
Depth Estimation in AI-based Computer Vision: spieghiamo perché è importante considerare per essa un approccio di tipo monocular e quali possono essere potenziali applicazioni pratiche di tale tecnica in alcuni contesti specifici.
Indice degli argomenti:
Depth Estimation, che cos’è
Nonostante la realtà in cui viviamo sia tridimensionale, la quasi totalità dei dispositivi con cui consumiamo contenuti visuali digitali ne propone una visione bidimensionale: una parte di informazioni lungo una delle tre dimensioni, quella relativa alla profondità, viene persa. Questa maniera di rappresentare tutto in due dimensioni va comunque bene in moltissimi casi d’uso, ma presenta dei limiti in alcune situazioni specifiche.
In Computer Vision, la Depth Estimation (che può essere tradotto dall’inglese come calcolo della profondità) è il task relativo alla deduzione della geometria di una scena a partire da una singola immagine bidimensionale. In figura 1, due esempi di rappresentazione visuale delle mappe di profondità generate da modelli di rete neurale dedicati e installati su droni.

Figura 1 – Esempi di mappe di profondità generate da modelli di reti neurali dedicati e installati su un outdoor drone (in alto) e un indoor drone (in basso)
Il cervello umano è in grado di calcolare la profondità confrontando le singole immagini ottenute tramite l’occhio sinistro e quello destro. Il piccolo scostamento tra i due punti di vista gli è sufficiente per poter calcolare una mappa di profondità approssimativa. La coppia di immagini ottenute da entrambi gli occhi viene chiamata coppia stereo. Questa informazione, combinata con l’attività del cristallino, il quale ha lunghezza focale variabile, ci consente di avere una visione 3D senza soluzione di continuità. Un processo quindi naturale per un essere umano, ma decisamente complesso da compiere per una macchina. In che modo é quindi possibile emulare tale processo?
Come la Depth Estimation emula la visione 3D dell’occhio umano
Fino a 2-3 anni fa si sarebbe potuta implementare una soluzione di Depth Estimation affidabile solamente tramite hardware. Esempi in questo caso sono l’utilizzo di molteplici obiettivi anziché uno singolo (come ormai avviene per la maggior parte degli smartphone di fascia media e alta), soluzioni ottiche dedicate (quale ad esempio Dual Pixel), la combinazione di sensori per diversi tipi di segnali (non solo ottici, come ad esempio avveniva per i dispositivi Microsoft Kinect), sensori LIDAR (molto usati soprattutto per applicazioni di veicoli a guida autonoma, a parte Tesla[1]) o sensori a ultrasuoni.
Però non è sempre possibile, in particolare in ambiti industriali o di robotica o UAV, ricorrere a tali soluzioni per diverse ragioni quali aumento dei costi di produzione, impatti sulle prestazioni o sulla usabilità dovuti alla particolare forma o al peso dei componenti aggiuntivi, incompatibilità hardware o software con alcuni dispositivi ed altre ancora. Per fortuna, alcuni fattori quali i progressi degli ultimi anni riguardanti la capacità computazionale locale di dispositivi/macchine, la disponibilità di software open source dedicato, maggiori fondi per la ricerca in computer vision e l’abbattimento dei costi di produzione hardware in serie hanno reso possibile l’implementazione di soluzioni software di Depth Estimation basate su AI e l’installazione ed esecuzione di queste direttamente on the edge.
Monocular vs. Stereo Depth Estimation
Come tutti gli altri modelli di Deep Learning, anche per la Depth Estimation esiste una fase di apprendimento (training) e una di esecuzione (inference). La difficoltà maggiore in questo contesto riguarda la creazione dei dataset per il training. I primi tentativi in questo campo sono stati fatti creando dataset composti da immagini di determinati oggetti/scene ripresi da diverse angolazioni. Come si può facilmente intuire, un processo di questo tipo non è sostenibile in quanto i costi molto elevati per la collezione e il labelling di tali dataset non possono essere ammortizzati facilmente e comunque i modelli finali, una volta mandati in esecuzione in scenari reali, avranno una capacità di generalizzazione nemmeno lontanamente comparabile con quella di un essere umano. Si è passati quindi all’utilizzo di dataset di training composti da singole immagini bidimensionali (da cui l’aggettivo monocular) e a due approcci diversi per la loro preparazione, uno dei quali prevede un apprendimento di tipo supervisionato, mentre l’altro (sul quale la maggior parte dei lavori di ricerca si focalizza ormai) è di tipo semi-supervisionato (se non completamente senza supervisione in alcuni casi).
L’apprendimento supervisionato richiede che il dataset per il training di un modello sia costituito da coppie, ciascuna composta da una immagine bidimensionale di una scena e la corrispondente mappa di profondità. Le mappe di profondità fungono da label per le immagini. Un modello quindi in questi casi viene addestrato a fare una sorta di trasformazione pixel-to-pixel di una scena bidimensionale in una mappa di profondità. Anche la costruzione di un dataset per questo tipo di apprendimento richiede però uno sforzo non indifferente legato alla raccolta delle immagini (che devono essere in numero elevato in modo da coprire quante più possibili situazioni di variazione dello sfondo), ma soprattutto dovuto alla generazione preliminare delle corrispondenti label (mappe di profondità). Motivo per il quale la ricerca si è successivamente quasi completamente focalizzata su algoritmi semi-supervisionati (o addirittura senza supervisione).
Per questi ultimi, i dataset per il training sono composti esclusivamente da immagini bidimensionali di scene di interesse. L’apprendimento di un modello avviene in maniera simile a quanto avviene per gli esseri umani e consta di due fasi. Nella prima fase, le immagini del dataset di training vengono usate come immagini relative a quelle ricevute da un singolo occhio umano (per esempio quello sinistro) e il modello impara a generare l’immagine corrispondente per la stessa scena, ma dal punto di vista dell’altro occhio (il destro). Una volta che un modello è in grado di generare le immagini richieste con la precisione desiderata, nella seconda fase (inference time) queste ultime vengono utilizzate insieme alle immagini di input per formare coppie stereo e un algoritmo esegue quindi il calcolo della differenza fra le due immagini, in termini di scostamento di pixel (o blocchi di pixel) tra le due immagini di una coppia.
Come si calcola la profondità di ogni elemento presente nell’immagine
Usando tali valori è quindi possibile calcolare la profondità di ogni elemento presente nell’immagine di partenza. Dalla descrizione di questo processo si evince che la creazione dei dataset di training è meno complessa e costosa rispetto ad altre metodologie descritte in precedenza e che un modello di questo tipo sia in grado di generalizzare un po’ meglio rispetto a uno addestrato con un approccio supervisionato. Oltre a proporre nuovi modelli di Monocular Depth Estimation più accurati, i ricercatori in questi ultimi anni si stanno dedicando anche alla ottimizzazione di tali modelli per poter eseguire in real-time o quasi real-time, anche in condizioni di illuminazione artificiale in interni e su dispositivi generici con limitazioni hardware in termini di processori, memoria e storage.
In figura 2, un esempio di un modello stato dell’arte proposto dal Toyota Research Institute[2] che non richiede elevate capacità di calcolo per l’esecuzione, pur mantenendo ottime prestazioni.


Figura 2 – A sinistra, immagine bidimensionale di input in interno catturata dal dispositivo; al centro, la rappresentazione grafica della mappa di profondità generata dal modello installato su un dispositivo con medie caratteristiche hardware; a destra, la rappresentazione grafica della mappa di profondità generata da una versione dello stesso modello ottimizzata per dispositivi con basse caratteristiche hardware
Un approccio combinato
Durante l’edizione 2020 della ECCV (European Conference on Computer Vision) Niantic, l’Università di Edimburgo e UCL hanno proposto un approccio combinato che mette insieme i punti di forza di entrambe le metodologie (apprendimento supervisionato e semi-supervisionato) appena descritte. L’idea proposta consiste nell’eseguire prima l’apprendimento di un modello di rete neurale in modo che questo impari a generare, partendo da una singola immagine, la seconda con cui andrà a formare una coppia stereo. Da queste vengono ricavate le corrispondenti disparity maps. In questo modo è quindi possibile generare dataset stereo sintetici a partire da qualsiasi collezione di immagini RGB esistente senza operazioni manuali e utilizzarli successivamente per un training di tipo supervisionato. Dataset sintetici di questo tipo generati tramite reti neurali sono inoltre molto più realistici di quelli generati manualmente e consentono di migliorare la capacità di generalizzazione dei modelli finali. Il diagramma in figura 3 riassume tale approccio.
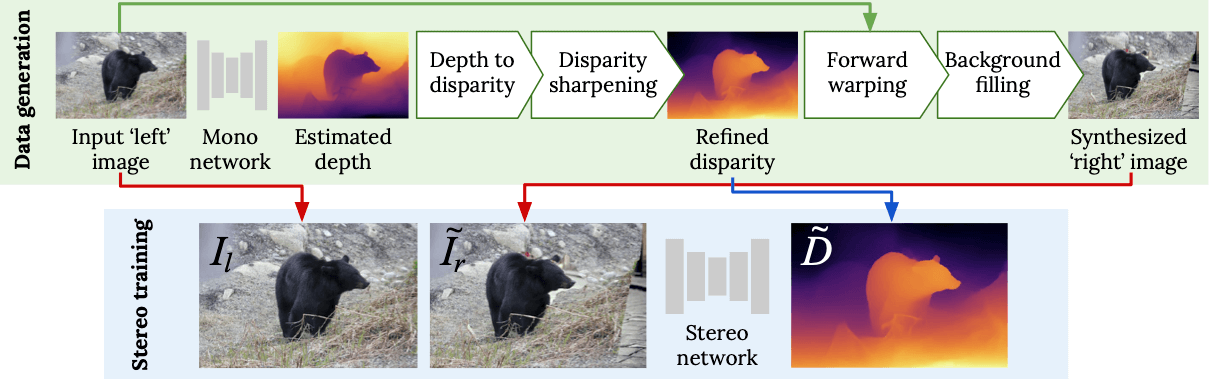
Figura 3 – Processo di generazione di dataset stereo sintetici e training utilizzando gli stessi
Applicazioni pratiche di Monocular Depth Estimation
Depth Estimation è un task che ha tanti campi di applicazione, sia direttamente che indirettamente, in quanto esso sta alla base di altri task. Ecco una lista (non esaustiva) dei casi d’uso più comuni:
- realtà aumentata
- qualsiasi ambito di navigazione autonoma (automobili, robot, droni) in ambienti interni o esterni
- calcolo della traiettoria di oggetti in movimento
- interazione di cobot con persone o oggetti in movimento
- calcolo di distanze
- analisi di immagini/video provenienti da apparecchi medicali o microscopi elettronici
- fotoritocco
- rimozione di fenomeni naturali, quali pioggia o nebbia, da immagini/fotogrammi
- warehouse automation
- ricostruzione di scene video bidimensionali da diverse angolazioni
- point cloud reconstruction a partire da immagini bidimensionali
Nelle figure 4 e 5 due esempi di applicazioni pratiche che coinvolgono Depth Estimation per poter completare il task finale.

Figura 4 – Segmentazione e classificazione di materiali dentro contenitori quasi trasparenti: depth estimation è parte del processo.

Figura 5 – Calcolo della postura di esseri umani: depth estimation viene utilizzata per calcolare distanze.
Note



