
- Con Midjourney e DALL·E la qualità delle immagini generate artificialmente è migliorata significativamente. Questi strumenti utilizzano modelli di diffusione per trasformare descrizioni testuali in immagini dettagliate e coerenti.
- Recenti aggiornamenti, come Midjourney V5.2 e Stable Diffusion SDXL 0.9, hanno introdotto funzionalità avanzate come “Zoom Out”, “high-variation” e miglioramenti nell’inpainting e outpainting, aumentando la qualità e la varietà delle immagini generate.
- Adobe ha integrato la sua AI generativa Firefly in Photoshop e Illustrator, permettendo agli utenti di creare e modificare immagini attraverso prompt testuali. Questa integrazione rappresenta un passo verso la democratizzazione e l’automazione delle competenze tecniche, offrendo strumenti sempre più avanzati e accessibili.
Se qualcuno ci dicesse che una immagine è stata generata attraverso l’intelligenza artificiale generativa, probabilmente non ci stupiremmo. La qualità di output delle immagini alla quale siamo abituati oggi, infatti, è davvero altissima. Eppure, a giugno 2022, appena si iniziava a sentir parlare di Midjourney (con The Economist che ha creato la sua immagine di copertina attraverso l’algoritmo), e a fine settembre 2022 DALL·E (la prima versione) diventava disponibile agli utenti senza white list.

Indice degli argomenti:
AI generativa: i modelli di diffusione
Se la generazione di testo da parte di un modello di linguaggio di grandi dimensioni (LLM), pur essendo un processo non semplice, può essere facilmente compresa attraverso alcuni esempi, il principio alla base della generazione delle immagini è meno intuitivo. Tuttavia, essendo molto affascinante, lo vediamo insieme.
La generazione di immagini di alta qualità guidata da input testuali (prompt) è un compito impegnativo. Richiede una profonda comprensione del linguaggio e la capacità di produrre un output coerente a tale significato. Negli ultimi anni, i modelli di diffusione sono emersi come un potente strumento per affrontare questo problema.
Per fare un esempio della capacità di comprensione richiesta e della complessità di prompt alla quale possiamo arrivare, abbiamo generato l’immagine che segue attraverso Midjourney V4 usando la seguente descrizione (è preferibile formulare il prompt in inglese per ottenere un risultato migliore): “The sun glows brightly in the sky, casting a warm light over the meadow. The grass is a sea of green, rippling in the gentle breeze. A lone Cherry blossom stands tall, its white petals glowing in the sunlight. As you walk closer, you are struck by the beauty of the simple flower. The delicate petals, the delicate stem, the delicate aroma, all combine to create a sense of serenity and peace. You feel as though you have been transported to a different world, a world where nature reigns supreme and beauty is all around”.

Immagine generata con Midjourney V4 attraverso un prompt testuale
I modelli di diffusione, fondamentalmente, sono una classe di modelli generativi probabilistici che trasformano il “rumore” in un campione di dati rappresentativo.
Ma facciamo un passo indietro cercando di semplificare la dinamica.
Tutto inizia con una grande quantità di dati di addestramento: un enorme dataset che associa immagini a un testo che ne descrive il contenuto. Grazie al training su questi dati, gli algoritmi imparano a ricevere un testo in input per produrre un’immagine in output. Allo stesso modo, nel processo inverso (captioning), riescono a ricevere in input un’immagine generando la descrizione testuale.
La tecnica centrale nella generazione di immagini viene definita “diffusion”, o “diffusione”.
Per capire tale processo, immaginiamo di partire da un’immagine nitida aggiungendo progressivamente “rumore”, perturbandola fino a farla diventare puro rumore in una fase definita “diffusione in avanti” (nell’immagine che segue si vede in modo molto chiaro nel percorso da sinistra a destra).
Successivamente, attraverso la “diffusione all’indietro” andiamo a togliere rumore fino a tornare all’immagine nitida.

Un esempio di processo di diffusione. Fonte: Nvidia
L’intelligenza artificiale viene addestrata su questo passaggio, su milioni di esempi, proprio per riuscire a trasformare rumore puro in immagine nitida. Ma quale immagine? Ed ecco che torna in gioco l’addestramento con le descrizioni del quale abbiamo parlato in precedenza. Sarà infatti il nostro prompt a guidare la diffusione. Ecco perché spesso si sente il termine “Text-Guided Diffusion Models”, oppure “conditional image generation”.
Per riassumere, l’intelligenza artificiale, attraverso il processo di diffusione guidata dal testo, riesce a “scolpire” un’immagine a partire da un insieme di parole e rumore. Un esempio affascinante di come la tecnologia riesca a integrare la componente visuale e quella testuale.
AI generativa per le immagini: lo stato attuale
Come abbiamo evidenziato nell’introduzione, siamo al centro di una grandissima evoluzione che ci sta portando ad una qualità sempre più elevata, ma anche a nuove frontiere. Quelli che seguono sono alcuni esempi che credo facciano comprendere in modo efficace tale crescita.
Midjourney 5.2
A giugno Midjourney, uno dei più noti algoritmi di generazione di immagini, ha rilasciato la versione 5.2. Quali sono le novità più interessanti?
- estetica migliorata, le immagini generate risultano essere più nitide e dettagliate. Anche l’aderenza alla descrizione in input, quindi la comprensione della richiesta dell’utente, è nettamente cresciuta.
Come si vede dagli esempi che seguono, il livello di dettaglio è davvero altissimo.

Immagine generata attraverso Midjourney V5.2 da Min Choi

Immagine generata attraverso Midjourney V5.2 da Min Choi
- La funzionalità “Zoom Out” consente di mettere in atto una vera e propria “magia”. Dopo aver generato una immagine, infatti, è possibile ottenere l’effetto che si avrebbe allontanando il soggetto protagonista. Questo porta l’algoritmo a ricostruire lo sfondo estendendolo. Le immagini che seguono ne sono un esempio: a sinistra l’originale, e a destra lo zoom out. E si potrebbe continuare allontanando ancora maggiormente il soggetto.


Immagine generata attraverso Midjourney V5.2 da Min Choi
- La modalità “high-variation“, introduce una maggior varietà nella produzione delle 4 proposte generate. L’esempio che segue è abbastanza esplicativo.

Immagine generata attraverso Midjourney V5.2 da Min Choi
- Abbreviazione. Attraverso il comando /shorten seguito da un prompt, è possibile ottenere dall’algoritmo un’analisi del prompt stesso e dei suggerimenti. Il risultato sarà la creazione di alcune versioni abbreviate che mantengono le parti essenziali del prompt eliminando quelle superflue. Questa è un’ulteriore prova della migliorata capacità di elaborazione della richiesta dell’utente.
Ormai siamo abituati ad una qualità elevata, e quasi non riusciamo più a rimanere sorpresi osservando gli output generati. Tuttavia, credo sia evidente che siamo di fronte a funzionalità e miglioramenti davvero straordinari.
Stable Diffusion SDXL 0.9
Sempre a giugno, Stability AI (azienda che ha sviluppato Stable Diffusion), ha lanciato SDXL 0.9 un nuovo update che rappresenta un notevole balzo in avanti dal punto di vista della qualità.

Immagine che confronta l’output di SDXL Beta con SDXL 0.9 – Fonte: stability.ai
Anche in questo caso siamo di fronte a un’accelerazione degna di nota, infatti la precedente immagine mostra un confronto tra la versione beta di SDXL e l’ultima versione. Tale miglioramento è avvenuto in soli due mesi.
Le novità non riguardano soltanto la qualità. Questo nuovo modello, infatti, include anche la generazione di immagini a partire da un’ulteriore immagine come input, e le funzionalità di “inpainting” e “outpainting”. La prima riguarda la possibilità di costruire informazioni all’interno di una precisa area dell’immagine; la seconda, al contrario, di produrne all’esterno di una determinata area.
Il segreto di questo miglioramento, da quello che emerge dal post di presentazione, è nell’incremento del numero di parametri del modello: il più elevato per un modello open source. Inoltre il risultato viene ottenuto combinando l’output di due modelli combinati tra loro.
Quello che segue è un ulteriore esempio di incremento di performance della nuovissima versione.

Immagine che confronta l’output di SDXL Beta con SDXL 0.9 – Fonte: stability.ai
AI generativa per le immagini: l’ecosistema Adobe
Nella panoramica dell’AI generativa per le immagini non poteva mancare Adobe. Dopo aver lanciato, a fine marzo, la versione beta del suo modello generativo, Firefly, e aver dimostrato grandi potenzialità (vedi immagine seguente) è iniziata l’integrazione nell’ecosistema.

Immagine generata attraverso Adobe Firefly Beta
Nei primi giorni di giugno (solo 3 mesi dopo Firefly), hanno annunciato l’integrazione del loro modello generativo su Photoshop Beta, a disposizione di tutti coloro che possiedono una licenza Photoshop. Il video mostra alcuni esempi di come un grafico, mentre sta elaborando il suo progetto, può usufruire della componente generativa per creare o modificare immagini.
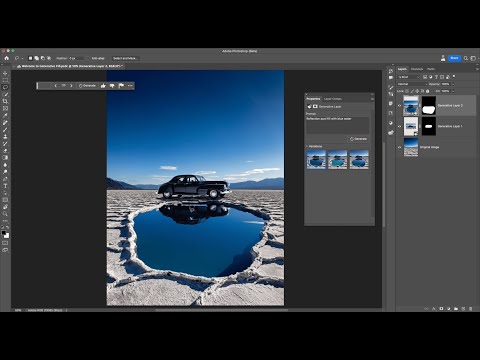
Video: Adobe Photoshop
Quello che segue, è un test in cui si parte da una immagine, la quale viene estesa, vengono aggiunti degli elementi, e infine il cielo cambia decisamente caratteristiche. Il tutto attraverso prompt testuali.

Elaborazione di un’immagine attraverso Photoshop Beta
Durante l’Adobe MAX di Londra, inoltre, è stata presentata l’integrazione con Illustrator, attraverso una funzionalità definita Generative Recolor.

Video: Adobe Firefly
Come si vede dal video, si tratta di un sistema che consente di lavorare sulle colorazioni dei progetti attraverso prompt testuali.
“Illustrator è lo strumento alla base di alcuni dei progetti creativi più iconici al mondo, dai loghi dei brand alle confezioni dei prodotti. Firefly aiuterà i clienti ad accelerare il loro processo creativo e a risparmiare innumerevoli ore, facilitando al contempo nuove possibilità di progettazione”. – Ashley Still, Digital Media di Adobe
Conclusioni
Durante i principali eventi di Google e Microsoft (Google I/O e Microsoft Build) i due colossi ci hanno mostrato come l’AI generativa, probabilmente, sarà protagonista del futuro della ricerca online. Ma ci hanno mostrato anche come questi algoritmi verranno integrati nei loro ecosistemi, che sono anche gli ecosistemi più diffusi al mondo.
Adobe è sintonizzata sullo stesso canale. In pratica avremo un assistente personale, con il quale potremo interagire attraverso il linguaggio naturale, praticamente ovunque.
L’esempio di Meta, con il suo nuovo modello I-JEPA, ci fa fare anche un’ulteriore riflessione. Le architetture sono tutt’altro che definite ed “arrivate”: sono destinate a migliorare e a diventare sempre più innovative e performanti.
Insomma, potremmo sintetizzare la direzione verso il futuro con alcune parole chiave, che sono “integrazione”, “automazione”, “democratizzazione”. La tecnologia tenderà a semplificare sempre maggiormente le hard skill delle persone, estendendone le capacità. Tutto questo lascerà maggior spazio ad aspetti più strategici e meno ripetitivi.


