
Bert (Bidirectional Encoder Representations from Transformers) è un modello di elaborazione del linguaggio naturale, descritto dai ricercatori di Google AI Language in un recente articolo, che ha suscitato scalpore nella comunità del machine learning presentando risultati pioneristici su 11 diverse attività di elaborazione del linguaggio naturale.
Queste attività comprendono: sentiment analysis, named entity recognition, coinvolgimento testuale (ovvero la predizione della frase successiva), etichettatura dei ruoli semantici, classificazione del testo e coreference resolution. Inoltre, sono stati raggiunti ottimi risultati analizzando parole con significati multipli, dette parole polisemiche, questo grazie ad una comprensione più profonda del contesto di riferimento.
Indice degli argomenti:
Bert, che cos’è
Bert in molti articoli è solitamente descritto come un modello di deep learning pre-addestrato, tuttavia lo definirei più correttamente come un framework, poiché fornisce ai professionisti del machine learning, una base per costruire le proprie versioni simil-Bert tramite le quali è possibile soddisfare una vasta gamma di task.
Bert è originariamente pre-allenato sull’intera Wikipedia inglese e sul Brown Corpus ed è stato perfezionato per lo svolgimento di attività di natural language processing. Esso non è quindi un nuovo cambiamento o una miglioria di un algoritmo, quanto piuttosto uno strato fondamentale del processo, che cerca di aiutare a comprendere e chiarire le sfumature linguistiche, perfezionandosi continuamente e adattandosi allo specifico contesto, per un incremento continuo dell’accuratezza.
Bert, l’architettura
Bert, Bi-Directional Encoder Representations Transformers, si basa sull’architettura del transformer (rilasciata da Google nel 2017). Il trasformer utilizza una rete di encoder e decoder ma, poiché Bert è un modello di pre-training, viene utilizzata solo una rete a più livelli di encoder, avente lo scopo di apprendere una rappresentazione del testo di input. Il trasformer si basa sul famoso modulo di multi-head attention, che ha riscosso un notevole successo sia in contesti di visione artificiale che in attività linguistiche.
Sono stati introdotti due modelli nel documento:
- Bert-base – 12 layer (blocchi trasformatore) e 110 milioni di parametri;
- Bert-large – 24 layer e 340 milioni di parametri.
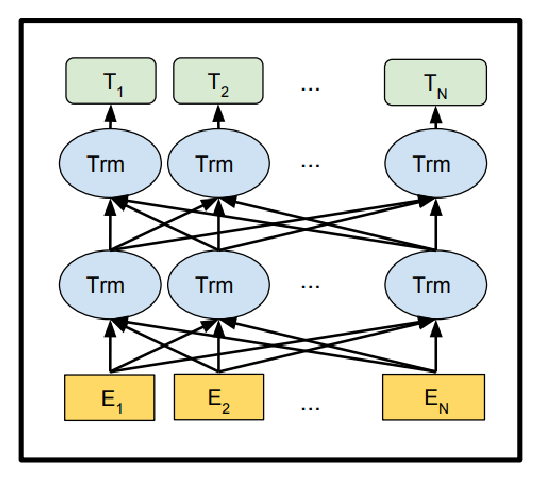
In breve, il modello di Bert, acquisisce ogni parola avente la sua rappresentazione, denominata più propriamente embedding. Ogni livello esegue un calcolo dell’attention sull’embedding delle parole del livello precedente, per poi creare un nuovo embedding intermedio, con le stesse dimensioni degli embedding prodotti dai livelli precedenti. Nella figura, estratta dall’articolo ufficiale, possiamo notare che E1 è la rappresentazione del token considerato, T1 è l’output finale e Trm sono le rappresentazioni intermedie dello stesso token. Ad esempio in un modello Bert a 12 livelli, un token avrà 12 rappresentazioni intermedie.
Masked language modeling e Next sentence prediction
Le prestazioni all’avanguardia di Bert si basano su due punti chiave: innanzitutto nuove strategie di pre-training chiamati Masked Language Model (MLM) e Next Sentence Prediction (NSP), in secondo luogo, l’utilizzo di una grande quantità di dati e di potenza di calcolo per la fase di training.
- Masked Language Model: l’architettura Bert analizza le frasi con alcune parole mascherate casualmente (da qui deriva il nome MLM) e tenta di prevedere correttamente la parola “nascosta”. Durante il training bidirezionale, che passa attraverso l’architettura del trasformatore Bert, lo scopo del MLM è quello di impedire alle parole target di creare inavvertitamente connessioni errate con altre parole, in quanto tutte vengono esaminate nello stesso istante e nel proprio contesto. Questo processo, quindi, ha lo scopo di evitare la creazione di un tipo di loop infinito che potrebbe implicare possibili errori nell’apprendimento automatico del linguaggio naturale, alterando il significato della parola.
- Next Sentence Prediction: una delle principali innovazioni di Bert è quella di essere in grado di prevedere ciò che un utente dirà dopo una determinata frase. La frase viene analizzata e quindi si determina un livello di confidenza necessario per prevedere se una seconda ipotesi di frase “si adatti” logicamente come frase successiva. Questa previsione potrà essere positiva, negativa o neutra.
Nel 50% delle coppie di frasi analizzate, la seconda stringa rappresenta effettivamente la frase successiva del testo, nella restante parte si tratta di una frase scelta casualmente all’interno del documento. Il sistema viene così addestrato a comprendere, se la seconda frase corrisponda alla proposizione immediatamente seguente nel corpo del testo analizzato o se sia inserita casualmente.
Questa funzione, nel modello Bert originale, è stata considerata inaffidabile e altre offerte open source sono state costruite per risolvere questa debolezza (ad esempio Albert di Google e Toyota).
Perché Bert rivoluziona il mondo del NLP
Ci sono diversi elementi che rendono Bert così innovativo per la ricerca di documenti e molti altri task, alcune delle sue possibili funzioni sono descritte nel paper ufficiale Bert: Pre-training of Deep Bidirectional Transformers for Language Understanding.
La comprensione della lingua rimane comunque una sfida ancora aperta, date le numerose ambiguità del linguaggio, come già descritto nell’articolo Natural Language Processing, cos’è, come funziona e applicazioni. Google Bert in questo senso porta la ricerca ancora più avanti, infatti, quella che solitamente per un algoritmo è una sfumatura trascurabile, con Bert assume un significato molto più importante, paragonabile al procedimento che la mente umana effettua nel momento in cui legge o ascolta un determinato termine. Di seguito troviamo dei punti chiave che descrivono come Bert crei un distacco sostanziale dai precedenti approcci NLP.
Pre-training su testo non etichettato
Per quanto riguarda la struttura di Bert, si tratta della prima architettura nel Natural Language Processing a essere pre-addestrata utilizzando un apprendimento non supervisionato su puro testo non strutturato (circa 2,5 miliardi di parole). Con questo tipo di architettura è necessario effettuare solo una fase di fine-tuning per perfezionare task specifici sul linguaggio naturale.
Modelli bidirezionali e comprensione del contesto
La comprensione del contesto da parte di un algoritmo, deriva dalla sua capacità di osservare tutte le parole di una frase nello stesso istante e quindi di capire come ogni singola parola influenzi tutte le altre. Con questa metodologia, il ruolo di una determinata parola all’interno di una frase, può letteralmente cambiare man mano che la frase si sviluppa.
I precedenti modelli addestrati sul linguaggio naturale, sono stati progettati in modo unidirezionale, vale a dire che, il significato di una parola in una finestra di contesto, poteva spostarsi solo in una direzione, da sinistra a destra o da destra a sinistra, ma mai nello stesso momento. Di conseguenza, le parole non ancora osservate all’interno del contesto, non potevano essere prese in considerazione in una frase, ma in realtà avrebbero potuto cambiare il significato di altre parole.
Bert invece, selezionata una parola target, è in grado di prendere in considerazione nello stesso momento tutte le altre parole presenti in quella stessa frase, in maniera quindi bidirezionale. Questo procedimento si può paragonare alla modalità di ragionamento della mente umana, secondo la quale si osserva l’intero contesto di una frase piuttosto che una sola parte.
Concetto di attenzione e utilizzo di un’architettura a transformer
In Bert, il meccanismo di attenzione, consente a ciascun token della sequenza di input, di connettersi con qualsiasi altro token nello stesso momento.
Nell’illustrazione seguente, viene mostrato un esempio del meccanismo di attenzione, la parola “it” attira tutti gli altri token e sembra creare una connessione maggiore con “street” e “animal”.

Questo meccanismo di attenzione, proviene da un documento intitolato “Attention is all you need”, pubblicato un anno prima del documento di ricerca Bert.
In sostanza, Bert è in grado di identificare le parti importanti in un testo, distinguendole da quelle superflue. L’attention aiuta anche a risolvere le ambiguità e la polisemia, utilizzando, rispetto alla parola target, un peso probabilistico basato su tutte le altre parole appartenenti alla stessa frase. A queste parole viene assegnato un punteggio di attenzione ponderato, per indicare quanto peso ognuna di esse, aggiunga al contesto della parola target come rappresentazione del “significato”.
Google, effettuando la seguente ricerca, mostra un esempio:
“2019 brazil traveler to usa need a visa”
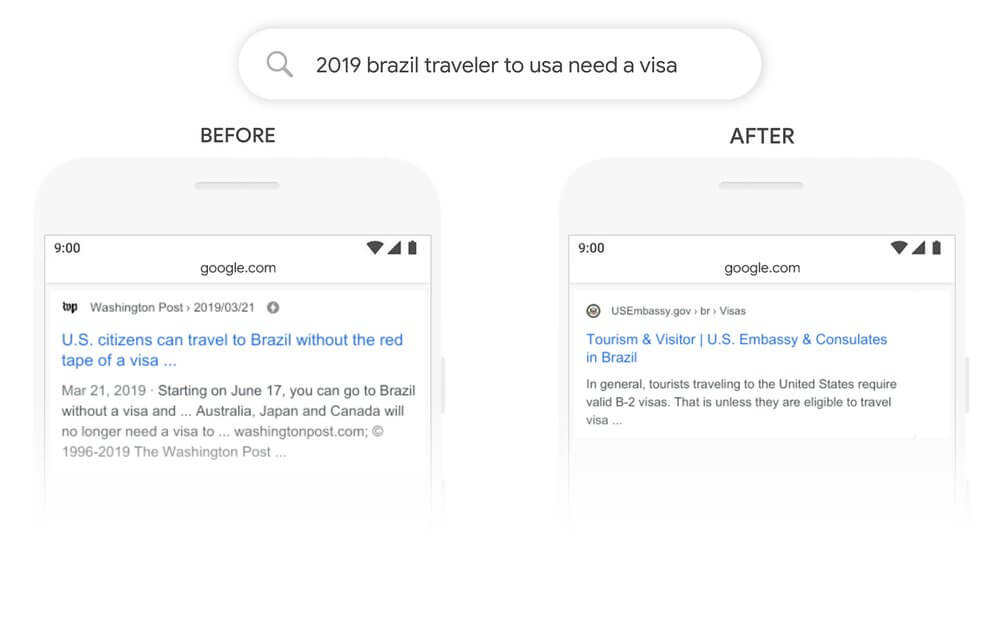
La parola “to” e la sua relazione con le altre parole, sono importanti per comprendere il significato della frase. Precedentemente all’utilizzo del modello Bert, Google non capiva l’importanza di questa connessione e restituiva, erroneamente, risultati sui cittadini statunitensi che viaggiano in Brasile. Con Bert, invece, Google è in grado di cogliere questa sfumatura e di capire che, una parola molto comune nella lingua inglese, come ad esempio “to”, in realtà può essere molto influente, dando la possibilità di fornire un risultato molto più pertinente per la query in questione.
Contributo al mondo Open Source
Oltre a essere il più grande cambiamento nel sistema di ricerca di Google negli ultimi cinque anni (o da sempre), Bert rappresenta probabilmente, anche il più grande passo in avanti nella crescente comprensione contestuale del linguaggio naturale da parte delle macchine.
Bert ha fornito un valore aggiunto per la comprensione del linguaggio naturale, non solo per Google, ma anche per una miriade di ricercatori, sia del mondo accademico che del mondo industriale, in quanto costoro hanno iniziato a utilizzare Bert per molte applicazioni commerciali. Nei soli 12 mesi dopo la pubblicazione, l’articolo originale Bert è stato citato in ulteriori 1997 articoli scientifici, i quali hanno introdotto diverse estensioni al modello, che vanno ben oltre i confini della ricerca Google.
Dopo la pubblicazione, grandi player del mondo dell’intelligenza artificiale hanno contribuito ad estendere Bert, rilasciando al mondo Open Source modelli ancor più accurati: Facebook con RoBERTa, Microsoft con MT-DNN, BERT-mtl di IBM, Google e Toyota con ALBERT, un modello più compatto come DistilBert, ecc.
Tra il 2018 e il 2019, si sono susseguite diverse pubblicazioni di modelli, differenti da quello di Bert, che utilizzano un numero sempre maggiore di dati e di parametri, incentivando così una competizione per raggiungere un nuovo stadio dello stato dell’arte nel NLP, con la necessità di avere sempre più risorse per un training continuo dei modelli, diventando così, una corsa insostenibile. Alcuni esempi di questa competizione in termini di accuratezza sono, l’ultimo modello di Nvidia con 8,3 miliardi di parametri, esso è 24 volte più grande di Bert-Large e 5 volte più grande di GPT-2, oppure RoBERTa, che è stato addestrato su 160 GB di testo rispetto ai 16 GB di Bert. Nonostante questi modelli siano effettivamente più accurati, non è detto che apportino un valore aggiunto in termini computazionali ed economici e che siano realmente efficienti per applicazioni in produzione.
Un discorso differente si può fare per Albert, rilasciato a settembre 2019, con un lavoro congiunto tra Google AI e il team di ricerca di Toyota. Albert è considerato il successore naturale di Bert, poiché riesce a raggiungere una serie di risultati all’avanguardia, in termini di efficienza e costo computazionale, in diverse attività di NLP. Large Albert è 18 volte più piccolo in termini di parametri rispetto a Bert-Large, risultando anche più affidabile nel task di next sentence prediction.
Conclusioni
Bert, come già ripetuto diverse volte, ha rappresentato senza dubbio una svolta nel campo dell’elaborazione del linguaggio naturale. Il fatto che sia facilmente accessibile grazie ai diversi framework e librerie (tensorflow, pyTorch, Keras, ecc.), in diversi linguaggi di programmazione (python, java, C++, ecc.) e consenta un rapido fine-tuning, ci porterà oggi, ma anche nel futuro prossimo, a ritrovarlo in una vasta gamma di applicazioni pratiche. Per coloro che desiderano approfondire i dettagli tecnici e implementativi, consiglio vivamente di leggere l’intero articolo ufficiale e gli articoli correlati a cui si fa riferimento. Altre fonti utili sono il codice sorgente e i modelli Bert, che coprono 103 lingue e sono stati generosamente rilasciati come open source dal team di ricerca.



