
Indice degli argomenti:
L’AI spiegata agli umani
Uno degli ambiti di applicazione dell’intelligenza artificiale che fa più discutere, che genera stupore o avversione a seconda dei casi, è la padronanza del linguaggio naturale da parte delle macchine. Dopo il rilascio dell’estate scorsa, il principale software sul quale si va sempre a parare in questi casi è GPT-3 di OpenAI. A questo si sono aggiunti di recente due nuovi NLP: LaMDA di Google e Wav2vec-U di Facebook.
I vari modelli di linguaggio naturale
Iniziamo subito col dire che quando ci sono di mezzo i giganteschi modelli di linguaggio (noti anche come LLM, Large Language Model) l’accesso alle informazioni avviene spesso col contagocce. Per tornare brevemente al GPT-3 di cui sopra, il software è stato dato in esclusiva a Microsoft – che nel 2019 finanziò OpenAI con un miliardo di dollari – e nonostante un programma di accesso ai ricercatori, molti di noi hanno dovuto arrangiarsi con accessi alternativi, pagando ad esempio provider di terze parti o servizi fortemente limitati, impedendo così adeguate ricerche. Una cosa simile avvenne quando Google presentò Meena come la miglior chatbot di sempre, senza però dare adeguato accesso a chi avesse voglia di testare tale affermazione.
In generale sembra che le grandi aziende siano restie a fornire troppo accesso a chi intenda fare ricerca sui loro LLM. Per molti ricercatori, però, i grandi modelli di linguaggio naturale utilizzati dall’intelligenza artificiale sono un’innovazione troppo importante per essere segregata fra le mura delle multinazionali, che per giunta ne limitano l’uso in base all’umore del momento. Questo ha fatto nascere iniziative come Eleuther.ai, con i suoi progetti GPT-Neo e GPT-NeoX, o come Big Science project, che costruirà un LLM open source sfruttando il supercomputer Jean Zay in Francia. Modelli di linguaggio naturale accessibili a tutti che potranno essere testati e analizzati senza restrizioni.
LaMDA, cos’è, come funziona il linguaggio naturale di Google
Ma torniamo agli annunci dei due colossi della tecnologia. LaMDA (“Language Model for Dialogue Applications”), basato anch’esso, come già BERT e GPT-3 prima di lui, su tecnologia Transformer, nasce dalla necessità di Google di comprendere meglio le intenzioni degli utenti quando fanno partire una ricerca sul web. In termini tecnici si parla di “intento” (questo termine si ritrova anche nella guida autonoma, quando i sistemi AI delle auto driverless cercano di capire l’intento delle altre auto sulla strada), dove una corretta interpretazione dell’intento al primo colpo consente al motore di ricerca di fornire risultati migliori, senza la necessità ulteriori spiegazioni da parte dell’essere umano.
Tutto il lavoro e la ricerca sull’elaborazione del linguaggio naturale hanno portato l’azienda a creare un sistema ancora più performante nell’organizzare e accedere alle informazioni disponibili. Ma capire cosa vuole l’utente e trovare le informazioni giuste è solo una parte dell’equazione. Essere in grado di conversare con l’essere umano sfruttando tali informazioni, comprendendo le sfumature del discorso, offrendo spunti ragionevolmente sensati e soprattutto avendo la capacità di saltare da un discorso all’altro mantenendo lo stesso livello di conversazione, era la parte mancante.
Chi avrà discusso con una chatbot avrà notato che a un certo punto immancabilmente i programmi “si perdono”, oppure non capiscono una sfumatura o un gioco di parole. LaMDA, un’evoluzione del già citato Meena, è in grado, invece, di seguire l’utente anche quando questo salta di palo in frasca, ad esempio iniziando il discorso con un problema tecnico alla lavatrice di casa, per poi cercare di confondere la chatbot con una domanda sui cavalli. Il software di Google se la cava egregiamente, come dimostrato nel blog dell’azienda, indicando che il cavallo potrebbe aiutare l’utente a trasferirsi in una nuova casa. Con una nuova lavatrice.
Come era consueto attendersi, Google limita l’accesso a LaMDA perché, come affermano sul loro blog, “come tutti gli strumenti, potrebbe essere usato male”. Vogliono testarlo ancora. Ma quando sarà pronto, sarà integrato in tutti i maggiori prodotti Google: nel motore di ricerca, negli assistenti digitali, dentro Gmail, Docs e Drive. Speriamo che prima di quel momento Google avrà dato a tutta la comunità di ricerca la possibilità di testarlo a dovere.

LaMDA di Google
Wav2vec-U, cos’è, come funziona il linguaggio naturale di Facebook
Di diverso tipo, invece, il breakthrough tecnologico di Facebook, che ha creato Wav2vec-U, un metodo per creare sistemi di riconoscimento del parlato senza la necessità di avere trascrizioni sulle quali addestrare il modello.
I sistemi di riconoscimento del linguaggio parlato hanno bisogno di una grande quantità di trascrizioni testuali da abbinare all’audio per imparare a quali parole associare quali suoni. Questo, tuttavia, limita l’uso di tali modelli alle lingue che possono mettere a disposizione molte trascrizioni, generalmente le lingue più parlate sul pianeta.
Le lingue meno parlate o i dialetti, invece, non hanno questa possibilità, quindi i modelli di riconoscimento vocale spesso non sono disponibili per tali idiomi, e quando lo sono non offrono le stesse prestazioni. Si stima che sulla terra si parlino oltre 7000 lingue diverse, ma se con sole 23 lingue si riesce a coprire la metà della popolazione mondiale, limitandosi solo a esse si ignora l’altra metà del pianeta. E con un mercato, quello del text-to-speech, che fra pochi anni dovrebbe raggiungere 4,1 miliardi di dollari, occuparsi dell’altra metà del mondo – finora particolarmente snobbata – potrebbe avere ritorni finanziari non da poco.
Il sistema messo a punto da Facebook è basato sull’apprendimento auto-supervisionato, una forma di apprendimento non supervisionato molto cara al francese Yann LeCun, uno dei maggiori ricercatori di intelligenza artificiale al mondo, inventore delle reti neurali a convoluzione nonché capo dell’AI di Facebook. Nell’apprendimento auto-supervisionato è il software, non gli esseri umani, a etichettare i dati forniti all’algoritmo per l’addestramento. Per questo motivo c’è chi lo ritiene una forma di apprendimento supervisionato, ma senza interventi umani.
Wav2vec-U apprende puramente dalle registrazioni audio del parlato e da testo non abbinato, eliminando così la necessità di qualsiasi trascrizione. Dall’input audio il modello impara la struttura del parlato, segmentando la voce in “unità di parlato” che corrispondono grosso modo ai diversi suoni pronunciati.
Quindi si addestra una rete generativa avversaria (o GAN, Generative adversarial network, lo stesso metodo usato per creare i deepfakes) che impara a riconoscere le parole in una registrazione audio. Queste reti sono di solito composte da due reti neurali messe l’una contro l’altra (ecco il perché del termine “adversarial”): un generatore, che crea contenuti, e un discriminatore, che deve decidere se i contenuti sono credibili o meno.
Nel caso di Wav2vec-U il generatore prende ogni segmento audio delle rappresentazioni auto-supervisionate e cerca di prevedere un fonema corrispondente a un suono nella lingua. Il discriminatore, addestrato sia con l’output “inventato” del generatore, sia con testo fonemizzato preso da fonti reali, impara a distinguere cosa è verosimile da cosa non lo è, approvando o respingendo le creazioni del generatore.
Inizialmente le trascrizioni “approvate” dal discriminatore non sono di buona qualità, ma più si va avanti con l’addestramento più aumenta la precisione della GAN, che arriva infine a realizzare trascrizioni molto accurate praticamente in qualsiasi lingua. Nel benchmark TIMIT, che registra il tasso di errore ottenuto da modelli AI per il riconoscimento del parlato, Wav2vec-U è risultato il migliore fra i modelli non supervisionati con un tasso di errore dell’11,3%.
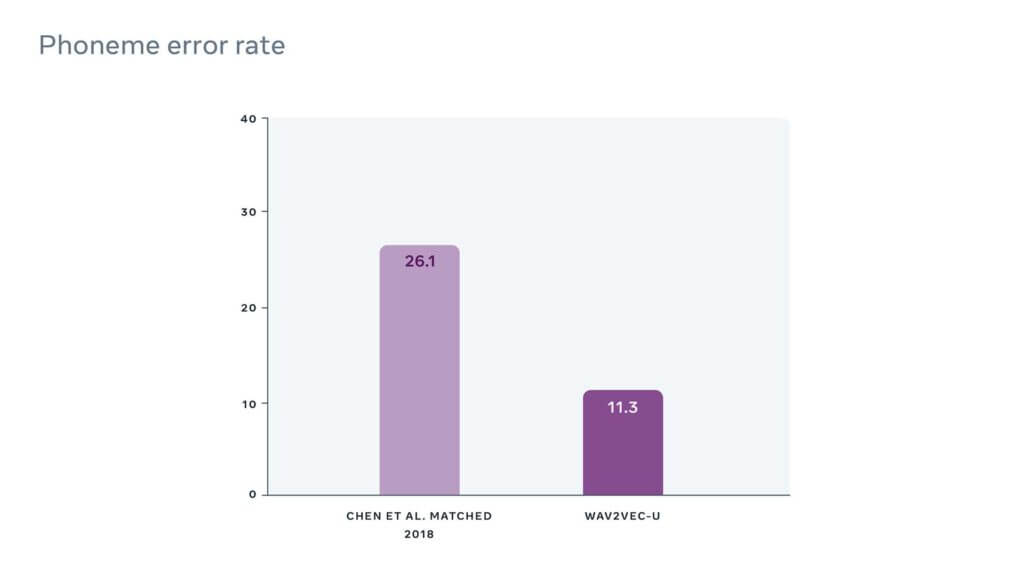
Figura 1: Wav2vec-U rispetto al precedente miglior metodo non supervisionato sul benchmark TIMIT
Le prestazioni non sono ancora ai livelli dei modelli supervisionati, che richiedono però dataset con fonemi e trascrizioni, come mostrano i risultati sul benchmark Librispeech.
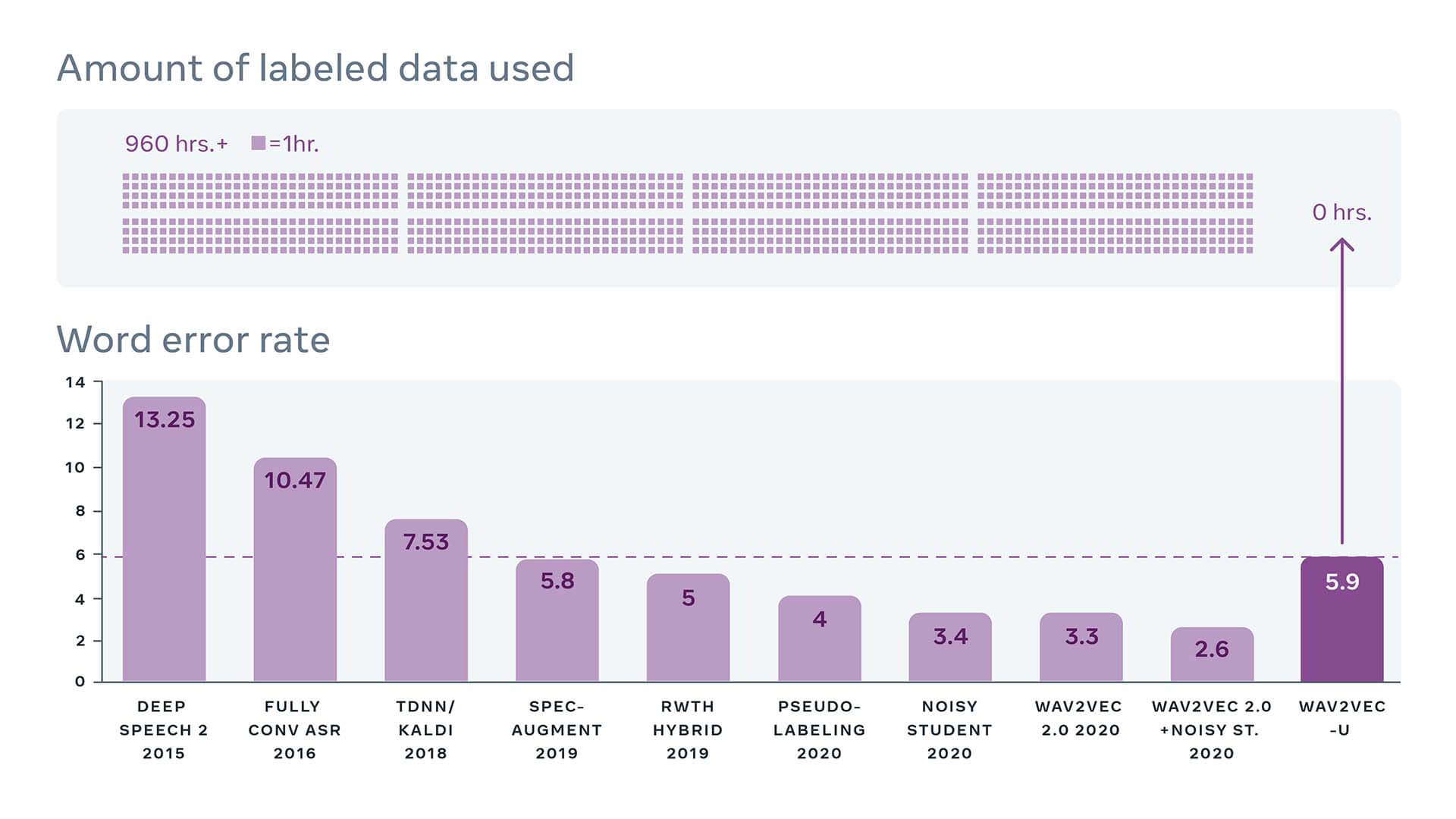
Figura 2: Wav2vec-U sul benchmark Librispeech (test-other) confrontato con i migliori sistemi nel tempo, che tipicamente utilizzano 960+ ore di dati trascritti. Fonte: paperswithcode.com
È vero, tuttavia, che TIMIT e Librispeech si basano sulla lingua inglese, mentre il punto di forza di Wav2vec-U è quello di essere utile per le lingue scarsamente trascritte. Col passare del tempo, poi, non è escluso che il modello inizierà a essere concorrenziale anche per le lingue più frequentemente utilizzate. Nel frattempo, Facebook ha deciso di rendere il sistema open source e ha rilasciato il codice su Github.
Conclusioni
Una delle caratteristiche fondamentali che ci rende umani è il sapiente e complesso uso del linguaggio. Lo impariamo da piccoli, ne comprendiamo le sfumature, siamo in grado di imparare altri idiomi, a comprendere e a farci comprendere da altri esseri umani. Non serve un antropologo per sottolineare l’importanza del linguaggio nel nostro sviluppo e nella nostra società. La lingua parlata fa spesso parte dell’identità di un individuo, esprime l’appartenenza a un gruppo. In certe occasioni non c’è niente di più umano che parlare e ascoltare il prossimo.
Gli sforzi introdotti da Google, OpenAI (finanziata da Microsoft) e Facebook sulla comprensione e sulla generazione del linguaggio naturale ci fanno capire come i big tech ritengano il settore un tassello fondamentale nell’accesso ai loro servizi. Per raggiungere risultati sempre più performanti l’intelligenza artificiale viene già usata molto intensamente in questi sistemi, e la corsa non accenna minimamente a rallentare.



