
Multisearch e MUM, PaLM-E di Google, GPT-4 e gli algoritmi generativi: le recenti evoluzioni della ricerca online e degli algoritmi di intelligenza artificiale dimostrano in maniera decisa che la multimodalità sta diventando il presente e rappresenta il futuro dell’interazione uomo-macchina.
Indice degli argomenti:
La ricerca visuale: da Lens a Multisearch
Una delle meraviglie della cognizione umana è la nostra capacità di elaborare simultaneamente informazioni provenienti da diversi input sensoriali. Nella maggior parte dei compiti cognitivi, infatti, gli esseri umani combinano nativamente informazioni di natura diversa come audio, video, parlato, ecc. Ricreare questa capacità è da sempre uno degli obiettivi del Machine learning (ML).
La ricerca per immagini è di certo la forma di ricerca visuale più immediata. I dati che vediamo nel diagramma, non sono di certo recentissimi, ma ci danno una chiara indicazione dell’importanza di questo tipo di interazione già nel Q2 2019.
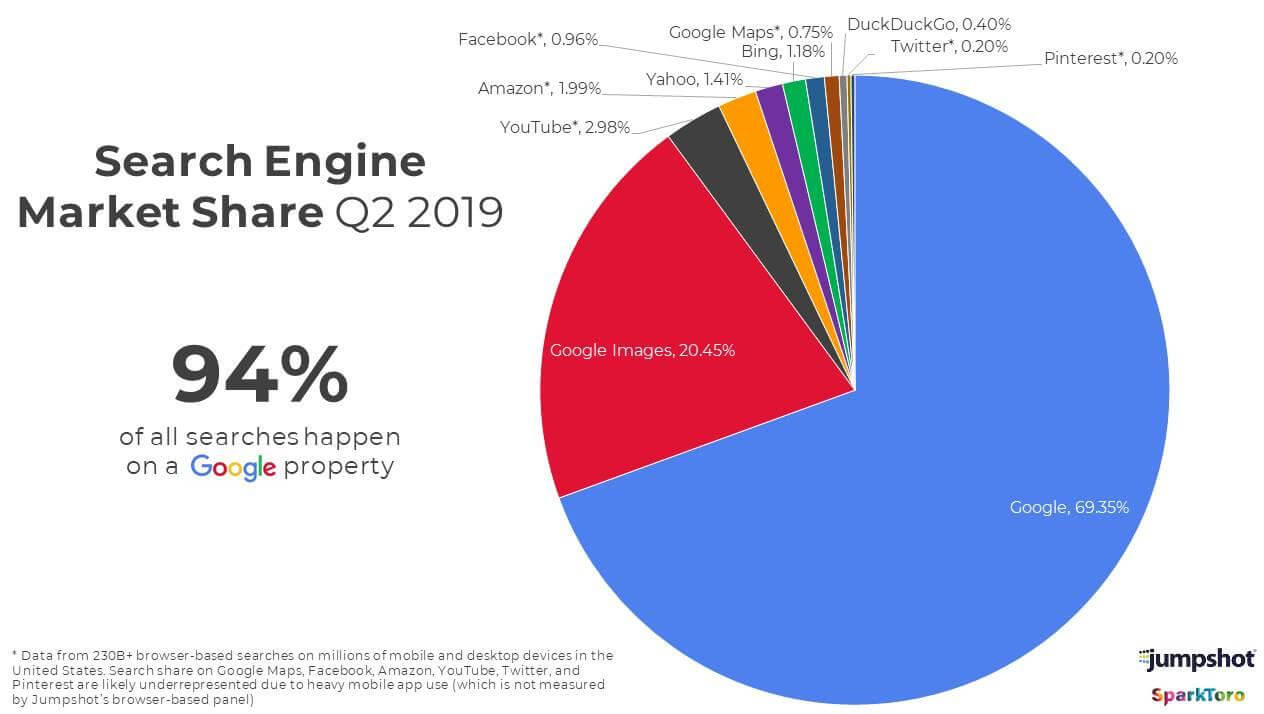
Di fatto, si tratta di una modalità di ricerca che rappresenta una risorsa sempre più importante, perché consente di ottenere dei risultati immediati non raggiungibili con altre modalità.
L’evoluzione è Lens: “una lente sul mondo fisico” che consente alle persone di passare da ciò che stanno guardando a un’esperienza che può passare dall’online all’offline. Nell’immagine vediamo un esempio in cui inquadro con Lens una scarpa e ottengo una grande quantità di informazioni sull’oggetto.
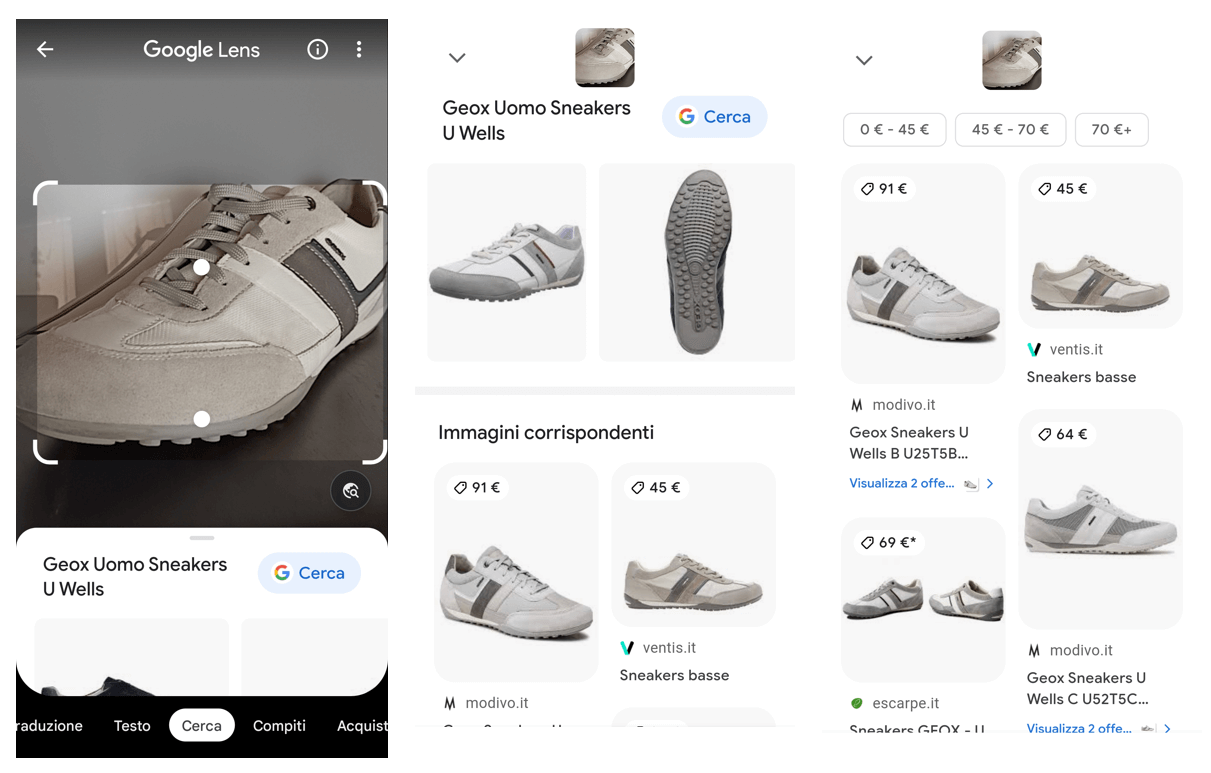
Questi strumenti contribuiscono a unire il mondo digitale con quello fisico. Inquadrando un piatto in una rivista di cucina è possibile ottenere delle ricette consigliate, oppure i ristoranti in cui andare a mangiare quel piatto. E inquadrando il piatto fisico in uno di quei ristoranti si potrebbe tornare al mondo digital ottenendo altre informazioni, come recensioni, video, ecc. Sono a tutti gli effetti sistemi di realtà aumentata.
Sistemi molto potenti, che consentono di abbattere barriere, ad esempio quelle linguistiche: inquadrando un manuale di istruzioni in inglese, in tedesco o in qualunque lingua possiamo visualizzare la traduzione in tempo reale, anche letta da Google Assistant.
Ma Lens non è solo una lente sul mondo fisico; infatti, oggi (da qualche mese) è la principale esperienza di ricerca visiva anche nel sito web desktop di Google.
Se clicchiamo sull’icona della fotocamera nella barra di ricerca e carichiamo una foto, arriviamo in un’area raffigurata nell’immagine che segue, con la possibilità di cercare immagini, prodotti, visualizzare traduzioni, ecc.
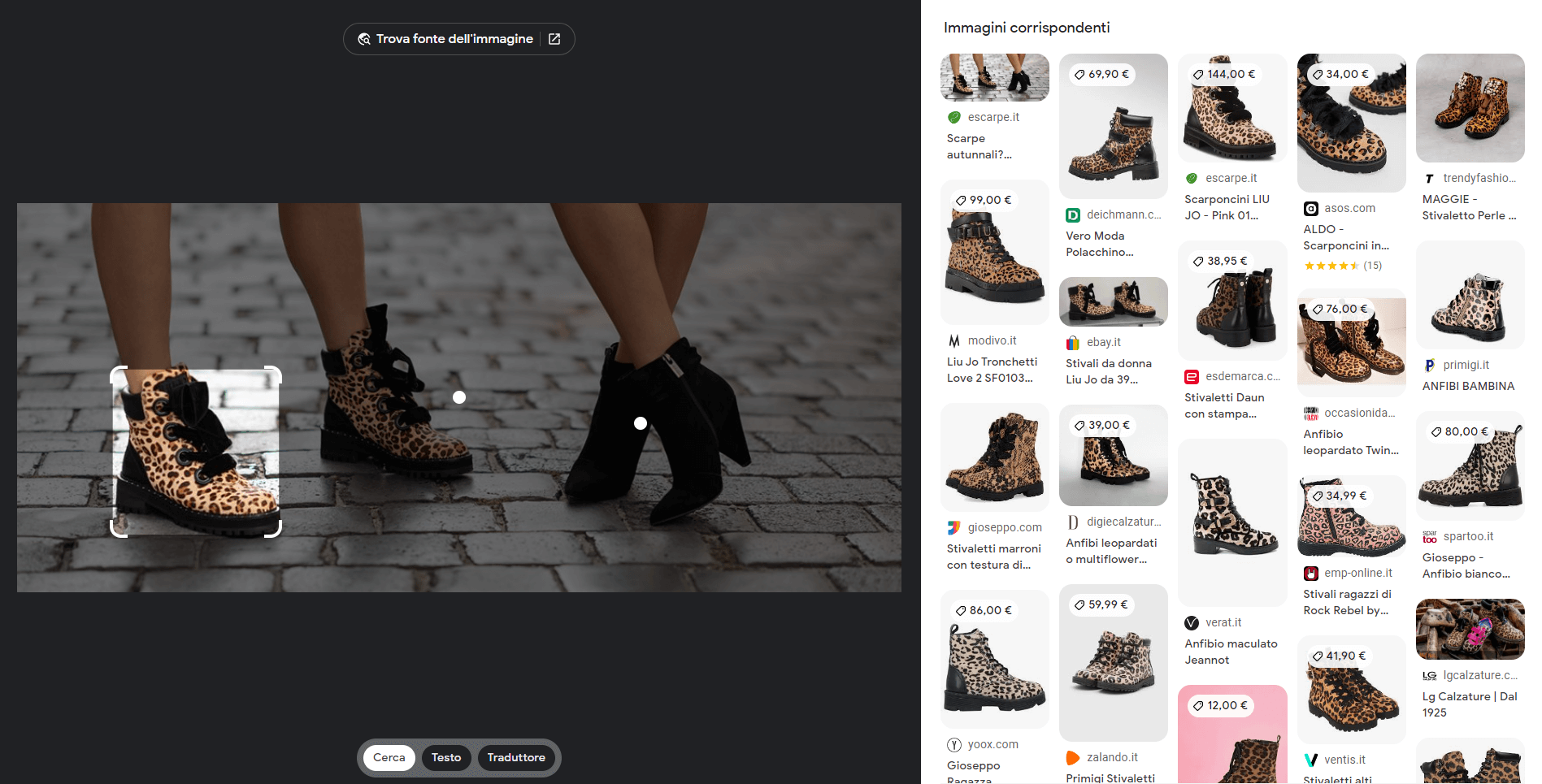
Come si nota, non si tratta più di una “semplice” ricerca di/per immagini. Iniziano ad essere presenti elementi di computer vision, con il riconoscimento di oggetti, testi, dati, e molto altro.
E questa esperienza sta arrivando nella pagina dei risultati di Google (SERP).
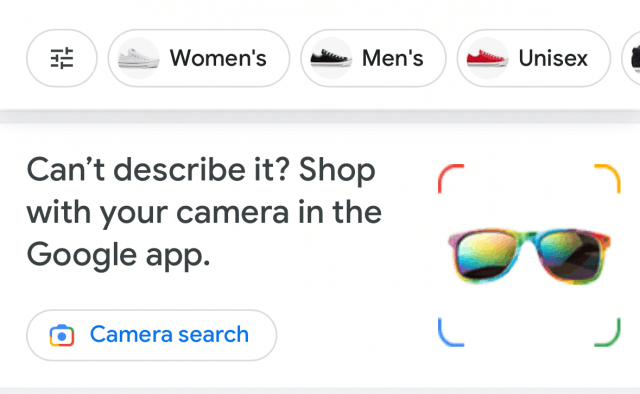
L’immagine raffigura un esempio di test (soltanto alcuni utenti lo stanno visualizzando) di Google sulla possibile integrazione di Lens all’interno della SERP.
“Non riesci a descrivere quello che cerchi?
Acquista attraverso la tua fotocamera nell’app di Google”
Credo che questo passaggio rappresenti esattamente la forza della multimodalità: compensiamo i limiti del linguaggio attraverso la componente visuale.
Nel frattempo, durante Google I/O 2021, viene presentato MUM (Multitask Unified Model): un potente modello di linguaggio che mira a migliorare la comprensione delle ricerche delle persone. Le caratteristiche? È multimodale e multilingua. E durante Search ON 2021, un altro importante evento organizzato da Big G, viene immaginato un futuro in cui Lens e MUM collaborano: un sistema che permette, per usare l’esempio fatto durante la presentazione, di inquadrare una camicia, e di chiedere dei calzini con la stessa fantasia.
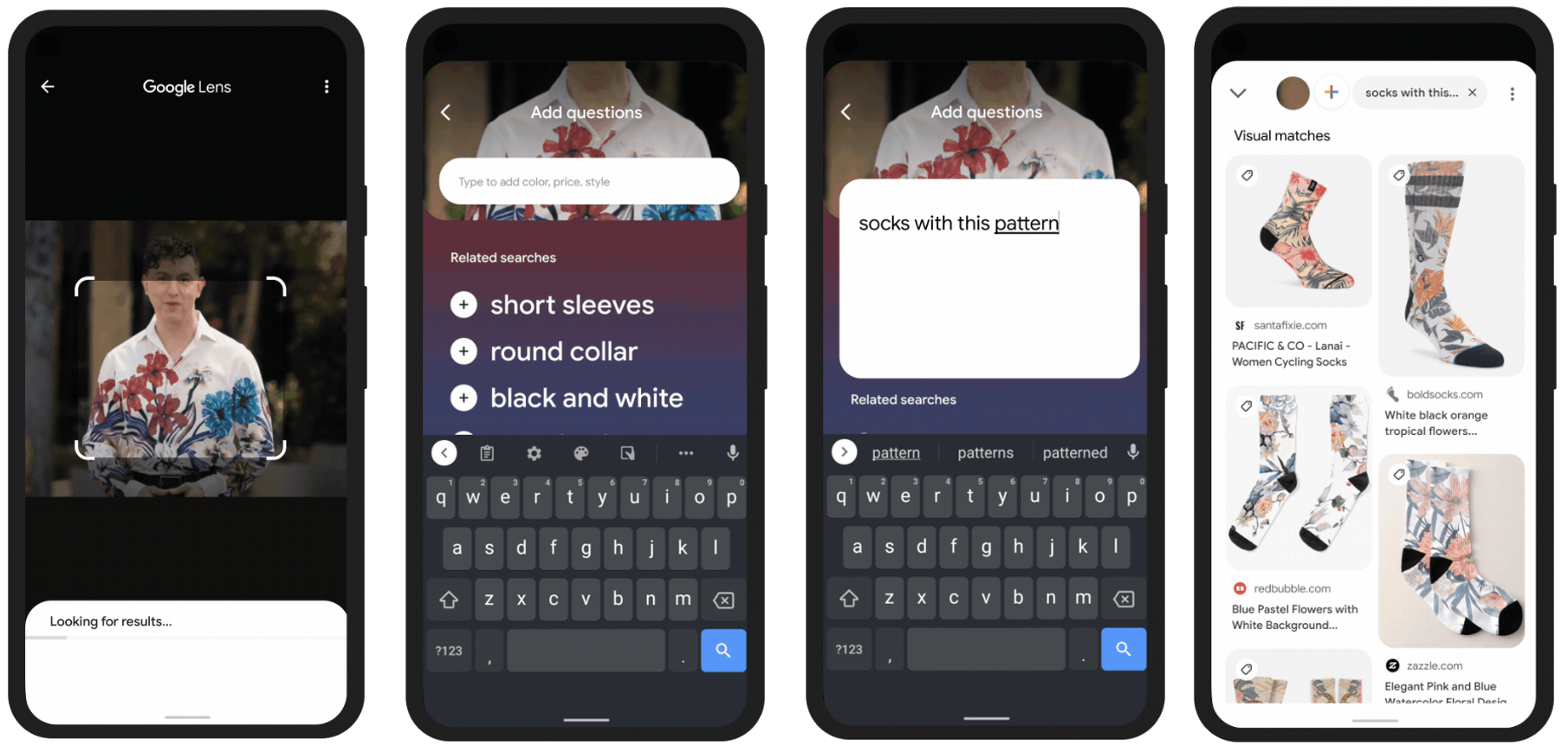
Una ricerca visuale aumentata di testo o voce
Durante l’edizione 2022 di Search ON viene condiviso un dato: le persone usano lens per rispondere a 8 miliardi di domande al mese. Credo che chi lavora su progetti di e-commerce di abbigliamento, arredamento, o comunque con una forte componente visuale, abbia notato dai dati che le ricerche provenienti da Lens stanno aumentando.
Multisearch
Multisearch, ovvero l’idea appena descritta che prende vita: una ricerca visuale fatta con Lens alla quale possiamo aggiungere informazioni testuali o vocali per generare un input migliore e raggiungere un risultato.
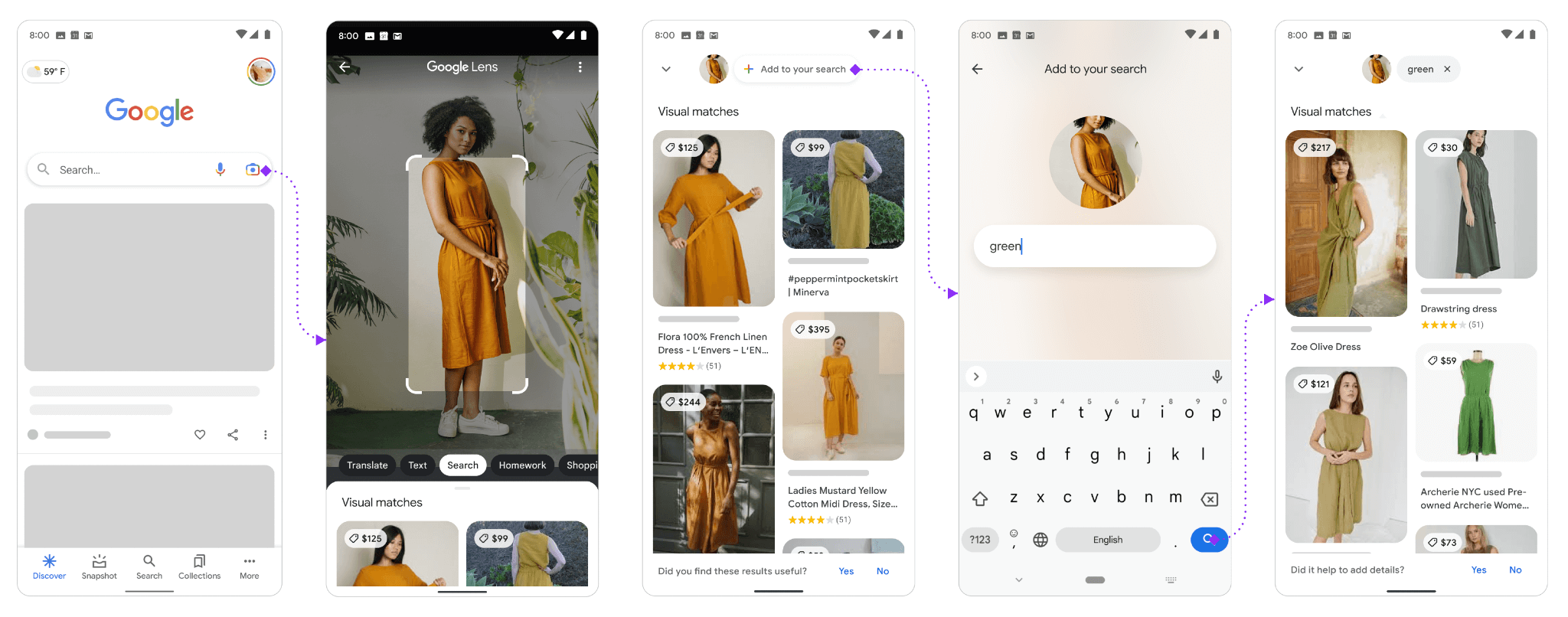
Quindi, ricapitolando: grazie ai progressi dell’AI andiamo oltre al campo di ricerca. Andiamo verso esperienze multimodali, proprio come lo sono le nostre interazioni umane. Andiamo verso una ricerca più naturale e intuitiva.
AI, multimodalità e algoritmi generativi
Ma la multimodalità non riguarda soltanto il mondo della ricerca, e questo lo vediamo con alcuni esempi.
MUM, si basa su un’architettura che viene definita “Transformer”, esattamente come tutti i più moderni modelli di linguaggio (ad esempio BERT, T5, DALLE-2, GPT-4), e come quei modelli, non solo può comprendere il linguaggio, ma può anche generarlo e operare su immagini, audio, video, e altri formati.
E anche questi modelli generativi stanno andando verso il concetto di multimodalità. L’immagine che segue è stata generata attraverso Stable Diffusion attraverso alcune mie foto sommate a un prompt testuale in cui chiedo di generare un ritratto in stile cyberpunk.

E qui Midjourney: partendo dall’immagine di un hamburger, aggiungo un prompt testuale per ambientarlo a Time Square.

DeepMind, il brand del gruppo Alphabet che si occupa di Intelligenza Artificiale, ha creato Gato, che è per definizione un modello multimodale e multitasking il quale può ricevere come input e dare come output testo, immagini, video, audio, azioni, ecc..
Anche l’interpretazione di Meta alla generazione di immagini è degna di nota. Attraverso il progetto esplorativo definito Make-A-Scene, infatti, un creator può produrre uno “schizzo” che rappresenta la sua idea attraverso una tavoletta grafica o semplicemente un foglio di carta. Successivamente può aggiungere un prompt testuale, e l’algoritmo produce l’output.

Video: Make a scene
GPT-4 e la multimodalità
GPT-4, oltre a potenziare la versione precedente del modello, ha una nuova capacità: è multimodale. Quindi, non solo può ricevere input testuali, ma anche visuali. Ad esempio, può descrivere un’immagine, può creare del testo che armonizza un prompt testuale e un contesto descritto dall’immagine.
Durante la presentazione, Greg Brockman, presidente e co-fondatore di OpenAI, ha usato uno schizzo di una semplice pagina web fatto su un foglio di carta come input per l’algoritmo. Successivamente, attraverso un prompt testuale, ha richiesto di generare HTML e JavaScript per trasformare lo schizzo in una pagina web.
Di certo si tratta di un’azione molto semplice, ma il concetto è davvero straordinario.
PaLM-E di Google
L’anno scorso Google ha presentato PaLM (Pathways Language Model): un modello basato sui transformer che conta 540 miliardi di parametri ed è stato addestrato attraverso Pathways System, che ha consentito un livello di parallelizzazione e di efficienza mai ottenuti in precedenza.
Tra i diversi progetti in cui è stato declinato PaLM, recentemente troviamo PaLM-E che unisce il modello di linguaggio al dominio visivo e alla robotica (la “E” corrisponde proprio al termine “embodied”), portando il concetto di multimodialità ad un altro livello.
Come funziona PaLM-E?
PaLM-E funzionano iniettando “osservazioni” in un modello di linguaggio pre-addestrato. Osservazioni che derivano dai dati dei sensori, ad esempio delle immagini. Gli input che riceve PaLM-E, quindi, sono testo e altre modalità (immagini, stati del robot, scenari, ecc.) in un ordine arbitrario, che vengono definiti “frasi multimodali“.
Ad esempio, un input potrebbe essere simile a “Cosa è successo tra lo scenario <immagine 1> e <immagine 2>?“, ovvero tra due momenti rappresentati da due immagini. L’output potrebbe essere una risposta testuale che lo spiega.
Multimodalità, le conclusioni
Il futuro dell’interazione uomo-macchina sarà multimodale. La direzione è abbastanza chiara, perché il tentativo è quello di dare agli algoritmi dei sensi comparabili a quelli umani per comprendere il mondo.
Tuttavia, crediamo che si potrà andare anche oltre. Esistono, ad esempio, sperimentazioni per l’interpretazione dell’attività cerebrale in maniera non invasiva. Questo potrà essere significativo nell’assistenza ai pazienti e nella comprensione del cervello, ma anche, in futuro, per nuove modalità di interagire con le macchine che vanno oltre il nostro linguaggio, che di fatto è limitato.



