
Non è assolutamente un compito facile insegnare alle macchine a capire come comunichiamo. L’obiettivo finale del Natural Language Processing (anche detto elaborazione del linguaggio naturale o NLP) è leggere, decifrare, comprendere e dare un senso ai linguaggi umani in un modo valutabile.
Indice degli argomenti:
Cos’è il Natural Language Processing
Il Natural Language Processing (NLP) o elaborazione del linguaggio naturale è un ramo dell’intelligenza artificiale che si occupa di fornire ai computer la capacità di comprendere il testo e le parole pronunciate, come gli esseri umani.
L’NLP è un campo di studi che unisce informatica, intelligenza artificiale e linguistica. La ricerca ha orientato molto gli sforzi su queste tematiche, in quanto i dati testuali sono ormai ovunque: documenti nel nostro computer o su cloud, corpora pubblici o privati, dati non strutturati nel Web (pagine web, post, social, log).
A rendere particolarmente difficoltosa la comprensione del linguaggio umano da parte di un algoritmo informatico, contribuiscono le sue numerose ambiguità: infatti, per comprendere un determinato discorso, è necessario possedere anche una conoscenza della realtà e del mondo circostante.
La semplice conoscenza del significato di ogni singola parola non è infatti sufficiente a interpretare correttamente il messaggio della frase, al contrario può condurre a comunicazioni contraddittorie e prive di significato.
La ricerca in questo ambito si è focalizzata in particolar modo sui meccanismi che permettono alle persone di comprendere il contenuto di una comunicazione umana e sullo sviluppo di strumenti che possano fornire ai sistemi informatici la capacità di comprendere ed elaborare il linguaggio naturale.
Come funziona l’NLP: le varie fasi del Natural Language Processing
L’elaborazione del linguaggio naturale comporta una successione di fasi che tentano di superare le ambiguità del linguaggio umano: si tratta di un processo particolarmente delicato, a causa delle complesse caratteristiche del linguaggio stesso. Proprio per ridurre il più possibile gli errori, il processo di elaborazione viene suddiviso in numerose fasi, di seguito esplicitate.
Tokenization
L’elaborazione di un testo inizia con la sua scomposizione in token corrispondenti a spazi, parole, punteggiatura, frasi. Il task non è particolarmente complesso rispetto agli altri, ma presenta comunque alcune problematiche: per esempio, se si considera il punto come fine di una frase, si rischia di sbagliare frequentemente in quanto il punto potrebbe riferirsi a una abbreviazione, a una data o a un link.
Esempio: “L’aereo per gli U.S.A. atterra a New York.”
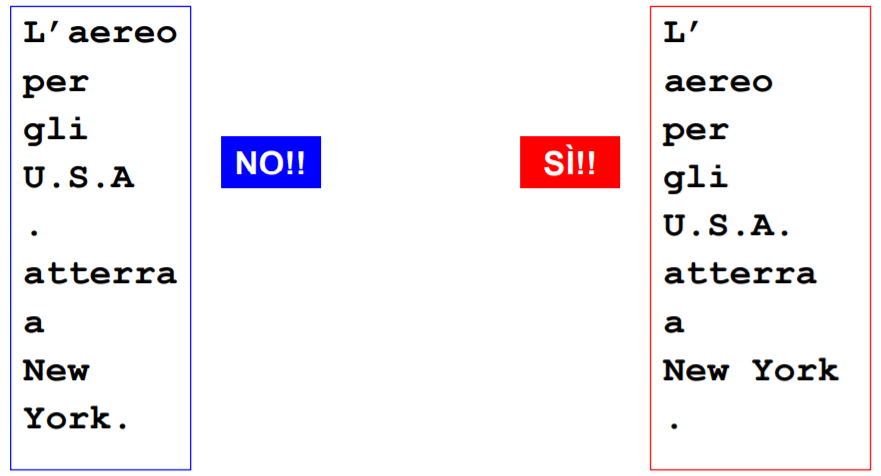
Con opportune regole che gestiscono la struttura delle abbreviazioni si possono ottenere risultati ancora più accurati.
Analisi morfologica e lessicale (part-of-speech)
La morfologia fornisce informazioni sulla forma di ciascuna parola e sul suo ruolo all’interno di una frase. Il lessico (o vocabolario) è il complesso delle parole e dei modi di dire (locuzioni) di una lingua.
L’analisi morfologica e lessicale prevede la consultazione di apposite liste di lemmi e delle loro derivazioni (liste che possono essere eventualmente integrate con termini specifici relativi al dominio che si sta studiando), la risoluzione delle forme di flessione (come la coniugazione per i verbi e la declinazione per i nomi) e la classificazione delle parole basata su determinate categorie (come il nome, il pronome, il verbo, l’aggettivo).
Analizzatori lessicali e morfologici possono essere implementati separatamente, ma spesso costituiscono un unico task. Il risultato di questo processo è noto come Part of Speech Tagging (PoS) e il tagset più diffuso è Penn Treebank Project, che distingue 36 parti di speech (48 se si include la punteggiatura).
Già in questa fase emergono le prime difficoltà legate all’ambiguità, in questo caso lessicale: per certi vocaboli il task non sa attribuire correttamente la giusta categoria morfologica.
Alcuni esempi:
- “Tutti hanno un telèfonino e a chi telèfonìno non si capisce”
- “Pésca”, che può essere un nome (lo sport, la lotteria), un verbo (lo sport, l’estrazione), o “pèsca”, il frutto, o ancora un aggettivo (il colore).
Questa ambiguità può essere risolta con l’introduzione delle fasi successive, nelle quali si includa anche la comprensione del contesto.
Analisi sintattica e generazione di parse tree
La sintassi consente di spiegare come alcune sequenze di parole hanno senso compiuto, mentre altre pur contenendo esattamente le stesse parole, ma in ordine non corretto, siano prive di senso.
L’analisi sintattica tenta, dunque, di individuare le varie parti che danno un significato alla frase (soggetto, predicato, complemento) e di posizionare correttamente le parole all’interno di una frase. Generalmente la struttura sintattica è rappresentata come Parse Tree.
Anche in questa fase l’ambiguità, stavolta di tipo sintattico (detta anche ambiguità locale perché è riferita ad una parte della frase), comporta non poche difficoltà. Ad esempio:
- “Giorgio vide Giulio con un telescopio”, chi aveva il telescopio?
A volte il contesto aiuta a risolvere tali ambiguità, ma in presenza di frasi articolate si genera una proliferazione di alberi sintattici con evidente aumento della complessità.
Named Entity Recognition
La fase successiva vede l’individuazione, tramite regole o approcci statistici di machine learning, di parole o gruppi di parole che specificano entità appartenenti a diverse categorie.
NER (Named Entity Recognition) è un sub-task di IE (Information Extraction), specializzato nella ricerca e classificazione di Named Entity (NE), cioè di porzioni di testo di documenti in linguaggio naturale che rappresentano entità del mondo reale, come nomi di persone, luoghi, dati, compagnie.
NER è un sub-task fondamentale del IE in quanto:
- pone le basi per un’analisi più approfondita del testo, eseguita ad esempio tramite i processi di Coreference Resolution, Relationship Extraction, e utilizzando le Named Entity estratte;
- effettua una scrematura estraendo solo le entità utili in un determinato contesto.
Le entità possono appartenere ad alcune categorie standard, generalmente riconosciute valide in ogni dominio come luoghi o organizzazioni, a categorie comuni come date, misure, indirizzi oppure a specifici domini (nomi farmacologici, banche, ecc.). Di seguito un esempio pratico:
- [Jim] persona ha acquistato 300 azioni di [Acme Corp.] Organizzazione nel [2006] Tempo .
Anche questa fase non è esclusa da possibili ambiguità: General Motors potrebbe indicare un’entità appartenente alla categoria Organizzazione oppure essere considerata un titolo militare.
Negli ultimi anni con metodi basati sul deep learning e con la disponibilità sempre maggiore di dati, si stanno raggiungendo risultati sempre più sorprendenti.
Analisi semantica
L’analisi semantica si propone di comprendere il significato di una intera frase partendo dal significato di ciascun termine che la compone e dalle relazioni esistenti tra gli stessi.
Il significato di una frase infatti, non è dato solo dalle parole, ma anche dalla conoscenza delle regole che le guidano in base alla combinazione, all’ordine in cui appaiono, ai legami con altri termini interni o esterni alla frase.
Queste operazioni consentono di risolvere alcuni casi di ambiguità globale, ossia riferita all’intera frase, comunque presente anche quando il PoS tagging restituisce la corretta categoria morfologica di un vocabolo e il parser costruisce la giusta struttura della frase.
Anche in questa fase sono presenti casi di ambiguità, ad esempio:
- “Ogni uomo ama una donna”
- per ogni singolo uomo, esiste una singola donna che egli ama
- esiste una sola singola donna che ognuno degli uomini (preso singolarmente) ama
Analisi del discorso
In questa fase si considera un insieme di frasi ovvero un intero discorso, infatti un task fondamentale ma particolarmente complesso appartenente a questa fase è chiamato coreference, ha il compito di identificare nei testi tutte le espressioni che si riferiscono a una determinata entità tra quelle individuate da Named Entity o tra le referenze anaforiche ad esse attinenti.
In una prima fase identifica le parti nominali del testo usando Named Entity, numero, genere e ruolo sintattico, successivamente effettua un controllo di consistenza a ritroso e determina tutti i possibili collegamenti con esse, fino ad una distanza predefinita. Esiste poi un task ulteriore che risolve le ellissi, ossia frasi prive di alcuni elementi sintattici che devono essere dedotti dal contesto.
Di seguito viene mostrato un esempio in lingua inglese, ma replicabile in qualsiasi lingua:
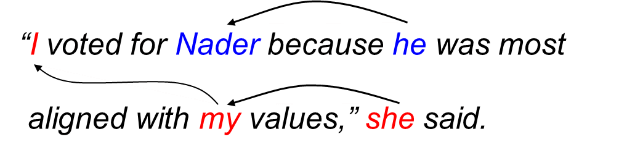
Un altro possibile task che viene effettuato in questa fase è la pragmatica, ovvero una disciplina che tende a fare distinzione tra significato dell’enunciato e l’intenzione del parlante, il significato dell’enunciato è il suo significato letterale, mentre l’intenzione del parlante è il concetto che il parlante tenta di trasmettere.
L’analisi del discorso è un passo importante per molte attività di NLP, che includono la comprensione del linguaggio naturale come la sintesi di documenti, il question answering e l’estrazione di informazioni da un testo.
Natural Language Processing e intelligenza artificiale
Negli ultimi anni si è assistito alla nascita di nuovi approcci, che integrano l’elaborazione del linguaggio naturale nelle sue diverse fasi, con gli algoritmi di deep learning, producendo risultati nettamente superiori al passato.
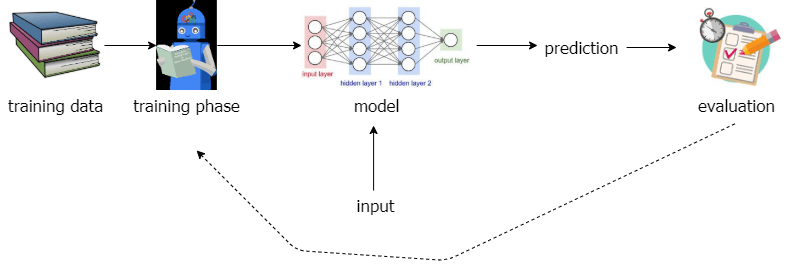
I primi approcci al NLP con il deep learning sono stati intrapresi nel 2000, ma il 2013 e il 2014 sono stati gli anni che hanno segnato l’inizio della diffusione delle reti neurali per il NLP.
Sono state approfondite differenti tecniche per la rappresentazione del linguaggio naturale in maniera numerica, ossia in grado di trasformare ogni parola di un dizionario in un vettore continuo di numeri reali.
Queste rappresentazioni vettoriali, chiamate word embeddings, sono apprese da modelli di natural language processing basati su architetture di reti neurali, definiti come modelli spaziali vettoriali (Vector Space Model).
Uno dei modelli più famosi utilizzati per l’apprendimento delle rappresentazioni vettoriali delle parole, è Word2Vec. Gli embedding di word2vec non sono concettualmente differenti da quelli appresi con una rete neurale a flusso in avanti; tuttavia l’efficienza del modello, permette di apprendere embedding a partire da corpus testuali estremamente imponenti, riuscendo così a catturare meglio certe relazioni tra le parole, come il genere, il tempo verbale o il rapporto tra i vari termini.
Un’estensione dell’architettura di Word2Vec è FastText (che include codifiche a livello di encoding e prende in considerazione parole non comuni) e GloVe (basato su informazioni statistiche globali provenienti da ricorrenze di parole). Un limite di questi approcci è il non tener conto dell’ordine delle parole.
Le reti neurali ricorrenti (RNNs) sono una scelta ovvia quando si ha che fare con sequenze di input dinamiche, ma sono state rapidamente rimpiazzate, per quanto riguarda il natural language processing, dalle LSTM. Una LSTM bidirezionale è tipicamente utilizzata per sfruttare sia il contesto a sinistra che il contesto a destra della parola corrente.
Con l’introduzione del meccanismo di attenzione (Attention) nel 2015, si è giunti poi nel 2018, a sviluppare una delle principali innovazioni nell’elaborazione del linguaggio naturale: BERT (Bidirectional Encoder Representations from Transformers), con i suoi approcci alternativi GPT-2, XLNet, XLM, ELMo, RoBERTa, ULMFiT, MultiFit, ALBERT, DistilBERT, ovvero modelli con una rappresentazione Context-Aware.
Questi approcci utilizzano un meccanismo di attenzione con addestramento bidirezionale (Transformer) per modellare il linguaggio, tenendo conto della relazione tra tutte le parole in un contesto, ovvero l’intera frase viene letta in maniera immediata anziché in sequenza.
Questi modelli, che rappresentano al momento lo stato dell’arte nel NLP, sfruttano il meccanismo del Transfer Learning (utilizzato principalmente nella computer vision) nel Natural Language Processing. I modelli linguistici non hanno bisogno di dati annotati: l’apprendimento può quindi sfruttare tutti i dati disponibili, fino a miliardi di parole, così da approcciare facilmente nuovi domini o nuove lingue.
Grazie a queste ultime innovazioni, gli embedding appresi da un modello linguistico creato per un determinato scopo, possono essere sfruttati per arricchire l’input utilizzato da un altro modello, per poi raggiungere un determinato obiettivo, differente dal precedente. Inoltre, lo stesso modello linguistico, può essere calibrato per svolgere direttamente una mansione di interesse, con la necessità di molti meno dati.
NLP e machine learning
Se il Natural Language Processing è il processo che permette alla macchina di comprendere e relazionarsi con gli esseri umani, il Machine Learning è la tecnica di intelligenza artificiale che si occupa di fornire al NLP la capacità di apprendimento.
Si tratta di una branca dell’AI molto vasta, che racchiude innumerevoli task linguistici. Gli apprendimenti possono essere sia di tipo supervisionato (come la text classification), sia non-supervisionato (come il topic clustering), e comprendono algoritmi di Machine Learning e di Deep Learning.
Apprendimento supervisionato
O supervised learning. In questo modello di apprendimento sono presenti una variabile di input (i dati annotati) e una di output (i risultati desiderati). Compito dell’algoritmo è di imparare ad approssimare al meglio la funzione di relazione tra le due variabili, al fine di predire l’output corretto in presenza di nuovi dati.
Apprendimento non supervisionato
O unsupervised learning. Scopo di questo tipo di apprendimento è quello di inferire pattern nascosti in grandi dataset di dati non annotati. Poco affidabile nell’esecuzione di task complessi e che richiedono un alto tasso di accuratezza, i modelli non supervisionati si prestano invece molto bene alla risoluzione di task di clustering e riduzione della dimensionalità.
Apprendimento semi-supervisionato
O semi-supervised learning. A metà tra le modalità di apprendimento presentate sopra, l’apprendimento semi-supervisionato utilizza sia dati annotati che dati non annotati. Si tratta di modelli molto popolari oggi, in quanto capaci di moderare i limiti dell’apprendimento super-non supervisionato e di catalizzarne i punti di forza.
Apprendimento con rinforzo
O reinforced learning. Un modello di apprendimento che non necessita di dati. Ciò di cui ha bisogno per imparare un task sono: un ambiente, un agente con scopo, una serie di “punizioni” e “ricompense” che guidano l’agente allo scopo desiderato.
Natural Language Processing: ambiti applicativi
Le ricerche sul NLP hanno dunque riguardato diversi ambiti della conoscenza umana, come le scienze informatiche, l’intelligenza artificiale, la linguistica e la psicologia.
Più nello specifico, esistono moltissimi ambiti applicativi in cui troviamo il NLP come fulcro centrale per riuscire a raggiungere gli obiettivi prefissati. Di seguito, vengono citati i più frequenti:
- Estrazione ed elaborazione del testo: da testo nativo digitale o digitalizzato tramite OCR;
- Topic Discovery: tecnica non supervisionata per evidenziare argomenti specifici discussi in un testo;
- Sentiment Analysis: tecnica supervisionata per stabilire la polarizzazione del testo, con la comprensione del tono e dello stato d’animo con cui una frase viene espressa o scritta;
- Classificazione dei documenti in categorie predefinite: per classificare report, e-mail, ticket, ecc.;
- Named Entity Recognition: per estrarre e mettere in relazione entità specifiche all’interno di un testo (persone, organizzazioni, località, date, quantità numeriche, formati specifici);
- Chatbot / Voicebot: comprensione del linguaggio naturale, gestione dei dialoghi, ricerca vocale e assistenti ad attivazione vocale, Text to Speech e viceversa;
- Motori di ricerca in tempo reale;
- Part of speech Tagging and Coreference Resolution: riconoscimento di parti grammaticali all’interno del testo, identificazione di relazioni individuate tra entità all’interno del testo;
- Generazione e/o riassunto di testi specialistici;
- Traduzione automatica da/verso qualsiasi lingua;
- Modellazione linguistica: previsione parola o frase successiva;
- Generazione e clonazione della voce: chatbot personalizzati, hotline, audiolibri, lettori di testo, tono della voce, accenti, emozioni;
- Natural Language Generation (NLG): le soluzioni provvedono a produrre del testo in linguaggio comune partendo da dati informatici. Ad esempio sono sistemi utili per velocizzare la reportistica della Business Intelligence o per l’analisi dei servizi di customer service;
- Riconoscimento del testo scritto a mano;
- Generazione di didascalie delle immagini: dal riconoscimento delle immagini alla descrizione testuale;
- Domande e risposte;
- Prevenzione delle frodi analizzando un testo non strutturato.
Alcuni esempi di elaborazione del linguaggio naturale NLP con Python
Python è un linguaggio di programmazione popolare per i data scientist e coloro che lavorano nell’ambito machine learning. Per questo motivo molti software NLP sono scritti in Python, perché molte aziende lo preferiscono per la sua sintassi comprensibile e le sue capacità matematiche.
Tra gli esempi troviamo alcune piattaforme NLP scritte in Python che includono includono Natural Language Toolkit (NLTK) e spaCy.
Natural Language Processing: a che punto siamo e cosa ci aspetta
Negli ultimi quattro anni, si sono fatti enormi progressi e ottenuti innumerevoli risultati.
Di seguito alcuni dati in termini di accuratezza:
- riconoscimento della lingua: per testi brevi circa 80%, per testi lunghi circa il 99%
- tokenizzazione e segmentazione: circa il 98%
- analisi morfologica e lessicale: tra il 90% e il 97%
- analisi sintattica: tra il 70% e oltre il 90%
Siamo in un periodo di rapidi cambiamenti nel campo del Natural Language Processing: in meno di diciotto mesi ci sono stati almeno quattro progressi sostanziali nelle soluzioni di deep learning pre-addestrate (ad esempio Bert e suoi sviluppi) e non c’è motivo di credere che non ce ne saranno ulteriori da qui a breve.
Al momento, ci vuole ancora del tempo per scaricare il codice sorgente, far funzionare il tutto con TensorFlow, PyTorch o similari, aggiungere i layer finali alla rete e addestrarla con un dataset di riferimento. Ma è abbastanza chiaro che man mano che il campo maturerà, i limiti iniziali nell’esecuzione del natural language processing diminuiranno e la qualità dei risultati continuerà a crescere, anche avendo a disposizione piccoli dataset.
Restano ancora numerose sfide aperte: sicuramente, alcune riguardano l’aumentare sempre di più la qualità della comprensione (Natural Language Understanding), avere la potenzialità di sistemi e modelli multilingua su larga scala, captare l’ironia, i modi di dire, i sensi comuni.
Natural Language Processing e Natural Language Understanding
Il Natural Language Understanding è il primo stadio dell’elaborazione del linguaggio naturale NLP. In pratica, una volta comprese le intenzioni dell’interlocutore tramite il NLU, il NLP utilizza tale comprensione per generare la risposta appropriata, mantenendo il tono conversativo dell’interazione.
Il NLU è pur sempre una tecnologia basata sulla comprensione del linguaggio naturale, che consente alle chatbot di intendere il linguaggio umano non strutturato. Le chatbot basate sul NLU sono sensibili al contesto, ovvero possono fare a meno delle corrispondenze esatte di parole chiave, riescono a gestire numerose informazioni contenute in frasi complesse, comprendendole anche se nascoste e sono in grado di conservare memoria delle domande precedenti per rendere le conversazioni scorrevoli e naturali.
Conclusioni
La vera sfida e il grande obiettivo è la creazione di sistemi intelligenti e autonomi (cognitive computing), potenzialmente ma non necessariamente, nel corpo di un robot, come già anticipato nell’immaginario collettivo da alcuni film come “Ex Machina”, “Her”,” Transcendence”.



