
Indice degli argomenti:
L’AI spiegata agli umani
Immaginate di avere a casa vostra un robo-assistente. Meccanico e goffo come C-3PO oppure un androide avanzato come nelle serie TV moderne, per questo esempio non fa differenza. L’assistente vi guarda, vede che vi siete vestiti bene e vi chiede “hai un abito professionale, stai andando in ufficio?” Per ora questa semplice osservazione è ancora fuori della portata dei più diffusi sistemi di intelligenza artificiale in commercio. Può sembrare strano, ma nessun prodotto AI oggi in circolazione è in grado di fare una semplice associazione linguistico-visuale come quella di guardare come vi siete vestiti ed esprimere, con parole normali, un concetto collegato alla situazione. Magari formulando una domanda correlata come quella dell’esempio. Sono però allo studio i sistemi multi-modali che usano più modelli per migliorare le performance complessive, integrando anche l’audio, la ricerca, le decisioni, la robotica.
Dalla “narrow AI” alla “vokenization”
I sistemi di intelligenza artificiale, come non smettiamo mai di ripetere, in genere fanno una sola cosa e cercano di farla bene. Per questo motivo la categoria di soluzioni viene chiamata AI “stretta” (o narrow AI), poiché non esce fuori dai binari operativi e funzionali che le vengono dati. Molti sono gli sforzi di ricerca finalizzati a dare ai sistemi di intelligenza artificiale maggiore ampiezza, per farli generalizzare verso altri compiti, ma i risultati sono spesso deludenti. Un sistema di visione artificiale sarà senz’altro in grado di guardare mille persone diverse e categorizzarle in base agli abiti indossati, e i sistemi di elaborazione del linguaggio naturale sono sempre più performanti nel chiacchierare con gli esseri umani, ma far confluire queste due caratteristiche in un unico sistema AI è un compito per ora molto arduo.
Negli ultimi anni, tuttavia, si è aperto un filone di ricerca promettente, che mira a far collaborare insieme queste due diverse modalità non solo per ottenere risultati più simili all’emulazione dell’intelligenza (un assistente che commenta ciò che vede sicuramente potrà sembrare un’entità intelligente), ma anche per migliorare le performance dei singoli sistemi.
Su quest’ultimo aspetto è utile citare lo studio di due ricercatori della University of North Carolina, che hanno sperimentato la “vokenization”, ovvero l’associazione di token linguistici (un token è un singolo elemento di un linguaggio) a immagini visive contestuali, dette “voken”. L’appaiamento fra token testuale e voken visivo aiuta il modello a districarsi fra testo e significato, affinando inoltre le prestazioni in caso di termini ambigui. Per fare un esempio, il termine “riso” può indicare il cereale così come una reazione di ilarità. I modelli di elaborazione del linguaggio non sempre sono in grado di distinguere il contesto, ma l’associazione del termine utilizzato a un’immagine visiva permette al modello di indovinare più spesso il riferimento corretto. Alcuni test dimostrano che i modelli di linguaggio potenziati dai voken offrono performance migliori rispetto agli stessi modelli senza voken.
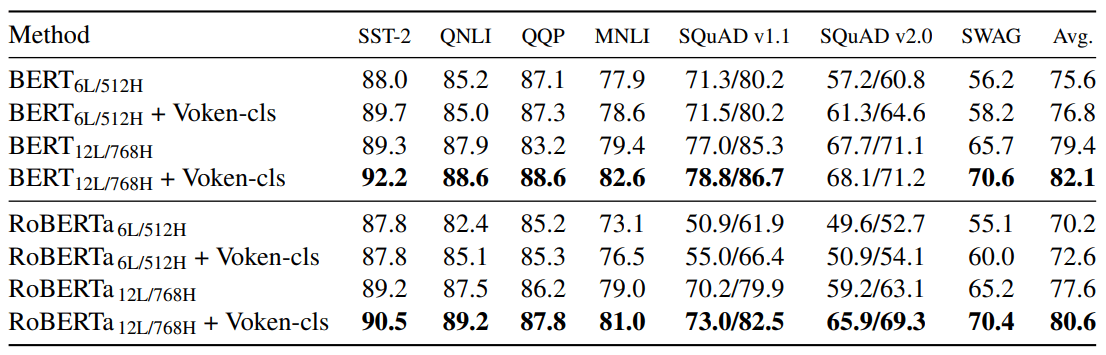
Figura 1: test su diversi benchmark che illustrano come i modelli con i Voken raggiungano risultati migliori
Associare immagini e parlato non è altro che un’ispirazione presa dallo sviluppo di noi esseri umani: da bambini impariamo a conoscere il mondo circostante guardandolo e commentandolo, associando i suoni alle cose che vediamo. Man mano che cresciamo, la capacità di descrivere immagini e suoni ci consente di comprendere fenomeni sempre più complessi e profondi. La strada che sta prendendo la ricerca AI oggi è far interagire sistemi diversi per tentare di far germogliare quella comprensione del contesto che oggi all’intelligenza artificiale ancora manca.
Ne è un altro esempio DALL-E, che si serve del testo per generare immagini realistiche e creative. Linguaggio e visione insieme possono ottenere risultati per certi versi maggiori della somma delle loro parti, ed è per questo che in futuro vedremo molti più tentativi di farli coabitare, se non in un unico sistema, perlomeno in un framework condiviso.
Ma la ricerca non si fermerà con testo e immagini: la direzione dei sistemi multi-modali è quella di usare più modelli per migliorare le performance complessive sia sul piano della versatilità, sia su quello dell’emulazione dell’intelligenza generale. Per questo motivo aspettiamoci sistemi che integrino anche l’audio, la ricerca, le decisioni, per non parlare ovviamente della robotica.

Alcune immagini generate da DALL-E inserendo i termini “lampada” e “orchidea”
Sistemi multi-modali, un caso pratico
Per uno use case concreto di come potrebbe funzionare un sistema multi-modale, torniamo all’esempio iniziale e immaginiamo il robo-assistente che nel suo dataset avrà sia dei nostri riferimenti audio, affinché possa riconoscere la nostra voce, sia video, affinché possa riconoscere il nostro volto. Se un giorno dovessimo avere una voce più rauca del solito, il modello di riconoscimento vocale noterebbe che la nostra voce si discosta di una certa percentuale dal solito timbro vocale. Per essere precisi, il modello avrà una confidenza di appena il 70% che quella sia la nostra voce, a fronte di una confidenza normale del 95/99%. A quel punto verrebbe chiamato in causa il sistema di riconoscimento facciale, che confermerebbe che a parlare siamo effettivamente noi. In caso di un elevato scostamento di confidenza nel modello di riconoscimento del timbro vocale, il sistema verrebbe istruito a chiedere spiegazioni, eventualmente per procedere a una nuova sotto-classificazione: “come mai la tua voce è diversa?” Alla nostra risposta “ho preso un raffreddore” il sistema linguistico riconoscerebbe il raffreddore come un concetto riferito a una patologia.
Collaborando con il sistema di riconoscimento audio si creerebbe anzitutto una nuova classificazione del timbro vocale (questa è la voce dell’essere umano primario quando è raffreddato), mentre il sistema decisionale stabilirebbe che è il caso di cercare online un rimedio per aiutarci. A quel punto il sistema di estrazione della conoscenza potrebbe andare a cercare in un database medico i rimedi contro il raffreddore e il risultato di tale ricerca ci verrebbe comunicato nuovamente dal sistema di linguaggio sotto forma di suggerimenti: “perché non ti prepari una tisana allo zenzero?”, “vuoi che ti metta in contatto con la farmacia?”
Tutto questo ovviamente in pochi secondi, ma con l’attivazione di svariati sistemi diversi che lavorano insieme come membri di un’orchestra.
Conclusioni
L’esempio è volutamente futuristico. Nella realtà questi sistemi sono ancora quasi sempre separati e non collaborano così efficacemente, ma se le ricerche verso l’intelligenza artificiale dei sistemi multi-modali proseguiranno, non è impossibile che qualcosa del genere possa vedere la luce nei prossimi quattro-cinque anni. Non sarà ancora intelligenza artificiale forte, ma potrebbe gettare le basi per una comprensione più profonda da parte dei sistemi AI del nesso causale e della comprensione del senso comune, due dei molti gradini che ancora ci separano dalla nascita dell’intelligenza artificiale generale.




