
Salesforce ha presentato una serie di modelli di intelligenza artificiale in grado di gestire documenti con un massimo di 1,5 trilioni di token. La famiglia di modelli XGen-7B è in grado di gestire i dati non strutturati meglio di LLaMA di Meta.
Le aziende potrebbero trarre vantaggio dall’avere un’interfaccia di chat come ChatGPT o Bard in grado di riassumere lunghi documenti o di setacciare i dati dei clienti alla ricerca di approfondimenti. Ma per svolgere compiti come questi, i modelli devono essere addestrati su grandi quantità di dati. Le aziende hanno invece optato per modelli più piccoli ed economici, che non sono in grado di gestire bene tali compiti.
I modelli open source come LLaMA, Falcon-7B e MPT-7B di Meta sono stati addestrati con una lunghezza massima della sequenza di circa 2.000 token, ovvero unità di base del testo o del codice, rendendo difficile la gestione di dati non strutturati lunghi come un documento.
XGen-7B, famiglia di modelli linguistici di grandi dimensioni di Salesforce, è in grado di gestire più facilmente gli input di documenti lunghi grazie all’addestramento con “attenzione densa standard” fino a una lunghezza di 8.000 sequenze per un massimo di 1,5 trilioni di token.
I ricercatori di Salesforce hanno preso una serie di modelli da sette miliardi di parametri e li hanno addestrati sulla libreria interna di Salesforce, JaxFormer, e su dati didattici di dominio pubblico.
Il modello risultante ottiene risultati comparabili o migliori rispetto a modelli open source come LLaMA, Flacon e Redpajama.
I ricercatori di Salesforce hanno dichiarato che il modello è costato solo 150mila dollari per l’addestramento su 1.000 miliardi di gettoni utilizzando la piattaforma di cloud computing TPU-v4 di Google Cloud.
Indice degli argomenti:
I risultati di Salesforce XGen-7B
Il modello di Salesforce ha ottenuto risultati impressionanti, superando i più diffusi modelli linguistici open source su una serie di benchmark.
Nel benchmark Measuring Massive Multitask Language Understanding (MMLU), XGen ha ottenuto il miglior punteggio in tre delle quattro categorie testate e nella media ponderata. Solo LaMA di Meta ha ottenuto un punteggio superiore a quello di XGen nel test MMLU relativo alle discipline umanistiche.
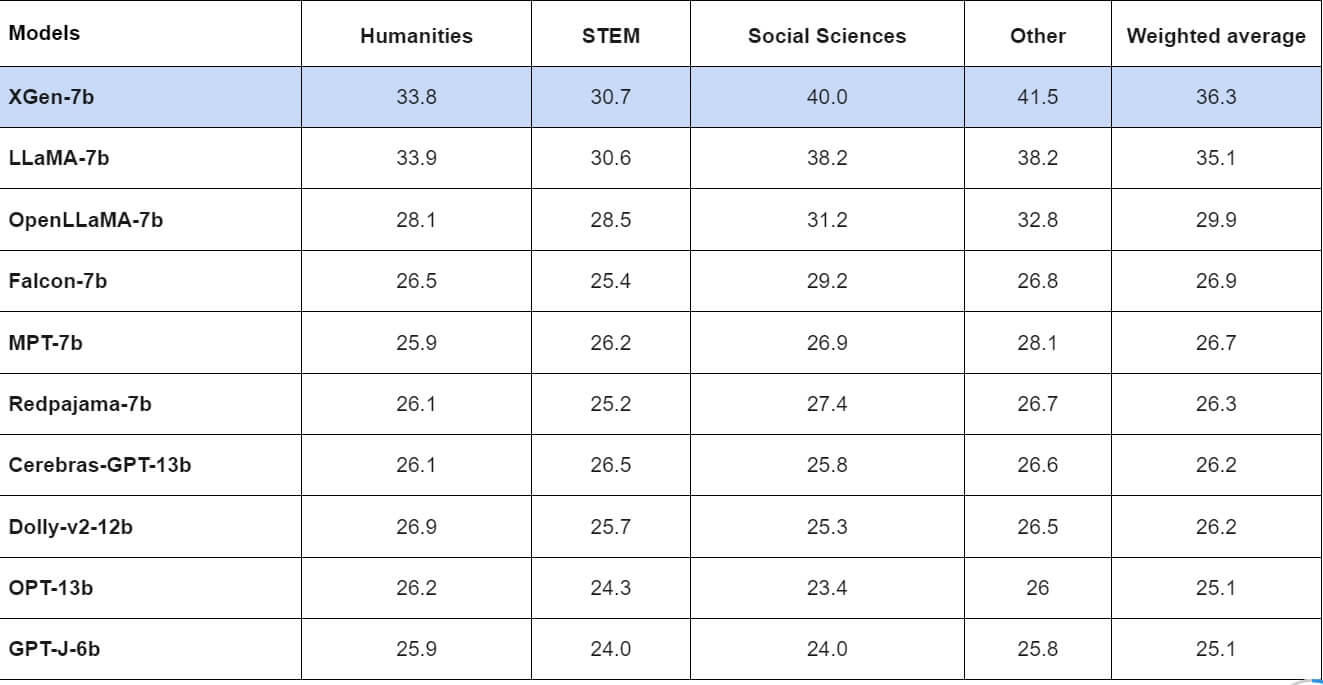
Nel test a zero scatti dello stesso benchmark, XGen ha ottenuto risultati simili, perdendo ancora una volta contro LLaMA nelle materie umanistiche.
In termini di test complessivi a zero colpi, XGen ha superato ogni altro modello solo nel benchmark TruthfulQA. LLaMA di Meta ha ottenuto risultati migliori nei benchmark ARC_ch, Hella Swag e Winogrande.
Tuttavia, nei compiti di generazione del codice, XGen ha surclassato LLaMA e altri modelli, ottenendo un punteggio di 14,20 sulla metrica pass@1 del benchmark HumanEval. LLaMA è riuscito a ottenere solo 10,38.
Le attività a lunga sequenza sono quelle in cui il nuovo modello di intelligenza artificiale di Salesforce ha brillato di più, ottenendo punteggi incredibili nei dataset QMSum e GovReport del benchmark SCROLLS.
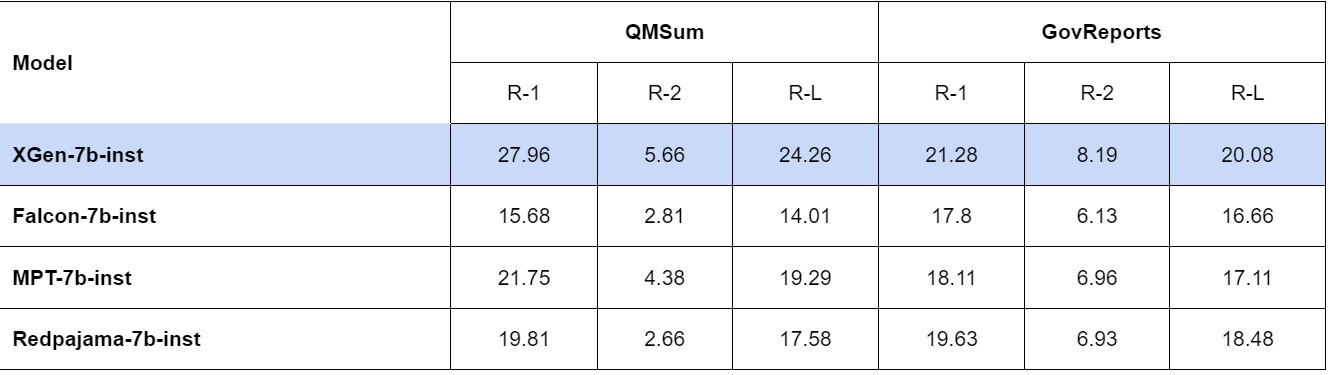
Tuttavia, i ricercatori di Salesforce hanno notato che, poiché i modelli XGen non sono stati addestrati sugli stessi dati didattici, “non sono strettamente comparabili”.
La famiglia XGen-7B
I ricercatori di Salesforce hanno creato tre modelli: XGen-7B-4K-base, XGen-7B-8K-base e XGen-7B-inst.
XGen-7B-4K-base è in grado di gestire 800 miliardi di token di contesto, essendo stato addestrato su 2.000 e successivamente 4.000 token di lunghezza di sequenza. È stato rilasciato con licenza Apache-2.0, il che significa che le opere derivate possono essere distribuite con una licenza diversa, ma tutti i componenti non modificati devono utilizzare la licenza Apache 2.0.
XGen-7B-8K-base ha visto il modello precedente arricchirsi di altri 300 miliardi di token, portando la sua capacità totale di comprensione contestuale a 1,5 trilioni di token. Anche questo modello è stato rilasciato sotto Apache 2.0.
XGen-7B-inst è stato messo a punto su dati didattici di dominio pubblico, compresi i databricks-dolly-15k, oasst1, Baize e i dataset relativi a GPT. Il modello è stato addestrato su 4.000 e 8.000 token ed è stato rilasciato esclusivamente a scopo di ricerca.
Per addestrare i modelli, i ricercatori di Salesforce hanno utilizzato una strategia di addestramento in due fasi, in cui ogni fase utilizzava una miscela di dati diversa.
Il team ha spiegato che: “Per C4, abbiamo elaborato 6 dump di Common Crawl con la pipeline C4 e decuplicato i documenti tra i diversi dump mantenendo solo il timestamp più recente per i documenti con lo stesso URL. Abbiamo addestrato un modello lineare che classifica i dati di C4 come documenti simili a Wikipedia o come documenti casuali. Abbiamo poi scelto il 20% dei documenti simili a Wikipedia”.
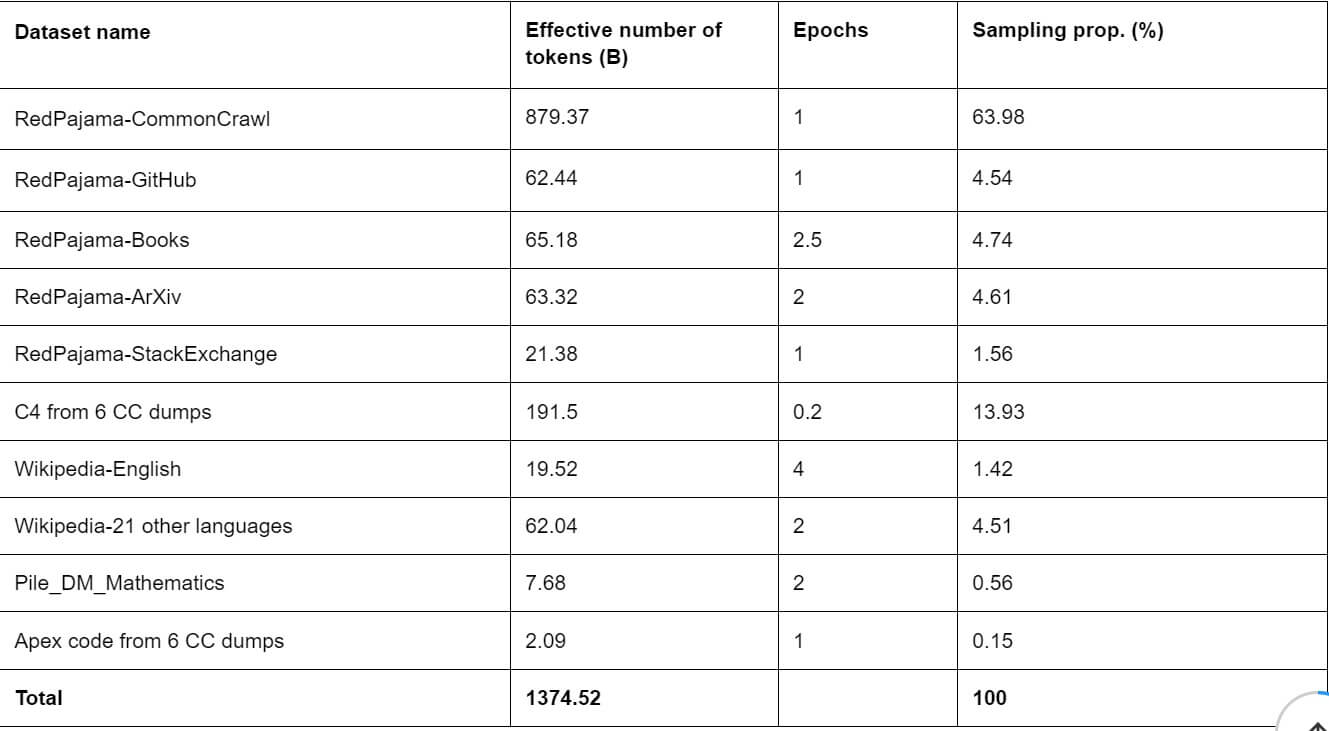
È stato poi aggiunto Starcoder, il modello di generazione del codice creato da Salesforce e Hugging Face, per supportare le attività di generazione del codice. I dati fondamentali di Starcoder sono stati poi mescolati con quelli della fase precedente.
OpenAI tiktoken è stato usato per tokenizzare i dati del modello. In seguito, sono stati aggiunti altri token per gli spazi bianchi consecutivi e le tabulazioni.
Sebbene il processo di formazione XGen porti a una serie di potenti modelli di intelligenza artificiale, non è privo di difetti. Salesforce ha notato che il modello soffre ancora di allucinazioni.
Per saperne di più su XGen-7B, Salesforce ha pubblicato un blog post dettagliato sul modello. La base di codice del modello è disponibile su GitHub e i checkpoint del modello sono disponibili su Hugging Face.
Più contesto uguale più conversazione
I modelli in grado di comprendere input più lunghi potrebbero rappresentare un enorme vantaggio per le aziende.
Secondo i ricercatori di Salesforce, un contesto ampio “consente a un LLM preaddestrato di esaminare i dati dei clienti e di rispondere a utili richieste di informazioni”.
Per le applicazioni chatbot, più contesto significa più conversazione. E Salesforce non è l’unica organizzazione che sta studiando questo concetto. Anthropic, la startup di AI in ascesa fondata da ex allievi di OpenAI, ha recentemente ampliato la lunghezza del contesto della sua applicazione di punta, Claude.
Claude può ora essere utilizzato per recuperare informazioni da più documenti o libri aziendali lunghi, con gli utenti in grado di porre domande al bot sui dati.
I modelli attuali hanno difficoltà a gestire contesti sempre più lunghi. Con la nascita di applicazioni come ChatGPT e la chat AI di Bing, gli utenti si sono accorti che più a lungo utilizzavano il modello in una singola conversazione, più le sue risposte diventavano sballate. Ciò era dovuto al fatto che il modello non era in grado di gestire la lunghezza del contesto, causando confusione e quindi allucinazioni.
Casi come le risposte inappropriate di Bing, segnalate a maggio, hanno costretto Microsoft a limitare il numero di conversazioni che gli utenti potevano avere con l’applicazione, che non era in grado di gestire lunghe conversazioni contestuali.


