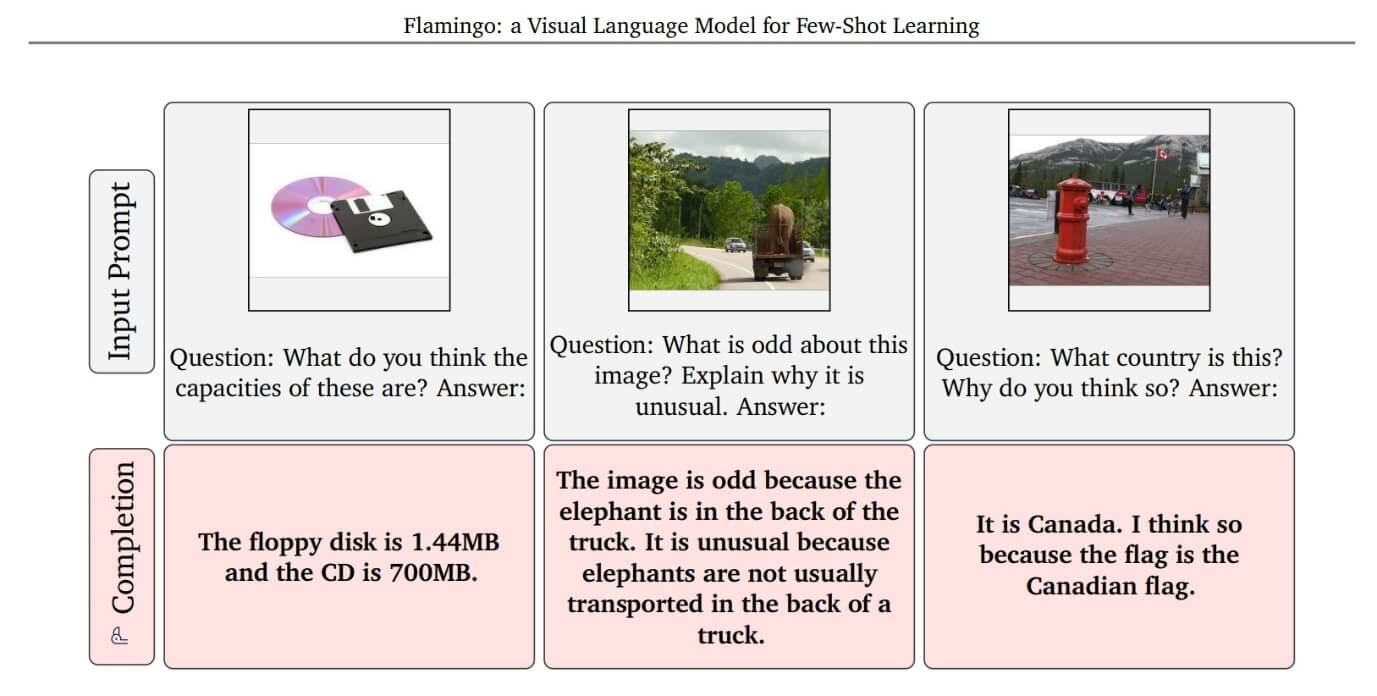
Figura 1 – Esempio di elaborazione e comprensione delle immagini da parte di Flamingo. Da “Flamingo: a Visual Language Model for Few-Shot Learning” (2022). Fonte: DeepMind
Anche l’altro sistema che andremo ad analizzare porta il nome di un animale, in questo caso “Gato”, e rispetto a Flamingo (nonché rispetto a tutti gli altri modelli AI finora realizzati) spinge i confini dell’intelligenza artificiale multimodale in un territorio fino a oggi inesplorato.
Contrariamente ad altri sistemi multimodali, Gato non è composto da una serie di modelli che lavorano in cooperazione fra loro. Gato, invece, sfrutta una unica rete neurale basata sull’architettura Transformer, che con gli stessi parametri è in grado di svolgere ben 604 compiti di diversa natura. Gato può osservare e descrivere un’immagine, navigare un ambiente tridimensionale, battere gli esseri umani a un videogioco Atari, muovere un braccio robotico, dialogare con un utente e svolgere tanti altri compiti tutti diversi fra loro. Centinaia di task differenti, attraverso dimensioni molto diverse fra loro, come il linguaggio, la visione, il controllo, il tutto gestito da un unico sistema AI formato da una sola rete neurale, addirittura senza dover modificare il set iniziale di pesi fra neuroni artificiali quando si passa da un compito all’altro.
Per sottolineare la particolarità dell’architettura minimalista, e di conseguenza della sorprendente capacità generalista di Gato, sui social è circolata fin dai primi giorni un’immagine che – con un paragone fra l’architettura di AlphaStar (un sistema di reinforcement learning in grado di giocare Starcraft II a livelli superumani) e Gato – spiega meglio di qualsiasi commento in quale direzione si sta muovendo la ricerca.
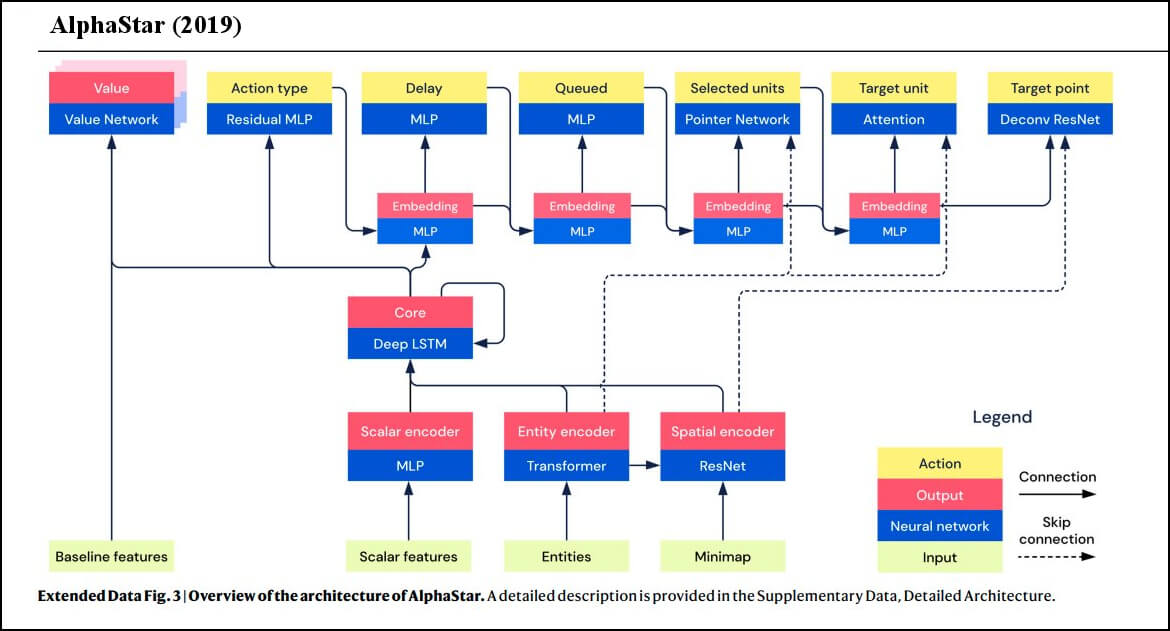
Figura 2 – AlphaStar (2019) e Gato (2022), architetture a confronto
Come si vede dall’immagine, Gato non ha necessità di usare più modelli che dialogano fra loro. Uno degli aspetti che ha sbalordito molti ricercatori è il fatto che Gato riesce a svolgere tutti i suoi compiti usando un’unica rete neurale, un solo, grande modello Transformer in grado di interpretare e gestire token di diversa natura, restituendo di volta in volta previsioni più che plausibili.
Gato, tokenizzare tutto
Il “segreto” di questa architettura è l’aver trovato un modo per “tokenizzare” qualsiasi tipo di dato affinché sia elaborato dalla stessa rete neurale. Un token è un modo per rappresentare un dato in formato standardizzato, a seconda della natura di questo dato. Ad esempio, un’immagine viene prima trasformata in sequenze 16×16, poi ogni pixel viene normalizzato e diviso. Così trasformato, il dato diventa un token pronto da gestire. Ogni tipologia di dato ha un suo formato di tokenizzazione: un testo viene trasformato secondo un formato specifico, così come i dati discreti e quelli continui, dove ogni tipologia ha un suo formato di token. Tutti i token così realizzati vengono poi inviati al modello Transformer che li elabora, trattandoli allo stesso modo.
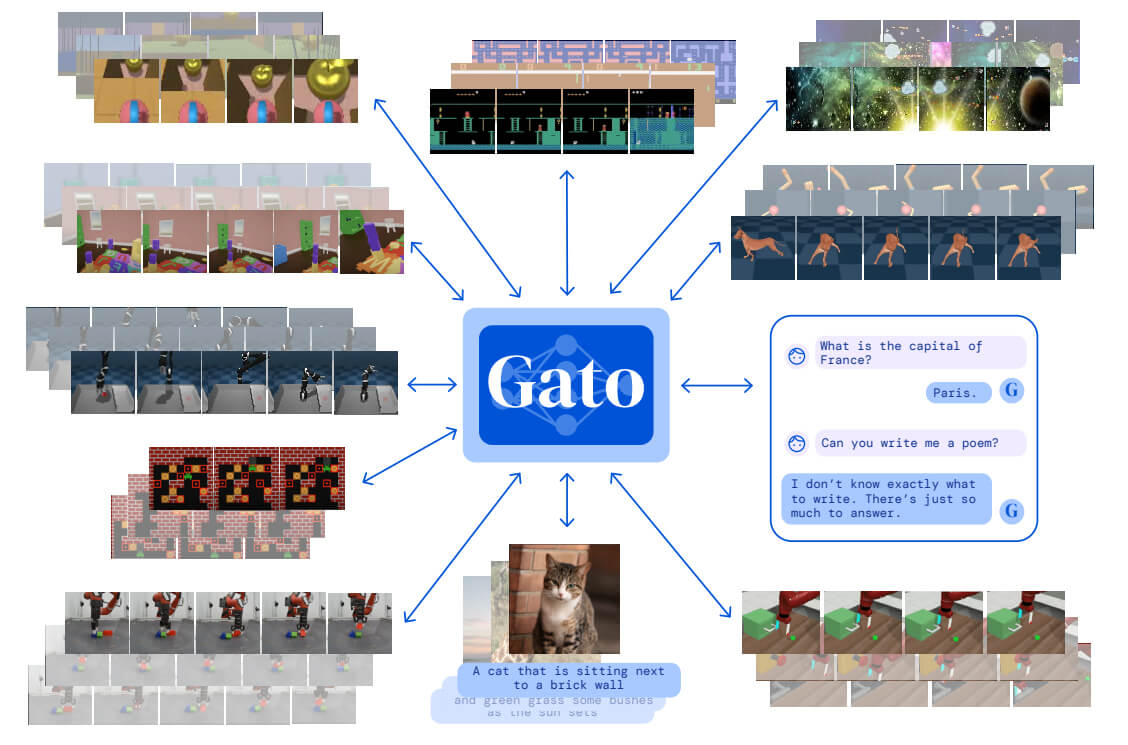
Figura 3 – Gato prende come input dati di diversa natura, tokenizzati secondo una struttura specifica, quindi restituisce token che possono essere tradotti nei dati originari. Così facendo riesce a risolvere centinaia di task diversi. Fonte: DeepMind
Una prima lezione che si può imparare da questo nuovo sistema AI è che problemi di ricerca apparentemente molto differenti fra loro, come il linguaggio, la robotica o il gaming, non sono poi così diversi quando li si può rappresentare attraverso dei token. Gato ha dimostrato che un problema che richiede il movimento di un attuatore robotico, oppure un problema che richiede l’interpretazione dei pixel di un’immagine o di un video, possono essere risolti allo stesso modo in cui si risolvono i problemi di linguaggio, ovvero con l’elaborazione di una sequenza di token e la previsione dei token successivi. Gato, per farla breve, ha “appiattito” la modalità con cui è possibile risolvere problemi di diversa natura, passando prima tutto attraverso una procedura di tokenizzazione, quindi elaborando i vari token in sequenza, prevedendo quali token dovranno essere prodotti in relazione a quelli elaborati, infine trasformando i token prodotti dal sistema nel formato dati originario: testo per i testi, immagine per le immagini, movimento robotico per i movimenti robotici, eccetera.
Gato: connettivismo è intelligenza?
Gato non sempre è il migliore modello AI per un dato compito. Il controllo di un robot Sawyer (si tratta di un robot formato da un braccio con molte “articolazioni”) è di buon livello, ma la creazione di didascalie è solo mediocre, mentre la gestione di alcuni giochi Atari è inferiore rispetto a quella di altri modelli AI dedicati. DeepMind afferma che su 450 task (rispetto ai 604 sui quali è stato addestrato) Gato è più preciso degli esperti umani “più della metà delle volte”. Un modo un po’ contorto per dire che sui complessivi 604 task, almeno 154 restituiscono risultati decisamente scarsi, mentre nei restanti 450 una buona metà delle volte Gato si comporta meglio di un esperto umano, ma un’altra metà delle volte si comporta peggio.
Ma Gato non è stato realizzato con l’obiettivo di eccellere in tutti i task, bensì con lo scopo di poterne gestire il più possibile. Tanto l’idea è quella che all’aumentare della grandezza del modello – Gato oggi ha “solo” 1,18 miliardi di parametri, nulla in confronto ai 175 miliardi di GPT-3 – miglioreranno i risultati. Questo trend nella ricerca è già evidente: a DeepMind hanno realizzato tre versioni di Gato, una con 79 milioni di parametri, una con 364 milioni e l’ultima a 1,18 miliardi di parametri. I risultati dei task migliorano man mano che aumenta la grandezza del modello, un trend perfettamente in linea con quello che già conosciamo dei modelli di linguaggio, e che ha portato il direttore della ricerca di DeepMind, Nando de Freitas, a dichiarare “game over: ora è tutto una questione di scala”.
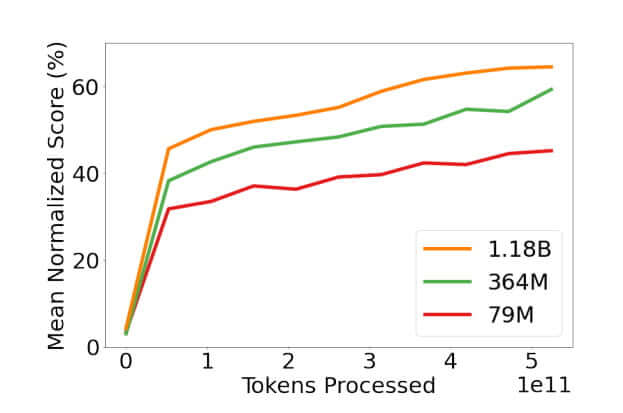
Figura 4 – Più è grande la rete neurale (espressa in parametri), più i risultati migliorano. Fonte: DeepMind
La dichiarazione ovviamente ha riacceso l’annosa battaglia fra i connettivisti puri, ovvero quei ricercatori che ritengono che per raggiungere o almeno emulare l’intelligenza abbiamo solo bisogno di reti neurali sufficientemente grandi, e i proponenti di soluzioni neuro-simboliche, che rifiutano l’idea che per raggiungere l’intelligenza bastino modelli AI “più grandi”, optando invece per un bilanciamento fra reti neurali e informazioni fornite dall’alto. I primi esultano perché un sistema come Gato, che offre soluzioni a centinaia di attività diverse usando sempre la stessa rete neurale, dimostra come l’intelligenza possa essere replicata da una grande rete di connessioni organizzate con il metodo giusto (in questo caso, un Transformer e un sistema di tokenizzazione), mentre i secondi non hanno perso tempo a evidenziare e sottolineare tutti gli errori e gli sbagli di Gato, puntando il dito contro le numerose limitazioni di un sistema basato solo su una grande rete neurale.
C’è poi la questione della presunta mancanza di sinergia fra task diversi. Jack Hessel, ricercatore presso l’Istituto Allen per l’AI, commentando la notizia di Gato su TechCunch, fa notare che la vera questione non riguarda tanto la capacità di far svolgere task diversi a un singolo sistema AI, bensì l’abilità di tale sistema all’apprendimento multitask, il che significa migliorare l’accuratezza dei risultati sfruttando le sinergie fra più fonti di dati. Se ricevere dati con diverse modalità non aiuta il sistema multimodale ad aumentare la sua accuratezza, allora potremmo definire i risultati tutto fuorché entusiasmanti. Sarebbe un discorso ben diverso, invece, se l’elaborazione di diverse fonti di dati (audio, video, testi, immagini, ecc) contribuisse ad aumentare l’accuratezza in maniera incrociata. Ad esempio, se elaborando sia l’immagine di un gatto, sia un file audio dove si sente miagolare potesse aumentare la precisione di entrambi i task di riconoscimento (video e audio), potremmo dire che il modello presenta un apprendimento multitask. Il file audio contenente il miagolio rafforzerebbe l’accuratezza del riconoscimento dell’immagine, e a sua volta l’immagine del gatto rafforzerebbe l’accuratezza del riconoscimento audio. Un aiuto incrociato, insomma, fra diversi task. Questo modo di apprendere si avvicinerebbe all’intelligenza umana, poiché in genere riusciamo a imparare meglio quando per uno stesso compito assorbiamo dati di diverso tipo.
La strada verso la generalizzazione
I risultati di queste settimane sono frutto di un impegno che DeepMind sta portando avanti da molti anni. Non dimentichiamo che l’obiettivo dell’azienda è quello di “risolvere il problema dell’intelligenza”, sviluppando sistemi sempre più generali e capaci di affrontare una vasta gamma di problemi diversi. È questo che l’azienda chiama Artificial general intelligence, ed è lì che vogliono arrivare. L’anno scorso un passo in questa direzione era stato fatto con Perceiver, un modello multimodale basato sull’architettura Transformer in grado di gestire diversi tipi di input, come immagini, testo, video, suoni, dati 3D. Gli stessi creatori di Gato pensano che Perceiver possa essere utile per espandere ulteriormente il numero di modalità di futuri sistemi generali.
Più recentemente Google, che – lo ricordiamo – è l’azienda “sorella” di DeepMind, ha sviluppato Pathways, un’architettura AI di nuova generazione che consente di addestrare modelli in grado di svolgere “mille o milioni di attività”, come scriveva Jeff Dean, uno dei principali ricercatori di Google, già a ottobre. “Pathways – continuava Dean – potrebbe consentire modelli multimodali che comprendono contemporaneamente la visione, l’audio e la comprensione del linguaggio. In questo modo, sia che il modello stia elaborando la parola ‘leopardo’, il suono di qualcuno che dice ‘leopardo’ o un video di un leopardo che corre, viene attivata internamente la stessa risposta: il concetto di leopardo. Il risultato è un modello più perspicace e meno incline a errori e bias.”
Le sfide di sicurezza dei modelli multimodali
E proprio errori e bias sono fra i pericoli ancora inesplorati di questi nuovi modelli generali. Va anche bene immaginare un modello che sia in grado di svolgere milioni di compiti, ma come assicurarsi che la stessa rete neurale che vince ai videogiochi, poi non muova un braccio robotico con la stessa disinvoltura o aggressività con cui batte gli umani a Starcraft II? Come fare affinché le regole e i comportamenti imparati in un dato dominio, poi non sconfinino in altri domini dove risulterebbero erronei o addirittura dannosi?
Inoltre, poiché Gato è basato concettualmente sui grandi modelli linguistici (LLM, large language model), come ad esempio il già citato GPT-3, questo vuol dire che può assorbire e riproporre bias e pregiudizi così come già fanno i LLM. Come si fa a esser sicuri che un pregiudizio razziale acquisito da milioni di contenuti razzisti letti in rete, poi non si ripercuota in altri domini dove opera il sistema? Prima affermavamo che la commistione di task e la contaminazione di insegnamenti da un dominio all’altro può essere sintomo di intelligenza e per molti versi una caratteristica auspicabile. Eppure, questo aprirebbe le porte a comportamenti inaspettati, dove ricercare le motivazioni dell’errore potrebbe essere infinitamente più complicato, rendendo la black box di questi sistemi di deep learning ancora più opaca e inaccessibile.



