
Il 2022 è stato un anno di consacrazione per l’AI generativa grazie alla introduzione di modelli come Dall-E 2, Stable Diffusion, Imagen e Parti. Il 2023 sembra avvalorare i progressi ottenuti in questo ambito con il rilascio del modello testo a immagine (TTI) di Google, Muse, all’inizio del mese di gennaio.
Indice degli argomenti:
Cos’è Muse
Nella presentazione degli scienziati di Google sull’archivio arXiv, Muse viene descritto come un modello realizzato su un’architettura Transformer che rappresenta lo stato dell’arte nella generazione di immagini da testo, avendo maggiore efficienza e accuratezza rispetto ai modelli basati sul processo di diffusione e ai modelli autoregressivi come Parti.
I modelli di generazioni di immagini da prompt di testo hanno realizzato enormi progressi in questi anni. E ciò è stato reso possibile da una serie di innovazioni nelle architetture di apprendimento profondo e grazie a nuovi paradigmi di training del modello come il masked language modeling, ai modelli di diffusione, insieme alla disponibilità di enormi set di dati di coppie di immagini-testo.
Sulla base dell’esperienza accumulata in precedenza, i ricercatori di Google sono riusciti a realizzare un modello che richiede meno risorse di calcolo e fa progressi su aspetti nei quali erano carenti altri modelli AI.
Comparazione fra Muse e gli altri sistemi di AI generativa
Muse sfrutta gli avanzamenti e le ricerche sul deep learning, compresi quelli sugli LLM, sulle reti neurali quantizzate, che consentono maggiore efficienza, e sull’approccio mascherato.
Rispetto a sistemi come Imagen o Dall-E2, il nuovo modello di Google raggiunge livelli di maggiore efficienza grazie all’addestramento a codificare un’immagine in token discreti (ciascuno corrispondente a una piccola porzione di una immagine). A paragone con Parti, un modello autoregressivo TTI (predizione delle sequenze un token alla volta) Muse è più efficiente in quanto utilizza il parallel decoding.
I ricercatori di Big G hanno messo a confronto i modelli, con stesso hardware (TPU v4 predisposta per l’AI), Muse si è dimostrato 10 volte più veloce eseguendo la fase d’inferenza e 3 volte più veloce di Stable Diffusion.
Questo miglioramento in termini di efficienza, stando agli scienziati Google, non comporta, tuttavia, una perdita di qualità dell’immagine generata o della comprensione semantica dell’input di testo.
“Il nostro forte interesse è stato quello di unificare la generazione di immagini e testo attraverso l’impiego dei token – spiega in sintesi Dilip Krishnan, ricercatore di Google. Muse è sviluppato sulla base delle idee di MaskGit, illustrato in un nostro precedente documento, e sull’approccio masking modeling applicato agli LLM”.

Muse, i punti di forza
Come altri generatori di immagini a partire dal testo, Muse è addestrato su un ampio corpus di immagini associate a didascalie. I ricercatori di Google hanno utilizzato una variante di T5, T5XXL (4,6 miliardi di parametri), un potente modello di linguaggio di grandi dimensioni pre-addestrato per generare immagini ad alta qualità. Il modello Muse è condizionato dal modello linguistico T5XXL pre-addestrato perché, chiariscono gli scienziati di Big G, sulla base dei risultati di Imagen, questo processo garantisce una generazioni di immagini più realistiche e di alta qualità.
Muse, inoltre, utilizza lo strumento VQGAN “tokenizer” (elaborazione di una immagine di input in una sequenza di token) pre-addestrato che opera su un input di immagine 256X256. I ricercatori sottolineano che, in un quadro di approccio di tokenizzazione, VQGAN si è dimostrato più utile al modello sviluppato, evidenziando come un modello di tokenizzazione con prestazioni migliori non sempre si traduce in un modello text-to-image con prestazioni migliori.
Nel complesso, si tratta di una attività a tre strati in cui alla fine un SuperRes Transformer, condizionato da token a bassa risoluzione, arriva a definire immagini di qualità superiore.
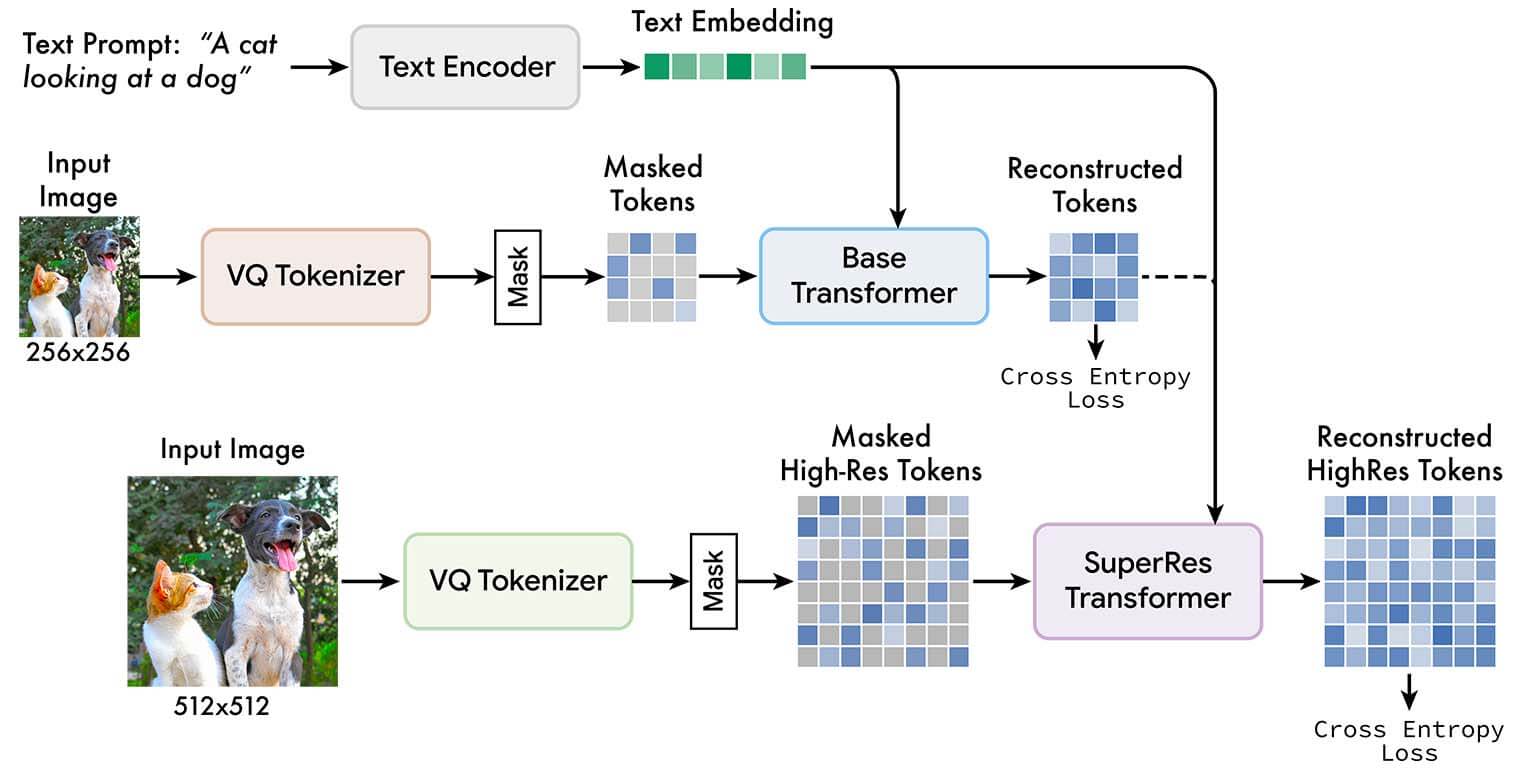
Muse, le performance
Secondo Dilip Krishnan, un altro aspetto innovativo del modello Muse è rappresentato dal parallel decoding che lo distingue dai modelli basati sul processo di diffusione e da quelli autoregressivi. I primi usano tecniche di denoising progressivo mentre i secondi il serial decoding.
“Il processo di decoding di Muse – precisa Krishnan – può essere paragonato alla pittura in cui l’artista incomincia con uno schizzo della parte fondamentale del quadro, per poi progressivamente inserire il colore e perfezionare l’opera con l’aggiunta dei dettagli”.
I risultati e le performance di Muse sono confortanti. Il nuovo modello di Google è stato valutato sulle metriche standard come Frechet inception distance (FID) sui dataset COCO e CC3M, che permette di misurare qualità e diversità delle immagini, e CLIP (Contrastive Language-Image Pre-training), utilizzabile per verificare la corrispondenza testo/immagine raggiungendo punteggi eccellenti.
L’attività di Muse è stata sottoposta anche al giudizio di valutatori umani anonimi e provenienti dal team informatico di Google, utilizzando PartiPrompts, collezione di prompt in inglese realizzata per misurare le capacità dei modelli in una ampia varietà di categorie. Si è dimostrato anche in questo caso che Muse è superiore a Stable Diffusion nell’allineamento testo/immagine.
Un altro aspetto interessante è che Muse ha prestazioni migliori rispetto ad altri modelli in aree come la cardinalità (prompt che comprendono uno specifico numero di oggetti), composizionalità, proprietà basilare del nostro linguaggio (prompt che descrivono scene con diversi oggetti che hanno una relazione reciproca) e nel rendering del testo. Tuttavia, il modello mostra ancora molte lacune quando bisogna effettuare rendering di testi lunghi e su un più ampio numero di oggetti.
Ulteriori vantaggi di Muse sono dati dalla capacità di editing task senza necessità di ri-addestrare in modo specifico il modello. Con particolare efficacia nell’inpainting (operazione di ricostruzioni di parti mancanti di una immagine), outpainting (aggiunta di dettagli all’immagine) e nel mask-free editing (cambiamento dello sfondo o di specifici oggetti dell’immagine).
I ricercatori, convinti che i modelli generativi possono avere un impatto positivo, potendo anche aumentare il potenziale creativo umano, hanno però ritenuto opportuno di non consentire l’accesso libero al codice di Muse, o rilasciare una demo pubblica, considerando i rischi connessi a un suo possibile uso distorto per fini di manipolazione, disinformazione e diffusione di pregiudizi. Mettendo in guardia, in modo particolare, sull’impiego di questi modelli per la generazione di immagini di volti umani e persone.
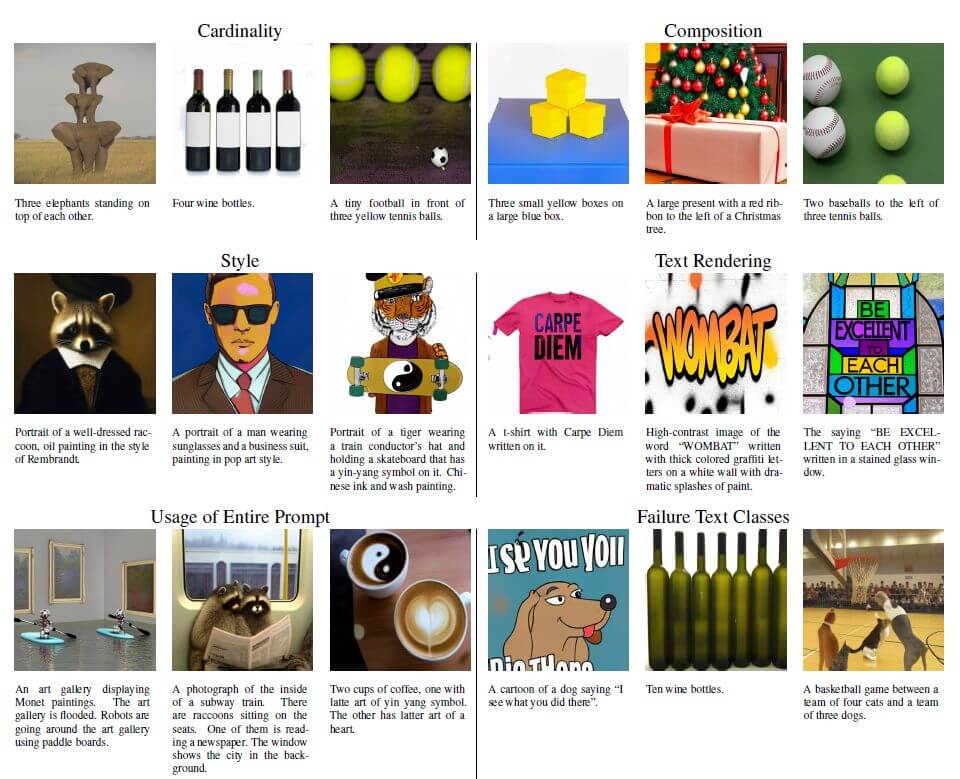
Conclusioni
Muse dimostra quanto sia importante per i generatori di immagine da descrizione di testo l’utilizzo di LLM pre-addestrati. I ricercatori di Google provano anche che questo nuovo modello basato sull’architettura Transformer può avere prestazioni di pari livello se non superiori ai modelli di diffusione e auto-regressivi.


