
La diffusione dell’uso di tecniche di intelligenza artificiale è ormai pervasiva e inarrestabile. Tuttavia, essa porta con sé opportunità ma anche rischi e problemi che devono essere affrontati per non comprometterne un’evoluzione efficace. L’eXplainable AI (XAI) è una delle risposte a questi problemi per riavvicinare l’uomo alle macchine.
Indice degli argomenti:
AI, ML, AGI: tante sigle che possono generare confusione
Oggi tutti parlano di intelligenza artificiale (AI). Il termine, purtroppo, è generico e fuorviante perché richiama alla mente il paragone con l’intelligenza umana, ma questo paragone ha senso solamente per quel settore di studio che viene più correttamente indicato con il termine AGI (Artificial General Intelligence). Si tratta di un argomento estremamente affascinante e controverso, sebbene la strada per arrivare a un’intelligenza artificiale paragonabile a quella del cervello umano appaia ancora molto lunga, piena di incognite, rischi ma anche opportunità.
Molto note a tal proposito sono le posizioni allarmistiche di Stephen Hawking e di Elon Musk. A fronte di questi rischi sono nate anche organizzazioni come FLI (Future of Life organization) o OpenAI con lo scopo di seguirne gli sviluppi e analizzarne e discuterne caratteristiche, opportunità e rischi.
Durante la prima conferenza di FLI, “The Future of AI: Opportunities and Challenges” (2015) è emerso chiaramente il fatto che la sicurezza dell’AI è un argomento critico e richiede particolare attenzione, impegno e serietà per fare in modo che l’intelligenza artificiale rappresenti un reale vantaggio per l’umanità e non un rischio.
A differenza dell’AGI, l’intelligenza artificiale di cui normalmente si parla e che già pervade molti settori, dovrebbe essere chiamata più correttamente “narrow”. Si tratta infatti di tecniche di apprendimento automatico (machine learning) che non sono nuove per la comunità scientifica ma che negli ultimi anni sono “maturate” e divenute efficaci per applicazioni specifiche (da cui il termine “narrow”) grazie alla disponibilità di molti dati (esplosione dei big data e dell’IoT) e di ingenti potenze di elaborazione a costi sempre più contenuti.
Explainable AI (XAI): una necessità concreta
La potenza e l’impatto dirompente dell’AI causa preoccupazioni su molti fronti. A quanto descritto in precedenza si aggiungono infatti altre paure legate all’impatto sociale che queste tecniche possono avere, ad esempio in ambito forza lavoro e privacy.
L’insieme di queste considerazioni, collegate agli aspetti di affidabilità analizzati in precedenza, hanno portato a discussioni sempre più frequenti e animate in relazione alla necessità di avere un’intelligenza artificiale “responsabile”. Le discussioni si sono concentrate sulle garanzie di un uso etico, trasparente e responsabile delle tecnologie di AI che siano coerenti con le aspettative degli utenti, i valori organizzativi, le leggi e le norme della società.
Di fatto la natura di alcuni dei sistemi di intelligenza artificiale più promettenti, non riuscendo a salvaguardare l’etica e la trasparenza, possono erodere la fiducia ostacolando in definitiva l’adozione di massa dell’AI.
Questo non è accettabile né per la società e neppure per le imprese per le quali l’AI sta diventando una capacità aziendale richiesta, un fattore critico di successo, non solo qualcosa di “bello da avere”. Le aziende non hanno più la possibilità di evitare i rischi dell’AI semplicemente facendone a meno, devono imparare a identificarne e gestirne i rischi in modo efficace. Devono definire un piano per l’AI istituendo un quadro etico e creando un linguaggio comune attraverso il quale gestire la fiducia e contribuire a garantire l’integrità dei dati tra tutti gli stakeholder, interni ed esterni. Solo così le aziende potranno applicare una governance dell’AI per tutta l’azienda garantendone un’adozione più rapida e coerente. Questo è in linea con un recente sondaggio di PwC nel quale la stragrande maggioranza (82%) degli amministratori delegati concorda sul fatto che le decisioni basate sull’AI per essere affidabili devono necessariamente essere spiegabili.
Capire perché e come un sistema fa previsioni e prende decisioni diventa quindi un elemento essenziale per accelerare l’innovazione e sfruttare appieno il potenziale dell’AI anche se occorre tener presente che, allo stesso tempo, si aprono le porte alla possibile diffusione di preziose proprietà intellettuali.
Nasce quindi il concetto di sistemi di intelligenza artificiale spiegabili (XAI) definiti come sistemi con la capacità di spiegare la logica delle decisioni, caratterizzare i punti di forza e debolezza del processo decisionale, e fornire indicazioni sul loro comportamento futuro.
La crescita di attenzione sull’XAI
Se dal punto di vista della ricerca le discussioni sull’XAI risalgono ad alcuni decenni fa, il concetto è emerso con rinnovato vigore alla fine del 2019 quando Google, dopo aver annunciato la sue strategia “AI-first” nel 2017, ha annunciato un nuovo set di strumenti XAI per gli sviluppatori.
Questo è avvenuto quasi in contemporanea con un altro importante evento propulsivo in favore dell’XAI: l’entrata in vigore, nel maggio 2018, del Regolamento generale sulla Protezione dei Dati (GDPR). Nell’articolo 22 infatti, il GDPR sancisce che le persone fisiche hanno il diritto di non essere sottoposte a processi decisionali basati esclusivamente su processi automatizzati (compresa la profilazione) e inoltre i criteri per giungere a tali decisioni devono essere resi noti al fine di garantire il diritto di contestazione (art.22 – par. 3).
Dall’altra parte dell’oceano, anche il Dipartimento della Difesa Americano, attraverso l’agenzia DARPA, preposta allo studio delle tecnologie emergenti nel contesto della sicurezza nazionale, sta portando avanti un programma di Explainable Artificial Intelligence (DARPA-XAI) con un investimento previsto di 2 miliardi di dollari.
Non c’è dubbio quindi che l’XAI non diventi un elemento centrale nell’evoluzione delle tecniche di intelligenza artificiale.
Indagare un sistema di AI: Interpretability vs Explainability
Ma cosa vuol dire veramente rendere spiegabile un sistema di intelligenza artificiale?
Alcuni studiosi sottolineano il fatto che spiegare il funzionamento di un sistema di AI può voler dire qualunque cosa, dalla comprensione dei dettagli più specifici degli algoritmi ai concetti di ragionamento di alto livello. Tuttavia si può affrontare la questione pragmaticamente agendo su due livelli.
Un primo livello di indagine riguarda la possibilità di mettere in relazione causale i dati in ingresso con quelli in uscita: si parla in questo caso di Interpretability (interpretabilità). Questa caratteristica consiste nel fornire una spiegazione del perché il modello ha fatto una certa scelta o ha fornito una determinata previsione (WHAT).
Un secondo livello è relativo alla spiegazione, in termini comprensibili ad un essere umano, su come il modello sia arrivato ad una determinata scelta o previsione: si parla in questo caso di Explainability. Questa caratteristica corrisponde a fornire una spiegazione su come funziona il modello (WHY).
Si parla in questo caso di “human style interpretations”. Il livello di comprensione del modello può essere “globale”, nel caso in cui permetta di capire come gli ingressi (‘variabili’ nel linguaggio usato nella comunità scientifica) condizionano i risultati forniti dal modello in relazione all’intero insieme di dati di addestramento, o “locale” nel caso in cui permetta di spiegare uno specifico output (decisione/classificazione).
L’interpretabilità è una condizione necessaria ma non sufficiente per ottenere la “spiegabilità”. Un interprete del modello può infatti generare la rappresentazione di un processo decisionale ma trasformarlo in una spiegazione utile può essere difficile poiché dipende da diversi fattori:
- il tipo di algoritmo che genera il modello
- il livello di spiegazione richiesto: a chi è indirizzata la spiegazione? A un utente generico interessato alla decisione? A un Data Scientist? A dirigenti e professionisti che useranno gli output algoritmici per prendere decisioni?
- il tipo di dati utilizzati nel modello.
Prima di analizzare quali sono le difficoltà da superare e quali gli approcci possibili è opportuno chiederci quali sono gli attori coinvolti e quali le caratteristiche che i sistemi di AI devono avere.
I fattori critici di un piano strategico di utilizzo dell’AI
Per orientarsi nel contesto complicato dell’evoluzione dei sistemi di AI e della interpretability/explainability richiesta è opportuno cominciare considerando gli use case di interesse della singola organizzazione in funzione delle sue caratteristiche operative e del contesto in cui opera.
Occorre quindi in primo luogo effettuare considerazioni:
- sugli use case;
- legate alle caratteristiche dell’organizzazione;
- legate al contesto in cui si opera.
In relazione a queste considerazioni si possono determinare i seguenti fattori critici da valutare per delineare un piano strategico di utilizzo dell’AI adeguato alla propria realtà:
Occorre valutare l’impatto della singola decisione e l’utilità economica legata alla comprensione della decisione nel contesto del processo che si è modellato.
- frequenza dell’utilizzo del modello decisionale
Il numero delle decisioni che l’applicazione di AI deve prendere (es. 1 milione/giorno vs 4/mese).
- affidabilità del modello decisionale
Robustezza dell’applicazione in termini di accuratezza della previsione/decisione e la sua capacità di generalizzare bene rispetto ai dati sconosciuti.
- conformità del modello decisionale
La conformità dell’applicazione di AI rispetto a leggi e regolamenti del settore di impiego.
- reputazione/credibilità del modello decisionale
L’impatto potenziale sul business e sugli stakeholders dell’utilizzo dell’applicazione di AI nel caso di risultati non corretti o pregiudizievoli.
Occorre considerare tutti gli stakeholders
Nell’evoluzione della scienza legata all’uso massivo ed estensivo dei dati, e quindi anche dell’AI, si è alla ricerca di una sorta di “Data Oath” per la Data Science sulla falsariga di quello che si fa da secoli nel campo medico con il giuramento di Ippocrate. Grazie a questo impegno il Data Scientist dovrebbe assumere una posizione deontologica nei riguardi di chi è impattato dall’analisi dei dati.
Per soddisfare questa esigenza è necessario partire dall’analisi di tutti gli attori coinvolti. Come mostrato in figura 1, si tratta di ragionare sia internamente all’organizzazione, dove Business Team e Data Science devono lavorare di concerto, che esternamente nei confronti dei consumatori/clienti e dei legislatori che ne proteggono i diritti e dettano i principi (es. GDPR).
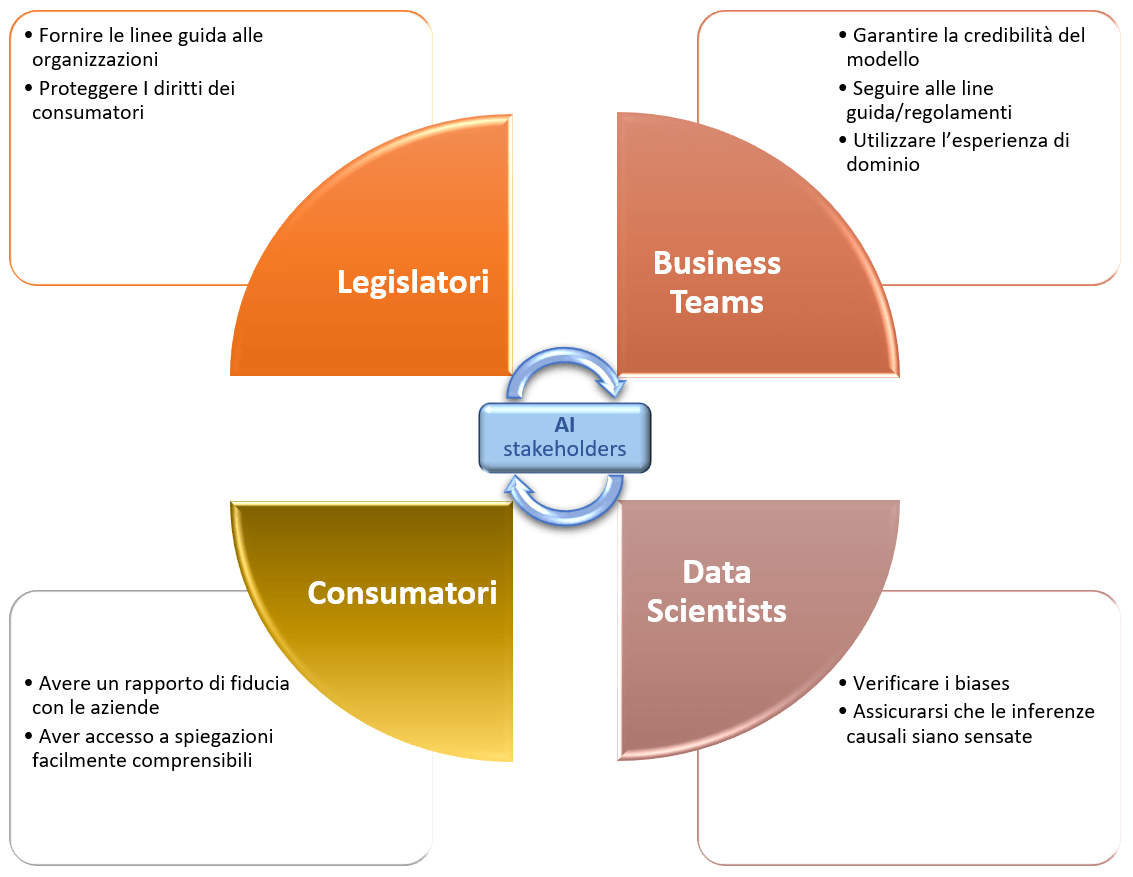
Fig. 1: gli stakeholders per un AI etico, compiti e necessità
Come vedremo in seguito, questi elementi, sebbene considerati importanti, destano preoccupazione nei Data Scientist, preoccupati del rischio di veder compromesse le prestazioni dei sistemi di AI al fine di garantire una capacità di spiegazione degli stessi.
Utilizzare un framework per mitigare i rischi potenziali
Per salvaguardare i principi etici e costruire una strategia di intelligenza artificiale affidabile è certamente utile affidarsi ad un framework come quello proposto da più parti analizzando le sei dimensioni chiave che andrebbero prese in considerazione collettivamente nella progettazione, sviluppo, implementazione e fasi operative dell’implementazione del sistema di AI.
Utilizzare un framework di questo tipo consente di aiutare le aziende a identificare e mitigare i rischi potenziali legati all’etica dell’AI in ogni fase del ciclo di questi sistemi.
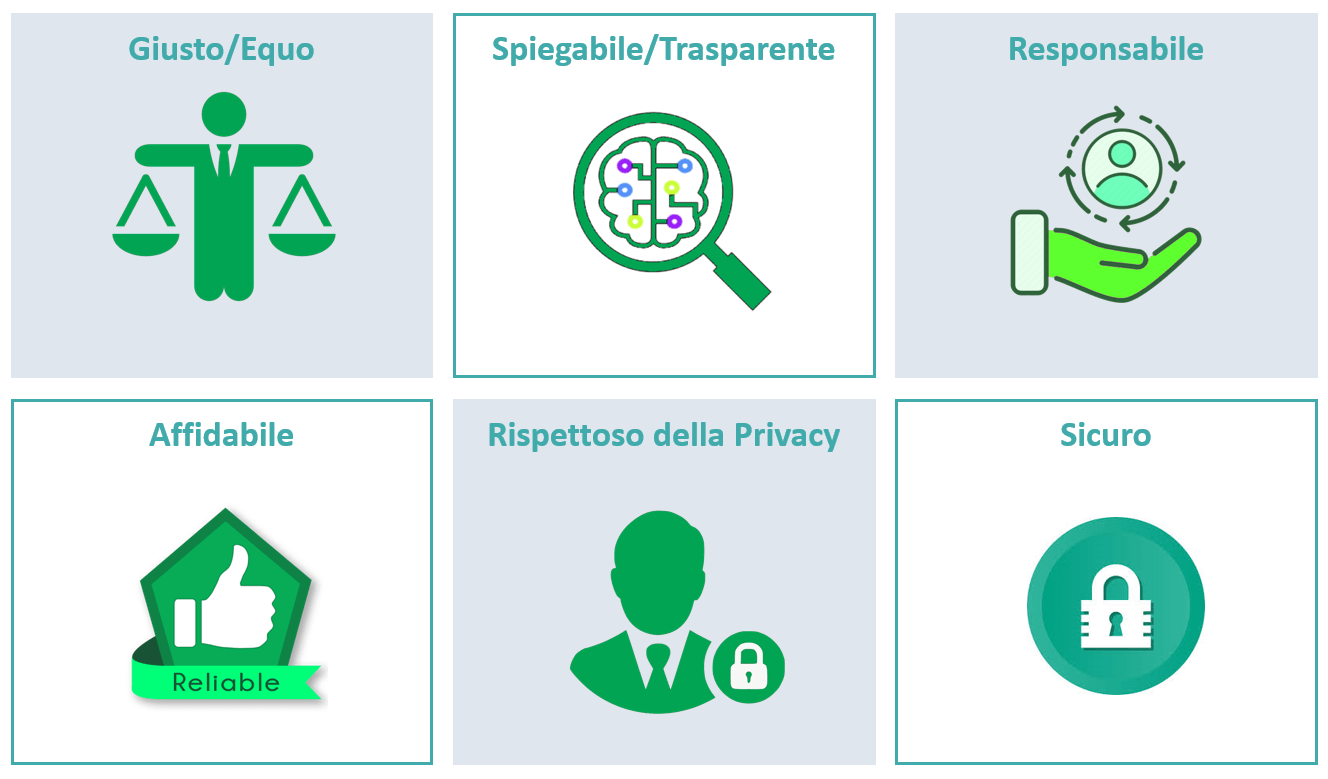
Figura 2: gli elementi di un possibile framework per implementare un AI affidabile
Una AI… giusta e imparziale
Un’intelligenza artificiale “giusta” deve includere controlli interni ed esterni per ridurre i pregiudizi discriminatori e deve essere progettata in modo da seguire un processo capace di prendere decisioni eque. Occorre anche far attenzione a che i sistemi progettati diano risultati di “buon senso” evitando decisioni tecnicamente corrette ma socialmente inaccettabili o opinabili. Occorre tener sempre ben presente che l’AI “impara” dai set di dati utilizzati per addestrarlo e se questi contengono una distorsione del mondo reale, i modelli generati possono apprendere, amplificare e propagare tale distorsione a velocità e scala digitali.
Esempi di problemi di questo tipo sono all’ordine del giorno (es. Amazon). Per evitare questo genere di problemi, legati all’equità e alla parzialità, le aziende devono prima definire cosa costituisce “giusto” in un certo contesto e questo può essere molto più difficile di quanto sembri, dal momento che generalmente non esiste una singola definizione su cui tutti concordano. Quando poi viene rilevata una distorsione, essa deve essere compresa e mitigata attraverso processi consolidati in modo da ricostruire la fiducia dei clienti.
…trasparente e “spiegabile”
Affinché l’AI sia considerata affidabile, tutti i partecipanti devono comprendere come vengono utilizzati i loro dati e come l’AI prende le decisioni. Deve quindi essere possibile accedere agli algoritmi e poter avere una spiegazione comprensibile di come operano. In questo caso ci possono essere livelli diversi di “spiegabilità” a seconda dell’audience (e.g. Data Scientist, Business Specialist, End-Users) e dei casi d’uso. Inoltre, per quanto riguarda la trasparenza, vi è una crescente pressione per informare esplicitamente le persone quando interagiscono con sistemi di AI e deve essere possibile stabilire chiaramente chi è responsabile dei dati e delle scelte che vengono effettuate. Incolpare la tecnologia per decisioni errate non è sufficiente: non lo è sicuramente per le persone danneggiate ma neppure per i legislatori (si pensi ad esempio alla guida autonoma o a servizi di gestione patrimoniale basati sull’AI).
Trasparenza e “spiegabilità” consentono di verificare che il sistema prenda le decisioni corrette per le giuste ragioni e questo è alla base della fiducia (trust) nel sistema di AI.
… responsabile
È fondamentale poter individuare con chiarezza chi è responsabile per le decisioni prese dal sistema di intelligenza artificiale. Questo a sua volta richiede una chiara comprensione di come funziona il sistema, di come prende le decisioni e di come impara ed evolve nel tempo. Nel caso di un evento avverso causato dal sistema occorre essere in grado di procedere a ritroso nella catena causa-effetto fino alla persona o all’organizzazione che può essere ragionevolmente ritenuta responsabile dell’evento.
A seconda della natura del problema, la responsabilità potrà essere attribuita a diversi attori nella catena causale; si potrebbe trattare per esempio di una persona che ha preso la decisione di utilizzare il sistema di AI per un’attività per cui non era adatto o il team di sviluppo che non ha integrato sufficienti controlli di sicurezza.
L’attribuzione di responsabilità sarà un elemento sempre più importante a mano a mano che l’AI verrà utilizzata in una gamma di applicazioni sempre più critiche come la diagnosi delle malattie, la gestione patrimoniale o la guida autonoma.
…robusta e affidabile
Affinché i sistemi di AI si possano diffondere veramente occorre che siano affidabili almeno quanto quelli che vanno a sostituire e che forniscano delle decisioni coerenti e consistenti nel tempo, anche quando si dovessero trovare a funzionare in situazioni impreviste. Eventuali errori devono ricadere in qualche modo nel campo della prevedibilità in modo che gli utenti di questi sistemi ne possano essere consapevoli.
…sicura e protetta
Per essere affidabile, un sistema di AI deve anche essere protetto dai rischi di sicurezza informatica che potrebbero causare danni fisici e/o digitali. Sebbene la sicurezza e la protezione siano chiaramente importanti per tutti i sistemi informatici, sono particolarmente cruciali per l’intelligenza artificiale a causa del ruolo e dell’impatto che questa ha nelle attività nel mondo reale (es. sistemi finanziari, sistemi di guida autonoma). Debolezze sul piano della sicurezza dei sistemi di AI possono dar luogo a perdita di reputazione, di denaro/dati o peggio ancora di vite umane.
AI e rispetto della privacy
La privacy è un problema critico per tutti i tipi di sistemi di dati, ma è particolarmente importante per l’AI poiché le previsioni/decisioni generate da questi sistemi di intelligenza artificiale spesso derivano da dati più dettagliati e personali. Occorre assicurarsi di avere acquisito il diritto di trattare questi dati e di rispettare le normative utilizzandolo esclusivamente per gli scopi dichiarati e concordati. Il problema della privacy dell’AI spesso si estende anche al di fuori delle aziende che realizzano questi sistemi (es. privacy dei dati audio acquisiti da AI assistant accessibili a fornitori e partner) e occorre inoltre garantire ai clienti un livello di controllo adeguato dei loro dati (es. diritto di cancellazione o revoca del permessi)
XAI: difficoltà, compromessi e possibili approcci
Come visto in precedenza, in molti casi l’explainability è una caratteristica irrinunciabile. Tuttavia ci sono diversi ostacoli che sviluppatori e professionisti devono affrontare per ottenere sistemi di XAI che rispondano alle esigenze dei singoli casi d’uso. Innanzi tutto è importante osservare che l’interpretabilità di un modello è una caratteristica che è frutto di un compromesso.
In linea di principio infatti, quanto più il modello è complesso, tanto più è preciso ma meno interpretabile. La complessità è in prima istanza legata alla classe di algoritmi di apprendimento automatico utilizzati per generare il modello e secondariamente alla dimensione del modello (es. il numero di strati di cui è composta la rete neurale).
In figura 3 è mostrata la situazione attuale.
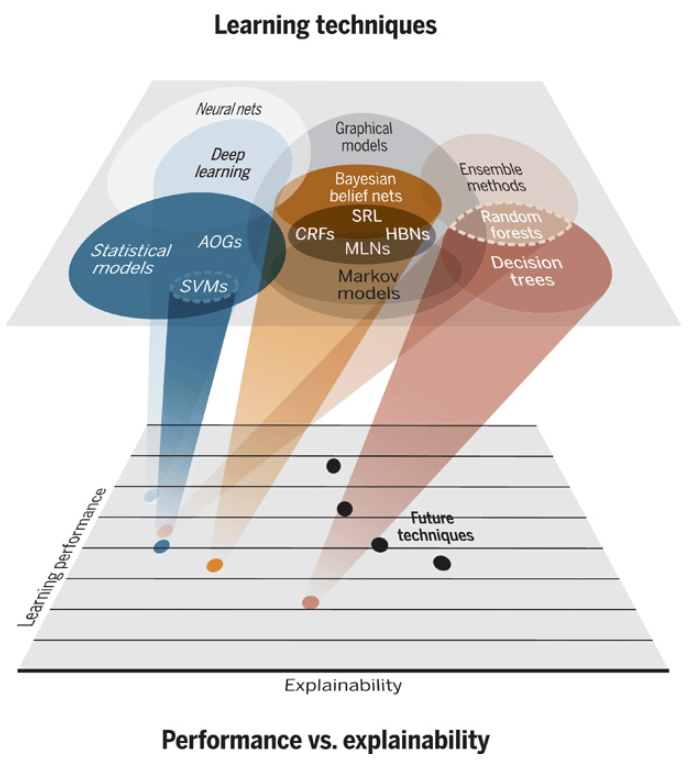
Fig. 3: XAI – prestazioni vs spiegabilità (A. Kitterman/Science Robotics)
La figura mostra come le DNN siano le tecniche più performanti ma meno spiegabili mentre i Decision Tree (alberi decisionali), che sono basati su regole, tendono a premiare l’explainability rispetto all’efficacia.
Lo sforzo che si sta facendo da più parti è relativo al miglioramento dell’ explainability a parità di accuratezza.
Spesso la difficoltà sta nel fatto che normalmente gli algoritmi non sono progettati per essere explainable-by-design, cioè non si tiene conto delle caratteristiche di explainability e transparency già nella fase iniziale di concezione del modello.
Quando questo non accade, la ricerca dell’explainability avviene partendo dal concetto di black-box attraverso i paradigmi mostrati in Figura 4.
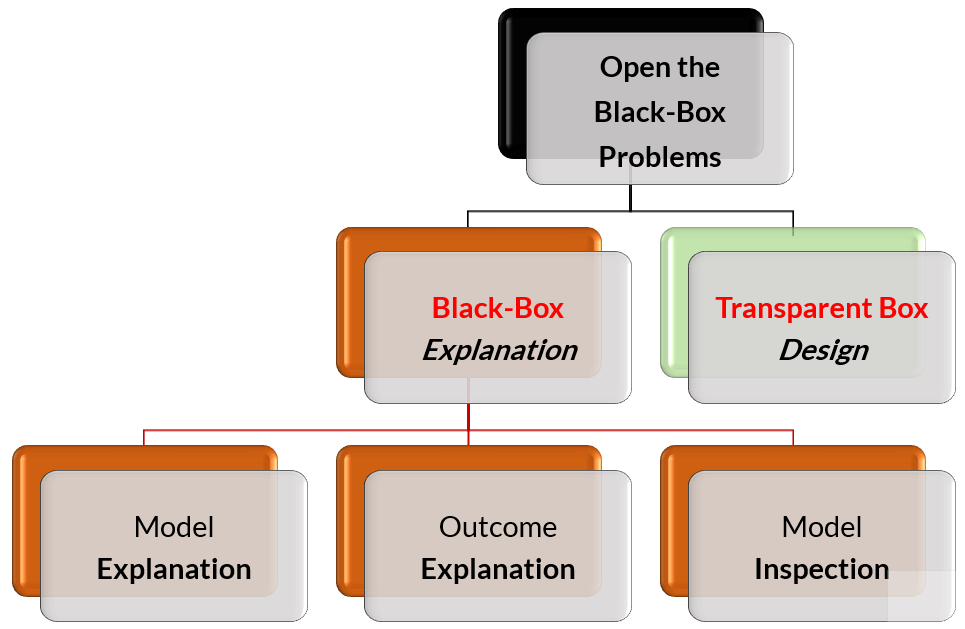
Fig. 4: Tassonomia dell’explainability di modelli di AI (DSSS 2019-Pisa)
Si tratta in sostanza di fornire una spiegazione del funzionamento della “scatola nera” attraverso specifici strumenti (spesso visuali ma talvolta testuali o basati su esempi come nel caso del What-IF tool della Google Cloud Platform)
Le tecniche di Model Explanation sono tipicamente agnostiche e generano una interpretazione del modello imitandone il comportamento generale mentre quelle di Outcome Explanation interpretano il modello in relazione alla singola istanza (interpretable local predictor). Con le tecniche di Model Inspection invece si fornisce una rappresentazione (visiva o testuale) per comprendere il funzionamento del modello o per capire come certe previsioni siano più probabili di altre.
Le tecniche agnostiche più comuni sono Sensitivity Analysis, LIME (Local Interpretable Model) e SHAP.
Con la Sensitivity Analysis il principio è quello di perturbare i dati in ingresso al modello e verificare come cambia l’output del modello, ripetendo questo processo fino a costruire una rappresentazione grafica del funzionamento del modello rispetto a specifiche features (es. fonemi in un segnale audio o contorni in una immagine). Questo non consente di comprendere le interazioni tra feature diverse del modello. Con LIME si cerca di superare quest’ultima limitazione attraverso una perturbazione del modello multi-feature focalizzata su una specifica predizione del modello.
SHAP si basa invece sulla teoria dei giochi collaborativi (concetto di valore di Shapley): viene misurato quanto ogni feature del modello contribuisce ad un determinato output consentendo quindi di identificare la feature più importante per un certo output.
Questi metodi si basano sull’osservazione di ciò che accade alle uscite del modello quando si modificano gli ingressi. Si tratta quindi di approcci diretti la cui semplicità va in qualche modo a scapito della explainability.
Nel caso di Transparent Box Design si hanno invece modelli che sono globalmente o localmente interpretabili per loro stessa natura, “by design”.
Un esempio classico di modelli “trasparenti” è quello dei decision tree che rende esplicite le alternative e per ogni output consente di ripercorrere a ritroso tutte le scelte fatte che hanno portato a quel determinato output a partire dai dati in ingresso al modello. Questo tipo di modelli paga però lo scotto prestazionale rispetto ad algoritmi basati sulle reti neurali addestrate con un set di dati sufficientemente ampio.
Recentemente si stanno affermando però anche metodi ibridi che utilizzano particolari reti neurali chiamate Switching Neural Network (SNN) che, grazie all’uso della logica booleana nel primo livello della rete e di tecniche specifiche di addestramento, riescono ad ottenere accuratezze simili a quelle delle Deep Neural Network mantenendo una explainability pari a quella dei metodi di Decision Tree (RuleX AI).
AI, tante tecniche diverse
La società di ricerca Gartner stima che l’economia globale dell’intelligenza artificiale aumenterà dai circa 1,2 trilioni di dollari del 2018 a circa 3,9 trilioni di dollari entro il 2022, mentre McKinsey prevede un’attività che generi un’economia globale di circa 13 trilioni di dollari entro il 2030.
Le tecniche di intelligenza artificiale, in particolare i modelli di deep learning (DL), stanno rivoluzionando il mondo degli affari e della tecnologia con prestazioni strabilianti in un’area di applicazione dopo l’altra: classificazione delle immagini, riconoscimento degli oggetti, monitoraggio degli oggetti, analisi video, generazione di immagini sintetiche – solo per nominarne alcuni.
Gli algoritmi di intelligenza artificiale sono utilizzati oramai in moltissimi settori: sanità, servizi IT, finanza, produzione, guida autonoma, riproduzione di videogiochi, ricerca scientifica e persino nel sistema giudiziario e in quello sanitario.
Tuttavia gli algoritmi alla base di questi sistemi di intelligenza artificiale non sono altro che tecniche che permettono ai sistemi informatici di prevedere, classificare, ordinare, prendere decisioni e in generale estrarre conoscenze dai dati senza bisogno di definire a priori delle regole esplicite. Non c’è quindi una programmazione predefinita dei computer per la costruzione del modello predittivo del problema d’interesse ma il modello viene generato in modo automatico attraverso l’analisi dei dati in una fase di apprendimento: si parla allora di machine learning (ML). Spesso nel linguaggio corrente si continua comunque a utilizzare il termine generico AI anche quando si dovrebbero utilizzare termini come narrow AI o ML.
La distinzione principale tra le tecniche di ML viene fatta tra i sistemi basati su regole (cioè costrutti del tipo “if … then … else”) e quelli che non lo sono. I modelli che non si basano su regole sono a loro volta suddivisi principalmente in tre ampie categorie: Supervised Learning (SL), Unsupervised Learning (UL), Reinforced Learning (RL).
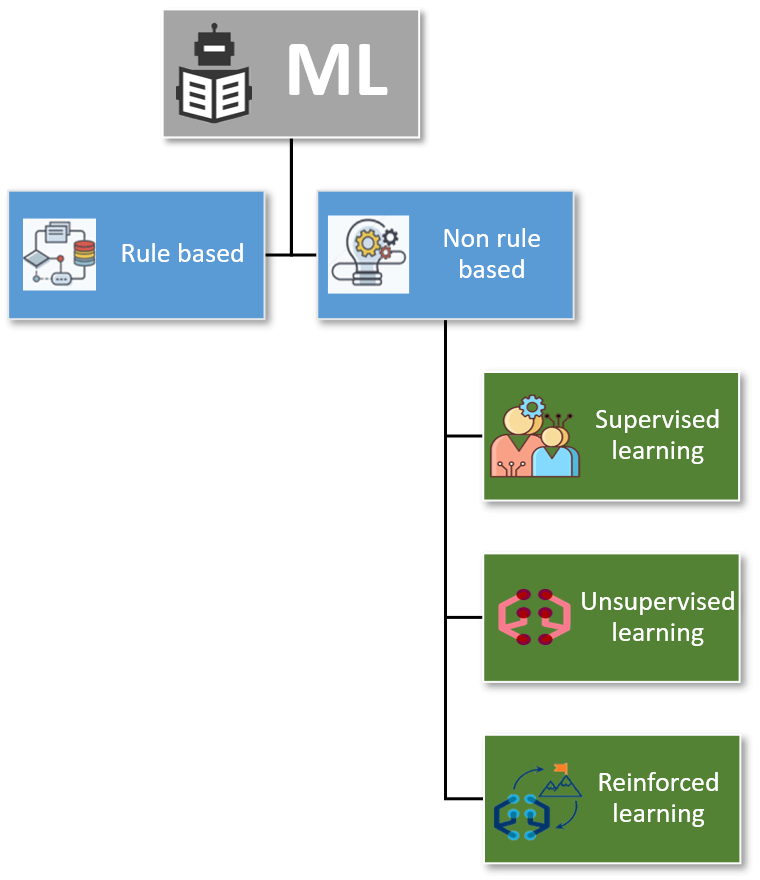
Fig. 5: Classificazione degli algoritmi di AI
In particolare gli algoritmi RL, che sono tra i più sofisticati e promettenti, sono quelli alla base dei modelli utilizzati ad esempio per realizzare i sistemi di guida autonoma dei veicoli o i movimenti dei robot: si tratta di agenti software che apprendono in autonomia le modalità con cui interagire con l’ambiente. Essi si comportano come molte persone si aspettano da un’intelligenza artificiale: così come farebbe un umano, scelgono infatti azioni e “fanno cose” in risposta ad altri agenti esterni. Per raggiungere questo obiettivo, gli algoritmi di RL si basano su una rappresentazione dello spazio degli stati del loro ambiente e cercano di ottimizzare il loro comportamento scegliendo ripetutamente le azioni che portano a “stati ad alto valore”.
Il valore di questi stati “ambientali” viene appreso durante la fase di training in cui l’algoritmo esplora il suo ambiente. Questa tecnica è quella che è stata utilizzata, ad esempio, da Google DeepMind per realizzare l’algoritmo AlphaGo che ha battuto il campione del mondo di Go e da Boston Dynamics per addestrare il suo robot umanoide a salire le scale e a mantenere l’equilibrio durante lo spostamento negli ambienti più disparati.
Una delle evoluzioni più potenti e discusse di queste tecniche, i modelli di deep learning (DL), utilizzano milioni di parametri per la loro caratterizzazione e creano rappresentazioni interne estremamente complesse e altamente non lineari delle immagini o dei set di dati che gli vengono sottoposti.
Il livello di affidabilità dei sistemi di AI
I sistemi di AI descritti consentono in genere di ottenere previsioni molto accurate dopo che sono stati “addestrati” ma, proprio a causa della loro natura, sono poche le speranze di comprenderne le caratteristiche interne o la rappresentazione dei dati che questi modelli utilizzano, ad esempio, per classificare una particolare immagine in una categoria.
Questa è la ragione per cui i sistemi decisionali o di classificazione che scaturiscono da queste tecniche vengono paragonati a “scatole nere” (black boxes).
Tuttavia anche questi modelli, come tutti, non sono infallibili e può capitare che facciano previsioni errate, talvolta eclatanti. Ad esempio, come si può vedere dalla figura qui di seguito, le immagini 2 e 4 sono state classificate rispettivamente come una chitarra e un pinguino con grande livello di confidenza, pur non avendo niente a che fare con questi.

Fig. 6: Deep Learning: esempi di fallimento nella classificazione di immagini
La causa di questi errori può risiedere nei dati utilizzati per l’addestramento dei sistemi (es. dati contenenti dei pregiudizi-bias) o nella natura intrinseca delle tecniche utilizzate per generare i modelli previsionali, ma anche in entrambi contemporaneamente. Nel corso degli ultimi anni gli esempi di fallimento dei sistemi di AI sono stati molteplici e hanno assunto rilevanza nelle cronache di tutto il mondo: incidenti mortali in auto a guida autonoma, indicazioni errate nella cura del cancro, giudizi errati nei tribunali, errori nei processi di selezione del personale, etc.
A prima vista si potrebbe commentare che questo aspetto delle tecniche di ML non sia un problema poi così grave se la loro accuratezza è generalmente molto elevata e gli errori avvengono davvero raramente. I problemi a ben guardare sono di diversa natura.
Da un punto di vista tecnico è difficile prevedere quando e quanto questi modelli perdano la loro affidabilità. Questo è difficile da accettare soprattutto quando la decisione errata non riguarda argomenti come la scelta del film più appropriato da suggerire, ma tocca ambiti delicati come molti di quelli descritti in precedenza.
Dal punto di vista dell’essere umano, quando le scelte lo riguardano direttamente si nota una resistenza all’uso dell’AI poiché vi è la convinzione che questa non tenga conto in modo adeguato delle caratteristiche individuali e delle proprie idiosincrasie; le persone sono uniche. Se prendiamo ad esempio il campo medico si osservano posizioni di questo tipo: il “mio” raffreddore è una malattia unica che affligge me in modo distinto. Si rileva cioè un rifiuto a delegare una diagnosi o una terapia ad un modello matematico che viene percepito come inflessibile e standardizzato. Si cerca, come minimo, una mediazione umana. È interessante su questo argomento un articolo apparso sull’Harvard Business Review: AI Can Outperform Doctors. So Why Don’t Patients Trust It?
Queste considerazioni hanno generato un allarme immediato ed è diventato quindi urgente rispondere a domande quali:
- perché il sistema ha fatto una determinata scelta e non un’altra?
- quand’è che il sistema si comporta correttamente e quando sbaglia?
- quando ci si può fidare del sistema?
- come si possono correggere gli errori del sistema?
Il tipo di tecnica utilizzata è un fattore importante da prendere in considerazione ma, come vedremo in seguito, non è il solo da esaminare in relazione a queste domande.
Conclusioni
Come si vede dal fermento, non solo più accademico, ma industriale e sociale rispetto ai temi dell’XAI, stiamo uscendo dai giorni spensierati dei primi risultati eclatanti dell’AI. Qualunque sistema cognitivo che agisca con previsioni o decisioni nella vita reale, al di fuori dei laboratori di ricerca, dovrà essere in grado di spiegare, più o meno dettagliatamente a seconda del contesto, le sue decisioni e lo dovrà fare in un contesto non solo di automazione delle decisioni ma soprattutto in un contesto di Human Augmented Capabilities come previsto anche nell’Hype Cycle for Emerging Technologies di Gartner.



