
Meta ha presentato I-JEPA, un’architettura AI che apprende dal mondo in modo simile a un essere umano, riducendo i tempi e le risorse di calcolo necessari per l’addestramento grazie all’auto-supervisione. Con I-JEPA, sono sufficienti pochi esempi etichettati per permettere a un sistema di computer vision di riconoscere un oggetto. Vediamo in dettaglio come funziona e cosa permette di fare.
Indice degli argomenti:
Un nuovo approccio all’apprendimento automatico
I laboratori di ricerca Meta hanno svelato un nuovo ed efficiente approccio alla computer vision, introducendo un’innovativa architettura neurale chiamata I-JEPA, in grado di emulare l’apprendimento contestuale umano. Gli esseri umani acquisiscono una vasta quantità di conoscenze fondamentali sul mondo attraverso l’osservazione passiva. L’obiettivo di I-JEPA è replicare questo processo di apprendimento, catturando le conoscenze di senso comune sul mondo e codificandole all’interno della rete neurale. La grande novità per i sistemi di computer vision consiste nel fatto che un sistema di questo tipo genera rappresentazioni del mondo esterno in modo auto-supervisionato, utilizzando dati non annotati, come immagini e suoni, a differenza dei tradizionali set di dati etichettati.
Visione umana e computer vision
Il procedimento attraverso il quale osserviamo e comprendiamo la realtà è complesso. Attraverso processi fisici, percepiamo i fotoni che si proiettano e si riflettono sul mondo, trasmettendo al nostro sistema nervoso centrale segnali elettrici. Successivamente, il cervello, mediante processi cognitivi, interpreta queste informazioni consentendoci di associarle a concetti complessi. In questo modo, siamo in grado di riconoscere oggetti, colori, forme e movimenti.
La computer vision è una disciplina dell’intelligenza artificiale che mira a dotare le macchine della capacità di “vedere” ed elaborare informazioni visive in modo simile agli esseri umani. Ciò si ottiene mediante l’uso di telecamere e algoritmi di elaborazione delle immagini che analizzano i pixel di ogni foto. L’obietto della computer vision è riconoscere gli oggetti presenti nelle immagini, identificarne i contorni, classificarli in base a pattern e forme, e monitorarne gli spostamenti nel tempo.
Per quanto riguarda l’elaborazione dell’informazione visiva, nell’uomo il nervo ottico svolge la funzione di trasmettere i segnali elettrici dalla retina al lobo occipitale del cervello, dove vengono interpretati i segnali visivi. Nel caso della computer vision, le immagini catturate dalla telecamera vengono processate utilizzando algoritmi di elaborazione delle immagini e tecniche di apprendimento automatico o profondo.
Gli esseri umani riescono a riconoscere istantaneamente e automaticamente oggetti, volti e altre caratteristiche visive grazie all’apprendimento e all’esperienza accumulata nel corso della vita. Al contrario, la computer vision si avvale di algoritmi di riconoscimento delle forme, di classificazione e raggruppamento per identificare gli oggetti presenti nelle immagini.
Una volta riconosciuti gli oggetti, il cervello umano può elaborare una risposta adeguata alla situazione, come una decisione o un’azione. Anche i sistemi di computer vision sono in grado di compiere azioni basate sulle informazioni visive acquisite, come guidare un veicolo autonomo o controllare un braccio robot.
Come funziona I-JEPA

I-JEPA è un modello di AI per la visione artificiale sviluppato da Yann LeCun, Chief AI Scientist presso Meta, con lo scopo di creare sistemi di computer vision che emulino la visione umana. A differenza degli approcci tradizionali, I-JEPA apprende generando un modello interno del mondo esterno e confrontando le rappresentazioni astratte delle immagini, piuttosto che i singoli pixel.
L’addestramento di I-JEPA avviene attraverso un metodo auto-supervisionato, il quale impiega esclusivamente dati non etichettati, come ad esempio immagini, al fine di acquisire rappresentazioni astratte del mondo. Tale sistema utilizza due reti neurali: un encoder di contesto e un encoder di target. L’encoder di contesto riceve in input una porzione dell’immagine e genera una rappresentazione relativa al contesto. Analogamente, l’encoder di target elabora un’altra sezione dell’immagine e produce una rappresentazione del target. Il modello mira a prevedere la rappresentazione del target basandosi sulla rappresentazione del contesto.
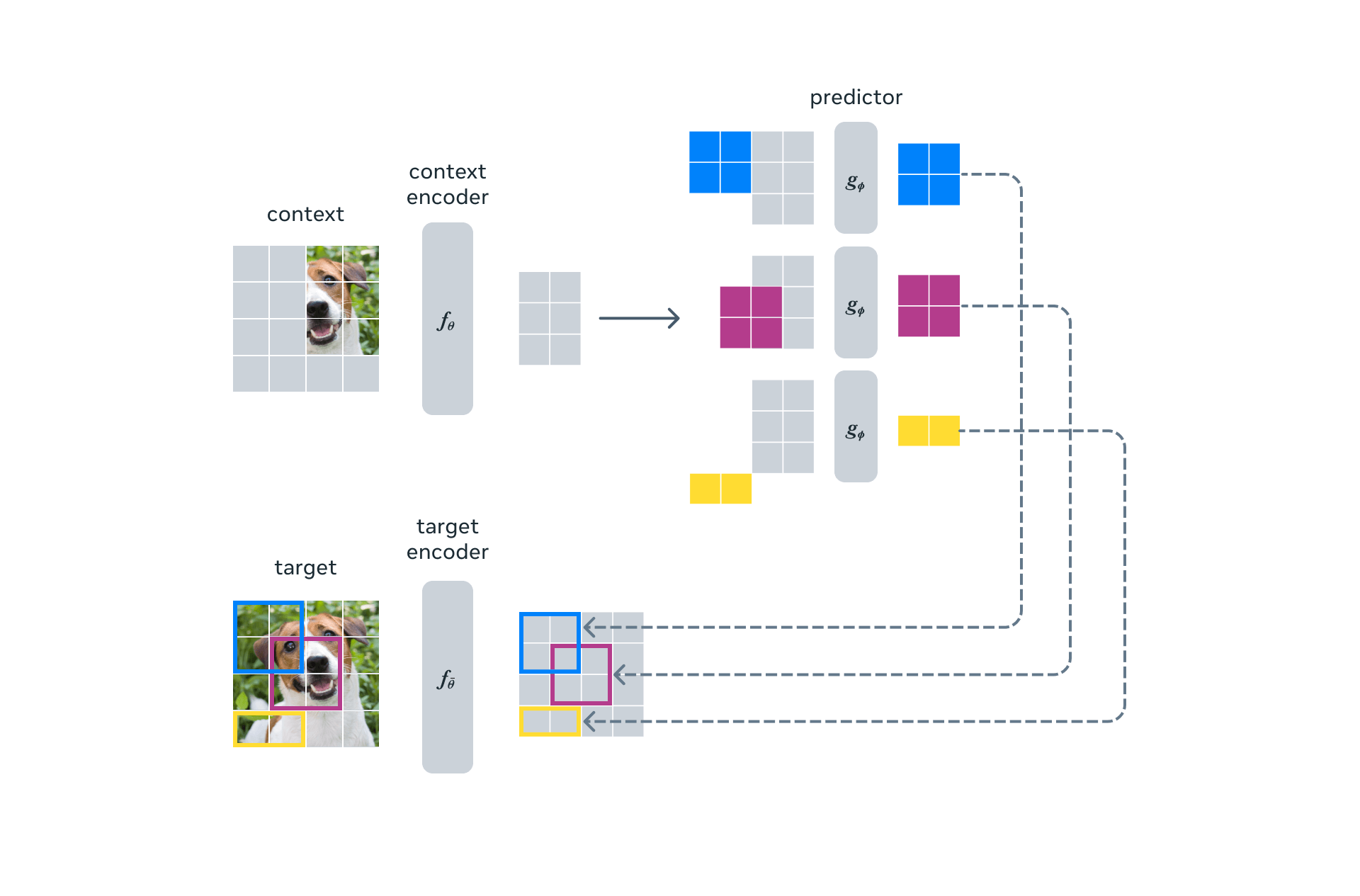
I-JEPA migliora la computer vision prevedendo dati mancanti in modo simile al cervello umano, focalizzandosi sulle informazioni essenziali piuttosto che sui dettagli a livello di pixel. Così facendo, considera il contesto ed è in grado di predire informazioni rilevanti sulle aree nascoste dell’immagine.
Meta ha riportato che I-JEPA ha ottenuto risultati eccellenti durante una serie di test su differenti task di computer vision, dimostrando una notevole efficienza computazionale rispetto ad altri modelli comunemente utilizzati. Inoltre, le rappresentazioni acquisite da I-JEPA possono essere utilizzate in diverse applicazioni senza richiedere addestramenti specifici.
I ricercatori di Meta affermano di aver addestrato un modello di visual transformer con 632 milioni di parametri usando 16 GPU A100 in meno di 72 ore, ottenendo un’accuratezza record nella classificazione con soli 12 esempi etichettati per classe. Metodi alternativi richiedono solitamente dalle 2 alle 10 volte più ore di GPU per il training, registrando un’accuratezza inferiore con la stessa quantità di dati etichettati.
Meta ritiene che I-JEPA evidenzi il grande potenziale delle architetture in grado di apprendere senza la necessità di conoscenze aggiuntive codificate tramite trasformazioni di immagini elaborate manualmente. I ricercatori dell’azienda metteranno a disposizione il codice di addestramento di I-JEPA e i checkpoint del modello. In futuro, l’obiettivo sarà quello di estendere questo approccio ad altri ambiti, come testi associati alle immagini e video.
I-Jepa, i possibili scenari applicativi futuri
I-JEPA ha mostrato risultati promettenti in vari altri domini, oltre alla computer vision. Lo stesso concept può essere impiegato per semplificare l’addestramento delle reti neurali in diverse aree, come la sanità, la finanza e l’elaborazione del linguaggio naturale. L’architettura di I-JEPA può anche essere utilizzata per generare schizzi di oggetti partendo dalle loro rappresentazioni astratte. Inoltre, I-JEPA può essere integrato con altri modelli di apprendimento automatico già esistenti per potenziarne le capacità di ragionamento e pianificazione.
Conclusione
In futuro, i modelli di apprendimento automatico evolveranno per incrementare il livello di astrazione nella rappresentazione del contesto. Sarà affascinante osservare le applicazioni pratiche dei modelli capaci di apprendere schemi e strutture dal mondo reale, in grado di effettuare previsioni spaziali e temporali a lungo termine riguardo a eventi futuri, basandosi solo su un numero limitato di informazioni iniziali. I-JEPA rappresenta un importante passo in avanti verso l’applicazione e la scalabilità dei metodi auto-supervisionati nell’apprendimento di un modello generale del mondo.



