
Sin dalla metà del 2021, tutti (o quasi) hanno avuto modo di apprendere del cambio di brand del gruppo guidato da Mark Zuckerberg (diventato adesso Meta) e della sua nuova idea di creare il cosiddetto metaverso, l’evoluzione virtuale e 3D della sua piattaforma di socializzazione e collaborazione. Gran parte della fattibilità di tale ambizioso progetto è basata sull’applicazione di algoritmi e tecniche di AI. AI4business.it ha partecipato all’evento online del 23 febbraio 2022 “Meta Inside the Lab: costruire il metaverso con l’AI”, durante il quale sono stati svelati molti dettagli sulla strategia che Meta sta perseguendo per la realizzazione del metaverso.
Indice degli argomenti:
L’evento online di Meta

Nel discorso di apertura, Mark Zuckerberg, dopo aver mostrato una breve demo dello stato attuale dell’esperienza utente nel metaverso, ha subito posto l’accento sulle evoluzioni tecnologiche dell’AI necessarie per la sua implementazione come da visione iniziale. La sfida principale è legata al far sì che l’AI possa aiutare gli utenti a navigare questo nuovo mondo virtuale e produrre per loro la migliore esperienza possibile. Poiché l’interazione con altri utenti, oggetti e funzionalità disponibili nel metaverso può avvenire in diversi modi, quali ad esempio voce o gesti, c’è bisogno di implementare una AI multi-modale (vedi figura 1) e che, in particolare per la parte visuale, possa essere addestrata in maniera semi-supervisionata, in quanto non sarebbe possibile ottenere il livello di generalizzazione richiesto tramite un approccio supervisionato, che richiederebbe un volume di immagini annotate troppo grande da gestire.
L’approccio scelto per la parte visuale è quello di addestrare un modello a ricostruire singoli oggetti o intere scene a partire da immagini parziali (che è la situazione che si presenta più di frequente in casi di applicazioni come questa che prevedono visuale in prima persona).
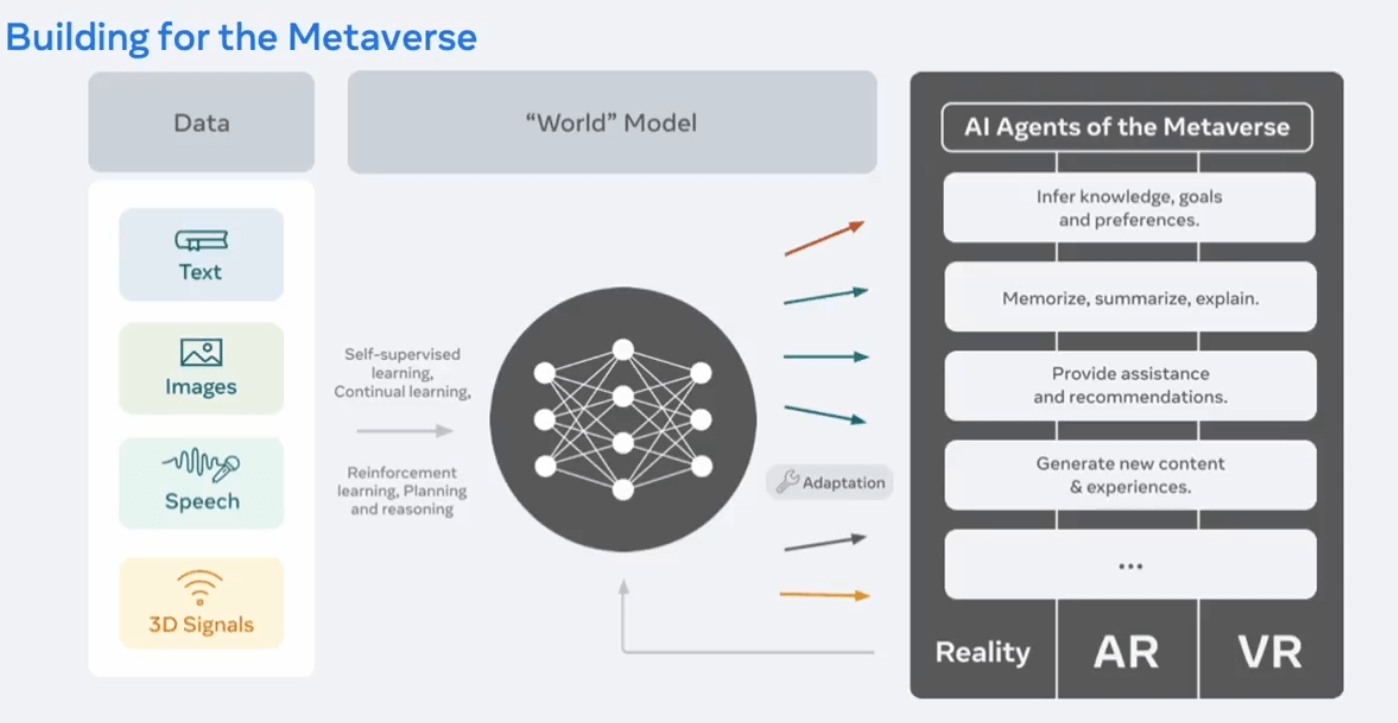
Figura 1 – Modello di AI unificato per diversi task alla base del metaverso di Meta
La necessità di implementare un singolo modello AI per tutto è quindi la sfida principale, ma non l’unica: altro scoglio da affrontare riguarda la moltitudine di lingue parlate nel mondo. Attualmente la maggioranza di servizi disponibili online (e in particolare quelli basati su AI) gestiscono un singolo linguaggio alla volta e spesso l’inglese è l’unica opzione supportata. Questo rappresenta per molte persone una barriera d’accesso alla fruizione di servizi che fanno (o faranno parte) della quotidianità.
Zuckerberg ha poi sottolineato l’importanza della condivisione da parte di Meta AI di strumenti Open Source i quali, favorendo la creazione di una community molto vasta e la collaborazione con enti di ricerca esterni all’azienda, hanno contribuito (e contribuiranno ulteriormente) ad accelerare il processo di implementazione del metaverso. Tra i progetti Open Source rilasciati da Meta, Zuckerberg ha citato in particolare EGO4D, un vastissimo dataset composto da quasi 4000 ore di video in prima persona registrati in svariate location nel mondo, PyTorch, uno dei più popolari framework per il Deep Learning e CrypTen, un framework per l’implementazione di Machine learning che preserva la privacy e basato su PyTorch.
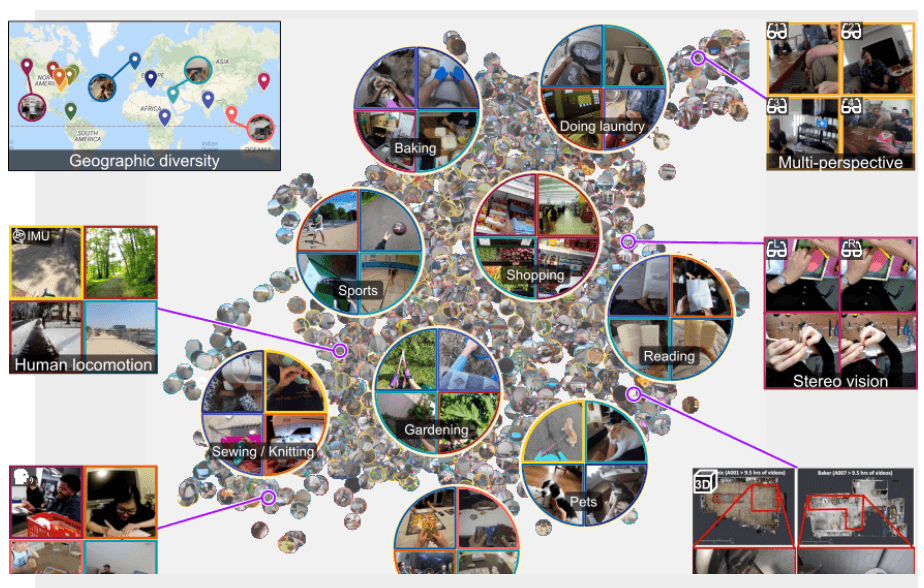
Figura 2 – Il dataset EGO4D
Alla fine del suo intervento, Zuckerberg ha poi sottolineato che la implementazione del metaverso è possibile oggi grazie alla visione di lungo termine e al piano di investimenti e ricerca che l’azienda ha iniziato quasi 10 anni fa.
Le sessioni tecniche
Le quattro sessioni successive all’apertura di Zuckerberg sono state di contenuto più tecnico.
Prima sessione: Jerome Pesenti, VP Meta AI e Joelle Pineau, Direttore Meta AI Research
Nella prima, Jerome Pesenti, VP di Meta AI, dopo una breve introduzione durante la quale ha ribadito l’importanza del rilascio di strumenti Open Source per una proficua collaborazione di ricerca con entità esterne e descritto velocemente il modello operativo dell’area di cui è a capo, ha passato la palla a Joelle Pineau, Direttore di Meta AI Research, la quale ha presentato più in dettaglio i progetti nella sua area strettamente legati alla evoluzione del metaverso e che sono in fase avanzata di ricerca o per i quali si è già passati in fase di esecuzione, tutti legati dai fattore comuni della roadmap verso un modello unificato multimodale e pronto per qualsiasi ambiente (reale, AR e VR) e dell’apprendimento semi-supervisionato (SSL, Semi-Supervised Learning):
- Touch sensors. DIGIT, realizzato in collaborazione con uno spin-off del MIT, un sensore tattile a basso costo per applicazioni in robotica di manipolazione assistita da Machine learning. È composto da un elastometro deformabile che misura forze di contatto attraverso cambiamenti rilevati in immagini catturate tramite fotocamera installata nel sensore stesso. Tale progetto è completamente Open Source ed è quindi possibile anche per terze parti assemblarlo e programmarlo.
- PyTouch: una libreria Python per Machine Learning end-to-end in applicazioni di touch sensing tattile. Open Source anch’essa. L’obiettivo di DIGIT e PyTouch è quello di rendere l’esperienza di manipolazione di oggetti da parte degli avatar digitali nel metaverso simile a quella che abbiamo nella realtà.
- Habitat: un simulatore Open Source (inclusivo di API e supporto per dataset generici) per il training di robot virtuali e assistenti egocentrici in ambienti altamente realistici. Molto performante anche in esecuzione su un sistema con una singola GPU di media-alta capacità.
- TorchRec: la libreria usata da tutte le piattaforme Meta per l’implementazione di recommendation system altamente scalabili. L’annuncio degno di nota riguardo questa libreria è il rilascio Open Source (sotto licenza BSD-3) dei suoi codici sorgente, come dimostrazione dell’impegno da parte di Meta non solo verso l’Open Science, ma anche verso la trasparenza.
Seconda Sessione: Piotr Dollar, Research Director Meta AI
Nella seconda sessione, Piotr Dollar, Research Director in Meta AI, ha raccontato ad alto livello la transizione del training dei modelli di Computer Vision in Meta da un apprendimento di tipo supervisionato a uno di tipo SSL per motivi di scalabilità (impossibilità di annotare l’enorme quantità di immagini necessarie e, anche nella situazione ideale in cui sarebbe possibile farlo, l’inevitabile presenza di bias nei dataset annotati manualmente sarebbe non trascurabile). In questo modo un modello diventa in grado di imparare da ciò che si trova intorno. Un altro potenziale vantaggio di questo approccio è una maggiore capacità di generalizzazione che porta a una riduzione dei bias non facilmente ottenibile in modelli addestrati in maniera supervisionata.
Terza sessione: Angela Fan, Research Scientist Meta AI
Nella terza sessione, Angela Fan, Research Scientist in Meta AI, ha descritto le motivazioni dietro la scelta di implementare un traduttore unificato per tutte le lingue esistenti al mondo, non solo quelle più diffuse, ma anche quelle parlate da minoranze, così da rendere la tecnologia realmente inclusiva (seguendo il motto “no language left behind”, anticipato da Zuckerberg nelle sue note iniziali di questo evento). I sistemi di traduzione automatica attuali basati su Deep Learning operano su input in un singolo linguaggio e sono in grado di fare solo traduzioni 1:1 (anche gli output sono in un solo linguaggio). Quindi in applicazioni che richiedono traduzione in più linguaggi, bisogna addestrare molteplici modelli bi-lingual per coprire tutti le combinazioni necessarie. Poiché questa è una strategia poco scalabile, l’idea che ha avuto Meta AI è quella di implementare un sistema di traduzione automatico multi-linguaggio che, a differenza di altri esistenti che accettano testo in input appartenente a diverse lingue e che eseguono come primo step la traduzione in inglese e successivamente la conversione di questa traduzione in una delle lingue di destinazione supportata, esegue una traduzione many-to-many diretta. Questo approccio, oltre a essere più vicino a molte situazioni reali, nelle quali persone traducono da un linguaggio direttamente ad un altro, comporta anche una migliore qualità delle traduzioni.
Per sopperire alla potenziale mancanza di dati per il training, in particolar modo per lingue meno diffuse di altre e favorire una ampia collaborazione con altri attori di ricerca, Meta AI ha creato e rilasciato con licenza Open Source, VoxPopuli, un vasto dataset per apprendimento SSL costituito da alcune centinaia di migliaia di ore di registrazioni di discorsi sia annotati che non annotati in alcune decine di linguaggi e relative trascrizioni di traduzioni in altri linguaggi. Inoltre, la ricerca interna in questo ambito si sta muovendo verso un modello di traduzione speech-to-speech, in cui il passaggio intermedio da speech a testo (prima della traduzione nella lingua dello speech di destinazione) viene eliminato completamente.
Quarta sessione: Alborz Geramifard, Research Manager Meta AI
Nella quarta sessione, Alborz Geramifard, Research Manager in Meta AI, ha presentato il progetto CAIRaoke, ultima generazione di assistente virtuale multi-modale, in grado di interagire con esseri umani tramite voce, gesti e testo e rispondere a richieste complesse e difficili da interpretare per un computer. Gli assistenti virtuali attuali sono basati su quattro componenti distinte (Natural Language Understanding, Natural Language Generation, Dialog State Tracking e Dialog Policy Management) che necessitano di essere orchestrate insieme allo scopo di fornire un unico servizio, rendendo difficile l’integrazione nei dispositivi finali, dove l’utente alla fine ha una scelta limitata di opzioni. Situazione molto difficile da ottimizzare e che inevitabilmente comporta scarsa generalizzazione e richiede un lavoro di annotazione di dataset lungo e costoso.
L’obiettivo finale di Meta per il progetto del metaverso è la sua integrazione con tutti i prodotti facente parte dell’offerta del gruppo. Attualmente è già integrato solo in Portal, in futuro sarà anche parte dell’offerta in termini di AR e VR, per fornire agli utenti una esperienza più immersiva e con multiple possibilità di interazione con l’assistente virtuale, inclusi AR glass, e in grado anche di comprendere i bisogni dell’utente.
Tradizionalmente la implementazione di un assistente virtuale integrato con AR glass consta di due parti distinte tra loro: understanding e interaction. La prima è interamente basata su Machine learning, mentre la seconda richiede molto più lavoro ingegneristico che ML. L’idea di Meta AI è stata quella di unificare la parte di ML sia per understanding che quella presente in interaction in un unico modello che funga da interfaccia fra l’utente e diversi servizi, permettendo così anche di eleminare la parte relativa al text-to-speech. In figura 3, uno schema che mostra la transizione da Conversational AI tradizionale a CAIRaoke.
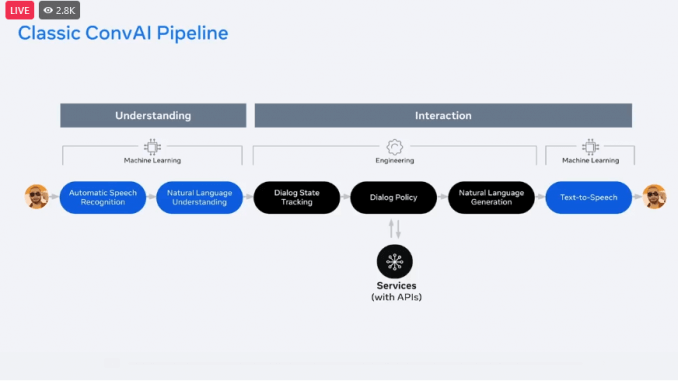

Figura 3 – Conversational IA classica (sopra) e Conversational IA secondo META (sotto)
Le altre sessioni
Prima delle ultime due sessioni si è tenuto un panel moderato da Lex Friedman e che ha coinvolto Yann LeCun (attualmente Chief AI scientist in Meta AI) e Yoshua Bengio (professore ordinario all’Università di Montreal), due dei massimi esperti mondiali di AI e pionieri del Deep Learning, in una conversazione per capire quanto siamo lontani dal raggiungimento di una AI capace di fare ragionamenti comparabili con quelli degli esseri umani. Niente di nuovo per chi è solito seguire questi due grandi protagonisti della ricerca AI: più una conversazione filosofica che altro.
Nella penultima sessione, Jacqueline Pan, Program Manager in Meta AI, ha presentato la nuova area Responsible AI, composta da un team di esperti in diverse discipline e basata su cinque pilastri:
- Privacy & Security
- Fairness & Inclusion
- Robustness & Safety
- Transparency & Control
- Governance & Accountability.
Compito di questa area è far in modo che l’AI sia usata in maniera responsabile nelle varie aree di business del gruppo, verificando che qualsiasi prodotto/servizio implementato in Meta (metaverso incluso) porti beneficio alle persone e alla società. Fra le iniziative di questo gruppo, una menzione speciale va data alla preparazione di un casual conversation dataset privo di bias che viene usato dai ricercatori per la valutazione dei loro modelli di Computer Vision e audio.

Infine, nell’ultima sessione, Irina Kofman, Director and Business Lead in Meta AI, ha aperto le porte del laboratorio di ricerca AI e raccontato brevemente delle sfide necessarie per impostare la ricerca all’interno di una azienda in maniera svincolata dai processi tradizionali e, a differenza di questi ultimi, avere degli obbiettivi aperti nel medio e lungo termine e per favorire una proficua collaborazione con terze parti. I principi su cui si fonda Meta AI Research sono Open Science e collaborazione (come già ribadito in altri interventi), ma anche investimenti sulle persone e integrità.
Video: Inside the Lab
Conclusioni
L’evento è stato chiuso da Zuckerberg e Pesenti che hanno fatto un appello, per chi fosse interessato, ad applicare a qualcuna delle centinaia di posizioni aperte nelle quattro aree funzionali di Meta (Foundational Research, AI for Product, Responsible AI e AI Infrastructure) per irrobustirne l’organico allo scopo di implementare il multiverso.
Alcune considerazioni finali su quanto visto e ascoltato durante le 2 ore e 30 minuti di questo evento:
- Da circa 5 anni, per motivi professionali (parte del mio lavoro consiste nel valutare progetti di ricerca Open Source per capire se questi possano essere applicati a casi d’uso reali nell’ambito in cui lavoro (biotech manufacturing)) seguo con attenzione l’evoluzione, fra gli altri, dei lavori di Meta AI (ex Facebook Research). La maggior parte dei progetti che sono stati condivisi da questo ente sono decisamente brillanti, a differenza di tante ricerche in ambito puramente accademico si prestano potenzialmente a svariati casi d’uso pratici e non banali in diversi contesti, ma apparentemente difficili da inquadrare in casi d’uso del business del gruppo FB. Dopo questo evento, risulta finalmente chiaro quale sia il progetto di lungo termine e che i vari progetti di ricerca siano tutti pezzi di uno stesso mosaico. L’idea del metaverso in Meta non è quindi nata nel 2021, come rivelato dallo stesso Zuckerberg, ma qualcosa che è partita tanto tempo fa.
- Risulta adesso chiaro anche il motivo per cui la maggioranza dei progetti di ricerca AI siano stati rilasciati come Open Source: ufficialmente per favorire l’Open Science e la collaborazione con altre entità (cosa peraltro vera), ma soprattutto per accelerare l’implementazione del metaverso così come immaginato da Zuckerberg & Co.
- A parte l’idea del metaverso come nuovo spazio di socializzazione e collaborazione, non è stato fatto alcun cenno ad altri casi d’uso di business e/o “for good”, che secondo me potrebbero beneficiare delle tecnologie sviluppate (o in fase di finalizzazione) da Meta AI. Apparentemente sembra che il modello di business del gruppo rimarrà quello tradizionale e che il metaverso sia un ausilio a completare la già vasta collezione di dati degli utenti, andando semplicemente a catturare nuove fonti di dati sugli utenti non coperte finora.
- Nessun accenno è stato fatto riguardo problematiche di privacy che inevitabilmente si andranno a creare per via della nuova filosofia di modello multi-modale e unificato e che continua ad apprendere dall’ambiente circostante in applicazioni con esperienza utente in prima persona. Così come non è stata fatta alcuna menzione riguardo un percorso preliminare di etichetta ed educazione degli utenti ai nuovi paradigmi che il metaverso porta con se (così come non c’è stato un percorso educativo di questo tipo quando i social media sono stati aperti alla portata di tutti, con conseguenze anche negative di uso improprio che tutti conosciamo).
- L’area Responsible AI, nonostante sia di primaria importanza, mi sembra ancora immatura, probabilmente perché di costituzione più recente rispetto al resto (e pensata magari solo dopo le varie critiche ricevute dal gruppo a seguito di alcuni scandali come Cambridge Analytica e altri). Importante capirne l’evoluzione e quanto avrà realmente voce in capitolo in seno al gruppo in generale e in particolare in relazione al metaverso.


