
- Differenze tra progetti AI e altri progetti IT: i progetti di sviluppo AI sono sostanzialmente diversi da quelli tradizionali come web app o software gestionali. La complessità e l’incertezza legate alla fattibilità e alle performance dei modelli di machine learning richiedono una pianificazione accurata e specifica.
- Un progetto AI si sviluppa attraverso diverse fasi: Assessment, Prototipazione, Sviluppo, Testing, Deploy e Manutenzione. Ogni fase ha specifiche attività e obiettivi, con un focus particolare sull’Assessment per valutare la fattibilità e ridurre i rischi.
- I progetti AI possono incorrere in errori comuni come obiettivi non chiari, dati insufficienti o sbilanciati, label inaccurate, addestramento su distribuzioni di dati diverse, metriche fuorvianti, mancanza di studio dell’errore e variabilità temporale ignorata. Riconoscere e affrontare questi problemi è cruciale per il successo del progetto.
I progetti che coinvolgono lo sviluppo di modelli di machine learning non sono come tutti gli altri. Implementare un modello AI è di fatto molto diverso da sviluppare una web app, un servizio o un gestionale. Se per questi ultimi il risultato è pressoché certo, senza nulla togliere alla complessità che ne può scaturire, alla corretta stima di tempi e risorse e alle scelte tecnologiche più adatte, per lo sviluppo AI nulla è scontato, né dal punto di vista della fattibilità né delle performance. Per questo motivo anche la pianificazione di un progetto AI differisce in modo sostanziale da quella degli altri progetti IT.
Indice degli argomenti:
Progetto di AI, le fasi principali
Le fasi principali su cui si sviluppa il progetto AI sono:
- Assessment
- Prototipazione
- Sviluppo
- Testing
- Deploy
- Manutenzione.
Assessment, Prototipazione e Sviluppo
La fase di Assessment dei progetti AI è una delle più importanti poiché definisce la fattibilità dell’intero progetto, e comprende le seguenti attività:
- analisi dei requisiti funzionali del cliente
- traduzione dei requisiti funzionali in requisiti tecnici del modello
- definizione di una metrica di riferimento su cui validare il modello
- ricerca di paper e articoli scientifici sullo stato dell’arte nel campo di applicazione richiesto
- censimento e studio di tutti i dataset disponibili.
In linea di massima, il risultato dell’assessment costituisce una solida base di conoscenza che permette di stabilire se intraprendere o meno l’intero progetto, riducendo una buona parte dei rischi legati all’incertezza del risultato. La fase di prototipazione, come suggerisce la parola, ha come scopo quello di creare il prototipo del modello AI, mettendo in pratica le strategie più promettenti scaturite dall’assessment. Il processo è un ciclico ripetersi delle seguenti attività, fino al raggiungimento dei risultati attesi: scelta dell’algoritmo ML o dell’architettura AI più adatta, pre-processing dei dati, addestramento sui dati di training, valutazione delle performance sui dati di test e studio dell’errore di inferenza.
Il raggiungimento delle performance definite in fase di assessment, interrompe il ciclo e determina il rilascio del prototipo. Solitamente, in questo frangente viene organizzata una PoC (Proof of Concept) nella quale il cliente ha modo di vedere il prototipo in azione e valutarne la qualità. È bene tenere a mente che la dimostrazione ha luogo in un ambiente controllato, spesso soggetto a molte limitazioni e ben diverso dalle condizioni di operatività caratteristiche di un ambiente di produzione. Tale presupposto è alla base della successiva fase di sviluppo vero e proprio. In questa fase il prototipo viene trasformato in prodotto: viene implementata l’architettura software che ospita il modello, le eventuali interfacce utente, un robusto sistema di monitoraggio e di “versioning” delle release del modello e l’allaccio ai dati reali di produzione.
Testing, Deploy e Manutenzione
Qui, accanto al lavoro dei data scientist e degli ingegneri AI, si intercettano anche altre figure professionali tipiche dell’ecosistema IT quali: data engineers, devops, full stack developers e web designers. La fase di Testing, una volta completato lo sviluppo, consiste nel testare l’intero sistema nell’ambiente di collaudo e comprende le attività di identificazione e risoluzione dei bug e la misurazione delle performance AI con i dati di produzione. Sovente, in questo momento cruciale del progetto ci si rende conto che il modello ha ancora molti difetti, ma è bene chiarire subito che questo comportamento è del tutto normale. Per fronteggiare questi problemi, vengono analizzati gli errori, vengono acquisiti i nuovi dati e viene programmato un nuovo ciclo di addestramento spesso chiamato fine-tuning. Il tutto con il vantaggio che il sistema è già in ambiente operativo e può contare sul feedback del cliente o degli esperti di dominio.
Alla fine di questo circolo virtuoso di aggiustamenti, si può procedere con la fase di Deploy dove l’intero sistema viene rilasciato in produzione. Da qui in poi inizia la lunga fase di monitoraggio e manutenzione, tipica di ogni progetto IT.
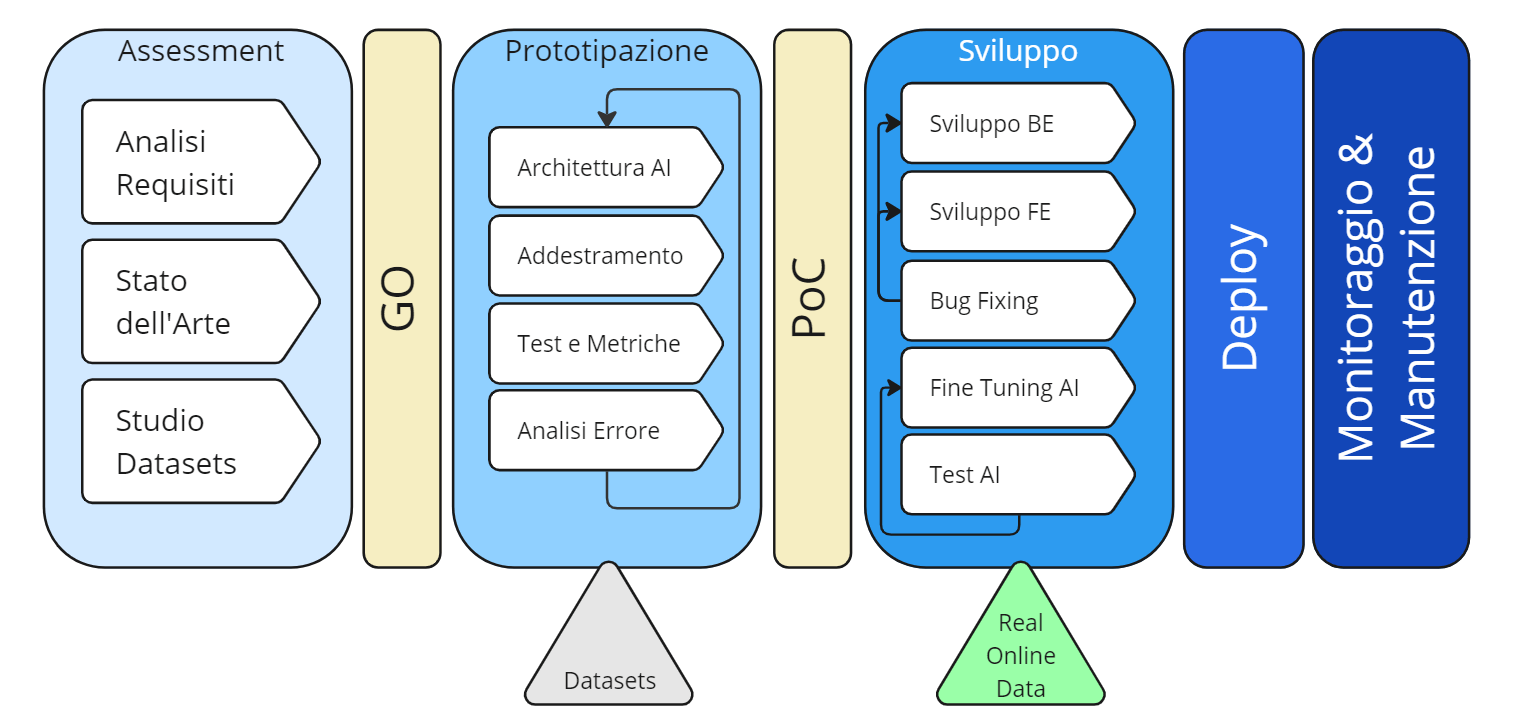
Figura 1: Schema delle fasi di un progetto AI (Autore: Giovanni Nardini)
Alla luce delle dinamiche che intercorrono nella pianificazione ed esecuzione di un progetto AI, esistono una serie di problematiche ed errori molto comuni dai quali mettersi in guardia. Vediamone alcuni, cercando di capire come evitarli.
Gli errori più comuni in un progetto AI e come evitarli
- Non avere un’idea chiara degli obiettivi. Nella fase di assessment, si è chiamati a tradurre i requisiti funzionali in requisiti tecnici. Un modello di machine learning è quasi sempre caratterizzato da un input e un output; pertanto, è importante stabilire una comunicazione chiara ed efficacie al fine di identificare insieme un quesito tecnico ben preciso. La frase “voglio applicare l’intelligenza artificiale ai miei dati per migliorare la mia customer experience” deve tradursi per esempio in “voglio predire il grado di soddisfazione dei miei clienti a fronte delle recensioni che pubblicano sul mio sito“. Si è passati da una richiesta generica ad una piena identificazione e condivisione degli obiettivi.
- Mancanza di dati sufficienti, dati incompleti o sbilanciati. “Chi ha i denti non ha il pane” è la frase che più si addice alla casistica. Sviluppare un modello AI significa anche avere una buona base di dati e non è raro che il cliente non ne abbia a sufficienza o non ne abbia proprio. Molto dipende dalla tipologia di task che si vuole implementare: se si tratta di problemi comuni e ampiamente affrontati in letteratura, è molto plausibile trovare dei modelli pre-addestrati da adattare facilmente alla ridotta mole di dati che si ha a disposizione. Un esempio preso in prestito dalla computer vision potrebbe essere quello di un modello di detection delle persone all’interno delle immagini di una telecamera: ad oggi queste tipologie di modelli già addestrati sono ampiamente disponibili con licenze open, per cui non occorrerà chiedere alcun tipo di dato al cliente. Al contrario, in caso di richieste particolari e calate su problemi specifici, sarà necessario studiare a fondo la base dati fornita per comprendere se essa sia sufficiente o meno. Qualora non fosse sufficiente, si può sempre optare per un’integrazione di dati provenienti da altre fonti o la generazione di dati sintetici.
- Mancanza di label o annotazioni poco accurate. Soprattutto nel caso di sistemi ai supervisionati, oltre all’importanza di avere un buon bacino dati, è necessario che questi ultimi siano provvisti di quello che in gergo tecnico viene chiamato Label. Un modello di classificazione, ad esempio, deve conoscere le categorie nelle quali ricadono i singoli record in modo da poter imparare a classificare i contenuti. Se queste annotazioni mancano o sono carenti, le uniche soluzioni possibili sono: annotare manualmente ciascun record, affidarsi a servizi di labeling a pagamento (sono disponibili molte opzioni sui principali provider Cloud quali AWS, Azure e Google Cloud Platform) o fornire al cliente un’interfaccia grafica sulla quale poter taggare i propri record con il relativo label.
- Addestramento e test su distribuzioni diverse di dati. “Non scambiare mele con pere“. Se il modello viene addestrato unicamente su dati provenienti da una determinata distribuzione, è verosimile aspettarsi un comportamento diverso se testato con una distribuzione diversa. Per comprendere al meglio il problema, si consideri un esempio puramente speculativo di un modello di riconoscimento delle targhe automobilistiche. Se addestrato con dataset di targhe americane e testato con dataset di targhe europee il disastro è inevitabile. La soluzione? Al di là della banalità di tale esempio, in cui basterebbe addestrare su un subset di targhe costituito dal mix delle due tipologie, è fortemente raccomandato lo studio delle distribuzioni dei dati che si hanno a disposizione in modo tale da selezionare un set di training che rispecchi quanto più possibile le peculiarità che si prevedono nei dati di produzione.
- Metriche di performance fuorvianti. Si potrebbe dire che “Non è tutto oro quel che luccica” soprattutto quando le metriche sono sbagliate. È fondamentale, già in fase di assessment, stabilire degli indici che siano in grado di misurare in modo chiaro e obbiettivo la capacità del modello di rispondere correttamente in fase di inferenza. Per semplificare la comunicazione con i meno esperti, soprattutto nell’ambito della classificazione, un indice a cui si ricorre spesso è l’accuratezza, che viene definita come la percentuale di record correttamente classificati rispetto al totale dei record di test. Eppure, un esempio di metrica fuorviante è proprio quest’ultima: difatti se i record di test fossero costituiti per il 95% dalla classe A e per il restante 5% dalla classe B, anche un finto modello predisposto per rispondere costantemente con A, mostrerebbe un’accuratezza del 95%, pur trattandosi di un fake. Di qui l’esigenza di accostare sempre all’accuratezza anche altre metriche quali la precisione, il richiamo e l’F1 score. Questo vale sia per i casi più semplici che per i casi più complessi, dove le metriche sono anche di difficile interpretazione e occorre pertanto un solido background matematico.
- Mancanza di uno studio dell’errore. “Sbagliando s’impara” non solo nella vita ma anche nel machine learning. Anzi, a dirla tutta, anche la dinamica di addestramento di un modello è caratterizzata da una continua attività di correzione degli errori. Per cui, a maggior ragione, se il modello addestrato restituisce un numero elevato di errori in fase di test, è di fondamentale importanza indagare e porsi le domande giuste. Tentare di cambiare i parametri, modificare la distribuzione dei dati di training o le tecniche di pre-processing, senza aver prima compreso i motivi che hanno spinto il modello a dare le risposte sbagliate rischia di condurre a un loop senza fine, frustrante per il data scientist e costoso per l’azienda. Una buona pratica è quella di ispezionare i record responsabili delle basse performance, alla ricerca di pattern comuni. Esistono inoltre numerose tecniche di Explainable ai, che mirano a comprendere le dinamiche interne dei modelli, mettendo in luce correlazioni utili tra le caratteristiche del dato e le risposte del modello.
- Mancanza di un approccio modulare. Quando ci si confronta con problemi complessi, la tentazione è quella di sviluppare un unico modello end-to-end in grado di risolverli. È indubbiamente una soluzione molto elegante ma ben presto ci si accorge dei limiti di tale approccio. Il consiglio è quello di suddividere i requisiti funzionali in tanti piccoli problemi più semplici e assegnare un modello a ciascuno di essi. Questo permette di concentrarsi su un problema alla volta, senza considerare i vantaggi in termini di scalabilità e parallelizzazione del calcolo una volta rilasciato il modello in produzione.
- Ignorare la variabilità temporale. Può succedere che un modello rilasciato in produzione mostri delle performance impeccabili, salvo poi subire un crollo di tutti gli indici a distanza di un certo periodo di tempo. È bene considerare in anticipo che il fenomeno modellato possa essere caratterizzato da comportamenti diversi nel tempo, magari di natura ciclica o monotòna. Se il sospetto è fondato, occorre studiare a fondo i dati pregressi per rilevare questa variabilità e costruire un dataset di addestramento che contempli tutti i possibili comportamenti.
Conclusioni
Come osservato fin qui, molte sono le insidie che possono nascondersi dietro a un progetto AI e l’arma più potente sta nel riconoscerle al fine di apportare le dovute correzioni. I progetti che coinvolgono l’intelligenza artificiale stanno subendo un incremento notevole negli ultimi anni, per cui occorre saper cogliere le numerose opportunità di sviluppo che i vari settori offrono, e farsi trovare preparati in modo da poter affrontare le sfide che accompagnano quella che ormai viene definita come la quarta rivoluzione industriale.


