
Microsoft Germany annuncia il rilascio della nuova versione del noto AI chatbot, basato sul nuovo modello di OpenAI GPT-4, successore di GPT-3.5, il modello alla base della versione precedente del servizio ChatGPT. La novità dell’ultimo modello consiste nel fatto di essere multimodale, cioè in grado di trattare dati di natura diversa, nello specifico testo e immagini o video. Questa nuova frontiera per i modelli conversazionali può risultare inaspettata ai non addetti ai lavori e a maggior parte della stampa, soprattutto non specializzata, ma di certo non ha colto di sorpresa i professionisti che hanno a che fare quotidianamente con applicazioni di AI in casi d’uso reali (solamente la data di rilascio di Microsoft/OpenAI ha sorpreso un po’, in quanto avvenuta con circa un paio di mesi di anticipo rispetto a quanto ci si aspettava). Forti segnali che indicavano come questa strada fosse ormai tracciata si erano già visti nelle settimane successive all’apertura del servizio ChatGPT. Riassumiamo le tappe fondamentali.
Indice degli argomenti:
La discesa in campo di AWS
Successivamente all’apertura al pubblico di ChatGPT, mentre altri competitor (quali ad esempio Meta e Google) si affannavano a inseguire Microsoft/OpenAI accelerando il rilascio dei propri LLM (Large Language Model) antagonisti di GPT-3.5, Amazon Science, l’area di ricerca del gruppo di Jeff Bezos, pubblicava un paper dal titolo “Multimodal Chain-of-Thought Reasoning in Language Models” e rilasciava come Open Source (dataset di training, codice sorgente e modelli già addestrati, dietro licenza Apache 2.0) la relativa implementazione di modello conversazionale multimodale denominato Multimodal-CoT.
Per la prima volta non solo testo coinvolto in casi di LLM, ma una combinazione di testo e immagini. A differenza di tutti gli altri LLM (inclusa la famiglia GPT), nella proposta di Amazon Science il processo che porta alla generazione del testo finale consiste in due fasi. Gli input al modello sono costituiti da un testo e immagini. Durante la prima fase, denominata Rationale Generation, il modello prende in esame l’immagine (o le immagini) in ingresso e genera una spiegazione logica di cosa è raffigurato nella/e immagine/i. Durante la seconda fase, denominata Answer Inference, partendo dal testo di input e dall’output generato durante la prima fase, il modello produce il risultato finale.

Questa ricerca si è focalizzata principalmente su attività di domanda/risposta presentando al modello immagini e una domanda relativa ad esse. Durante la fase di ricerca, paragonando questa architettura con GPT-3.5, è stato dimostrato che la ragione principale del miglioramento di prestazioni di circa il 16 % rispetto al rivale è proprio dovuta alla scelta di separare il processo di generazione in due fasi distinte, in quanto esso permette di correggere gran parte degli errori di allucinazione che affligge LLM che utilizzano solo testo.
A mio parere questo di Amazon Research è un approccio che merita di essere esplorato e per cui sarebbe interessante partire con l’applicazione pratica in alcuni casi d’uso al di fuori dell’ambito accademico.
Microsoft inizia a svelare le proprie carte
Questione di pochi gior

ni ed ecco che anche i ricercatori Microsoft (stavolta senza coinvolgimento di OpenAI) pubblicano il loro primo paper in ambito LLM multimodale, dal titolo “Language is not all you need: aligning perception with language models”. In questo paper viene introdotto il modello Kosmos-1, il cui apprendimento è stato effettuato utilizzando esclusivamente dati presi dal web, disponibili in due voluminosi dataset pubblici. Questo modello è stato addestrato per analizzare immagini e assolvere quindi alcuni task quali la risoluzione di puzzle visuali, riconoscimento di testi all’interno di immagini, superare test di intelligenza e comprendere istruzioni espresse in linguaggio naturale. Da questa ricerca si evince che Microsoft avesse già in scaletta l’implementazione di modelli conversazionali multimodali, prima del rilascio di OpenAI GPT 3.5, e che quest’ultimo tipo di LLM fosse solo una tappa intermedia nella loro roadmap.
Ad oggi, nessun codice sorgente o modello di Kosmos-1 è stato reso disponibile a sviluppatori o altri ricercatori, come invece anticipato nel paper Microsoft.

La proposta di NVIDIA
Un altro partecipante si è quindi aggiunto alla competizione: NVIDIA, azienda tecnologica statunitense leader nel mercato di produzione di processori grafici, ha condiviso i risultati della propria ricerca in ambito LLM multimodali, presentando un approccio diverso in termini implementativi. Gli LLM esistenti hanno dimostrato una straordinaria capacità di generalizzazione in un ampio ventaglio di attività, ma a un costo molto alto sia in termini di risorse computazionali necessarie sia per l’apprendimento che per l’utilizzo finale che in termini di volumi di dati necessari.
Risulta quindi evidente che, passando a uno scenario multimodale, l’impiego di immagini e video oltre che testo per l’addestramento di un modello monolitico e ancora più massiccio non può non far lievitare i costi ulteriormente. Per prevenire questi problemi, i ricercatori di NVIDIA propongono un approccio alternativo, nel quale l’apprendimento viene eseguito per una serie di reti neurali, ognuna specializzata in un dato dominio, denominate “esperti”, in maniera indipendente (quindi utilizzando dataset e architetture specifiche per ogni singolo dominio). In questo modo la fase di apprendimento risulta molto più efficiente, se ne riducono leggermente i costi, ma soprattutto si ha il vantaggio di poter integrare una serie di skill maggiore rispetto al caso di un’architettura formata da un modello monolitico.
Il modello da essi proposto prende il nome di Prismer (dal termine inglese prism, in italiano prisma), a sottolineare l’analogia di tale architettura con il prisma ottico, che è in grado di scindere la luce bianca nei singoli colori che la compongono: infatti Prismer è in grado di scindere una singola attività cognitiva nelle diverse attività specifiche per diversi sotto-domini che la compongono, prima di fornire il risultato finale.
Codice sorgente, modelli e dataset di Prismer sono stati rilasciati dietro licenza NVIDIA Source Code.
Il rilascio di GPT-4
Si è infine giunti al rilascio ufficiale di GPT-4 da parte di OpenAI e la sua integrazione in ChatGPT Plus, il 14 marzo 2023 (e lista d’attesa di accesso alle API per gli sviluppatori). GTP-4 inoltre è già stato integrato da Microsoft in BingChat ed è già stato adottato da altre aziende: Stripe lo sta usando per lo scan di business website per la generazione di report nell’ambito della prevenzione di frodi; Duolingo lo sta usando per la creazione di corsi di lingua inglese mirati per utenti specifici; Morgan Stanley ha in programma di usare GPT-4 per ricerche massive di informazioni da documentazione aziendale, da fornire infine ai propri business analyst.
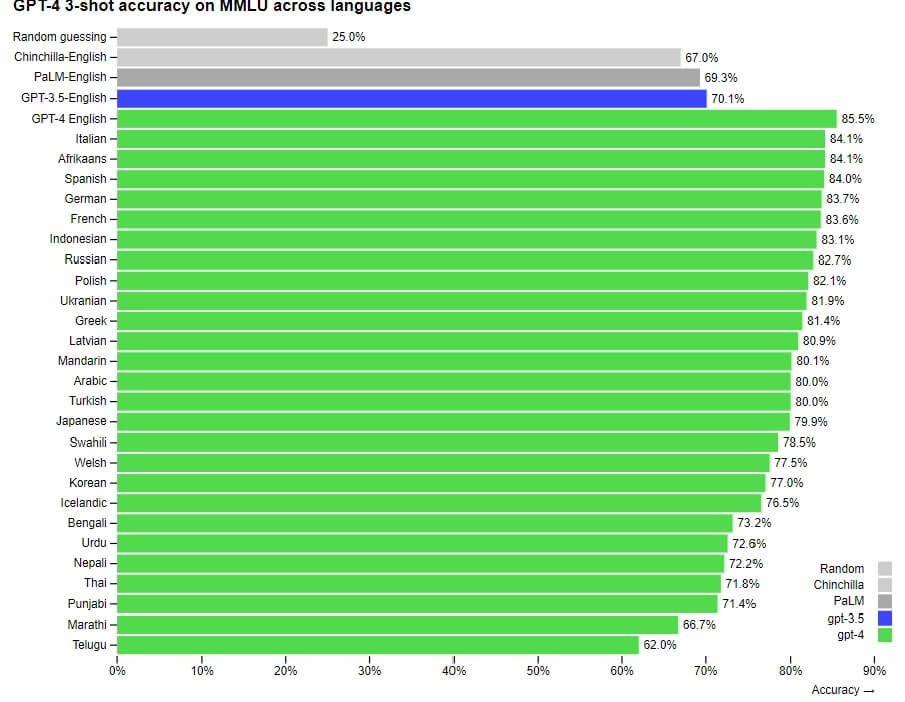
Conclusioni
Nonostante la sua natura multimodale, che amplia il ventaglio di possibili soluzioni applicative di LLM (o meglio definirli MLLM a questo punto), il rilascio di GPT-4 avviene in un momento in cui per nessuno dei rischi associati al suo predecessore GPT-3.5 (e relativi sistemi che lo hanno adottato) alcun metodo potenzialmente fattibile per poterli mitigare è stato proposto. Anzi, vista la natura multimodale di questo nuovo modello, ad essi se ne aggiungono di nuovi. E non sembra che da parte di OpenAI ci sia una seria intenzione di accelerare in questa direzione, ma solo attenzione a come monetizzare di più e il più presto possibile. Inoltre, il fatto di essere una tecnologia chiusa, non ne facilita certo l’adozione in settori produttivi dove sussistono policy legate alla trasparenza di dati e modelli di ML/IA, privacy, proprietà intellettuale, etc., oltre al rischio concreto di creazione di monopoli tecnologici. Altre proposte più aperte, come quelle già citate di Amazon Science o NVIDIA, aiuterebbero di molto a mitigare i rischi appena citati.

Video: Come funziona un MLLM?
Secondo la mia opinione, infine, gli MLLM attuali non sono la panacea a tutti i casi d’uso di ML/IA, in quanto ci sono ancora alcuni settori per i quali tutta una serie di problemi (soprattutto in ambiti scientifici) che richiede determinate conoscenze di dominio ignote a modelli come GPT-4 e una flessibilità di pensiero e capacità di adattamento a situazioni inaspettate che sono ancora appannaggio solo degli esseri umani. Ben vengano nuove proposte e migliorie per gli MLLM, ma ad oggi siamo ancora lontani dal poterli considerare come la soluzione finale e un passo concreto verso l’Intelligenza Artificiale Generale (AGI).



