I progressi delle architetture Deep Neural Network nell’ultimo decennio hanno permesso di realizzare applicazioni di Computer vision in disparati settori, che includono anche casi in cui i sistemi che ne ospitano i modelli sono in campo aperto, quali ad esempio guida autonoma o supporto ai conducenti di veicoli, sicurezza sul lavoro, videosorveglianza, droni, etc. Purtroppo, parallelamente all’evoluzione di questi sistemi, è venuta alla luce una nuova specifica famiglia di minacce, i cosiddetti Adversarial Attacks.
Come già ben spiegato, questo tipo di attacchi sfrutta una vulnerabilità insita nel processo di training degli algoritmi stessi in modo da creare input ingannevoli che invalidano l’output e che possono causare conseguenze più o meno gravi a persone e/o cose.
Quale potrebbe essere una potenziale strategia di difesa, atta a mitigare gli effetti di Adversarial Attacks e quali i conseguenti impatti economici e di performance sulla implementazione di un’architettura di rete neurale che risulta minore se confrontato con altre soluzioni aventi la stessa finalità?
Indice degli argomenti:
Tipologie di Adversarial Attacks
Esistono due diverse tipologie di Adversarial Attacks: naturali e sintetici.
Gli attacchi di tipo naturale non sono generati facendo uso di tecnologia e non necessariamente partono da un intento malevolo.
In figura 1 un esempio di Adversarial Attack naturale:

Figura 1 – Esempio di Adversarial Attack di tipo naturale senza intento malevolo
In questo esempio la presenza di una griglia tra la farfalla e l’obiettivo della fotocamera andrà a influire sul risultato di un modello di rete neurale predisposto per fare image classification o detection, ma si tratta di un evento casuale.
La Figura 2 mostra un esempio di Adversarial Attack naturale generato da un’azione illegale (il risultato di qualcuno che ha usato un cartello di segnaletica stradale come bersaglio per la sua arma da fuoco) che, nonostante non fosse nelle intenzioni di chi ha esploso i colpi contro il cartello, andrà per esempio a inficiare il risultato di un modello di rete neurale predisposto al riconoscimento di segnaletica stradale.

Figura 2 – Esempio di Adversarial Attack naturale a seguito di una azione illegale
Gli Adversarial Attacks di tipo sintetico sono eseguiti aggiungendo delle perturbazioni all’immagine/fotogramma originale (figura 3), ma senza alterare le proprietà semantiche della stessa, che all’occhio umano continuerà ad apparire inalterata (facendo però fallire il modello neurale). A differenza di quelli naturali, gli Adversarial Attacks sintetici hanno sempre un intento malevolo. Focalizziamo l’attenzione su quest’ultima (e più pericolosa) tipologia di attacchi.

+

=
Figura 3 – Adversarial Attack di tipo sintetico
Adversarial Attack di tipo sintetico
Gli attacchi di tipo sintetico possono essere randomici oppure mirati. Nel primo caso l’intento dell’attaccante è semplicemente quello di far fallire il modello di rete neurale alla base del sistema di Computer vision sotto attacco (fargli produrre qualsiasi risultato diverso da quello più simile al valore reale). Nel secondo caso invece l’intento dell’attaccante è quello di forzare un modello a produrre uno specifico risultato errato.
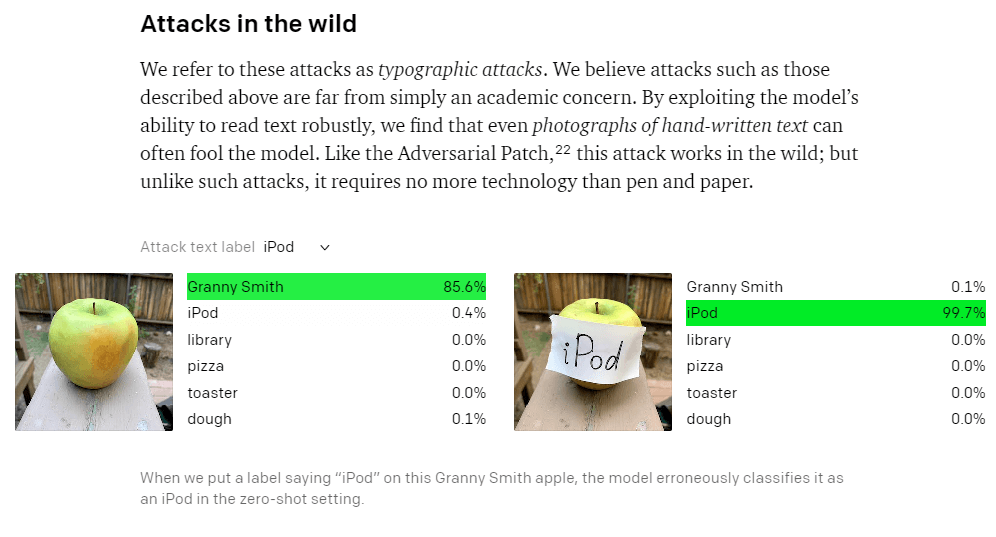
Questi attacchi sono principalmente di tipo “black box”: l’attaccante non necessita di avere accesso al modello fisico (che nella maggior parte dei casi non risulta facilmente accessibile in quanto installato dentro un solido perimetro di sicurezza) e informazioni sulla sua completa architettura, ma agisce in maniera da comprenderne il comportamento agendo sugli input per lo stesso. In precedenza, ho accennato a una debolezza intrinseca del processo di apprendimento della rete neurale che viene sfruttato per portare avanti questo tipo di attacchi. Per comprenderlo, e anche per capire perché un’immagine alterata dopo un attacco continua a essere simile a quella originale, bisogna ricordare qual è il flusso iterativo dell’apprendimento di una rete neurale (rappresentato in figura 4).
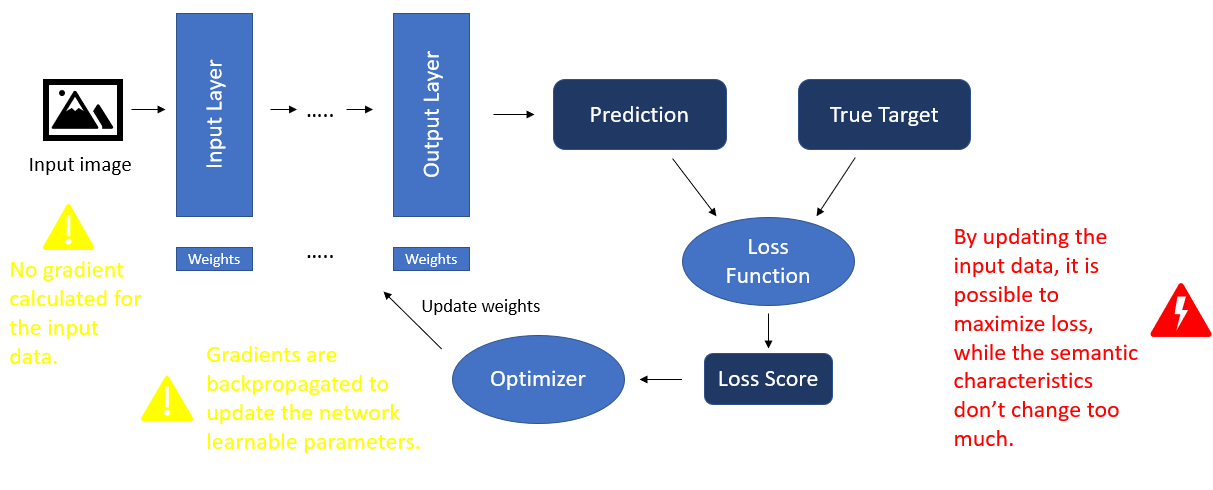
Figura 4 – Schema del processo di apprendimento di una rete neurale.
Ciascuna immagine che fa parte del set di dati per il training e che viene quindi data in input alla rete passa attraverso i vari layer dell’architettura generando alla fine una predizione. Il risultato generato viene passato insieme al valore atteso per l’immagine di input ad una funzione detta loss function, la quale genera uno score che a sua volta viene passato al componente della rete detto optimizer, che ha il compito di eseguire l’update dei pesi per i parametri della rete in modo da minimizzare l’errore. Come si evince da questo schema, la back propagation modifica solo i parametri del modello e non agisce sui dati (immagini/fotogrammi) in input. Quindi, modificando opportunamente il contenuto della immagine di input, pur senza alterarne le caratteristiche semantiche, è possibile massimizzare l’errore per il risultato ottimale e allo stesso tempo minimizzarlo per un qualsiasi altro risultato (attacco randomico) o uno specifico (attacco mirato).
Adversarial Attacks sintetici possono essere eseguiti mediante diverse tecniche, quasi tutte basate su Generative Adversarial Networks (GAN, architetture composte da due reti neurali in competizione, da cui l’aggettivo adversarial nel nome, che appunto in inglese significa letteralmente antagonistico, l’una con l’altra per produrre le immagini alterate). Ecco una lista non esaustiva di alcune delle metodologie più diffuse:
- FGSM (Fast Gradient Sign Method)
- PGD (Projected Gradient Descent)
- Carlini & Wagner
- EAD (o Elastic-net Attack)
Alcune tecniche sono single-step, altre iterative. Quelle che ricadono nella prima categoria hanno una maggiore trasferibilità (possono cioè essere usate contro diverse architetture di reti neurale), ma la probabilità di riuscita di un attacco risulterà bassa per alcune architetture. Al contrario, quelle iterative possono essere usate per attaccare un ristretto numero di architetture, ma sono molto più efficaci delle single-step.
Una potenziale strategia per mitigare gli effetti di Adversarial Attacks
La varietà di tecniche e architetture GAN già a disposizione degli attaccanti e la continua evoluzione delle stesse contribuiscono a rendere ardua l’implementazione di una strategia difensiva. Oltre a questo aspetto non bisogna trascurare anche l’impatto economico (costi extra per mettere in sicurezza un modello di rete neurale).
Una soluzione che tiene conto di fattori sia di scalabilità sia economici parte dal presupposto che il processo di apprendimento di un modello non venga toccato. Quindi il modello serializzato ottenuto alle fine del training regolare e che in fase di test ha soddisfatto tutte le KPI di performance viene utilizzato così com’è. Quello che cambia è il fatto di non passare le immagini in input direttamente al modello, ma di anteporre allo stesso due layer di randomizzazione in sequenza: il primo esegue un ridimensionamento random della immagine in input (con intervallo di valori non troppo grande intorno alle dimensioni previste per il layer di input della rete neurale), il secondo invece, prendendo in ingresso l’output del primo layer, introduce un padding (aggiunta di spazi a uno dei lati dell’immagine) in maniera randomica. Il passaggio attraverso i due nuovi layer rimuove gran parte delle perturbazioni introdotte dall’attaccante, a prescindere dalla tecnica da esso usata. L’immagine così “ripulita” viene quindi data in ingresso al modello, il quale nella maggioranza dei casi produrrà il risultato corretto, anche se con un confidence score un po’ più basso rispetto al caso in cui l’immagine originale fosse stata passata allo stesso. Il compromesso, quindi, è di avere risultati più sicuri a leggero discapito della precisione.
La figura 5 mostra lo schema logico della soluzione appena spiegata.
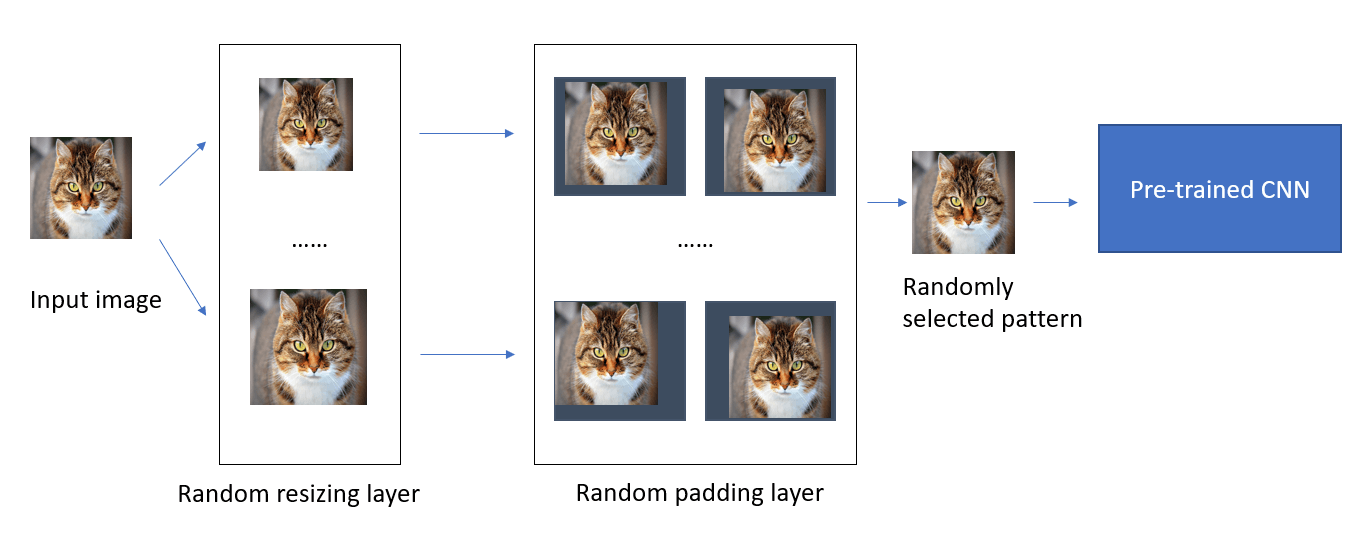
Figura 5 – Schema logico di una strategia per ridurre le perturbazioni aggiunte a un’immagine per condurre un Adversarial Attack
Ecco quali sono i vantaggi di una soluzione di questo tipo rispetto ad altre, quali, ad esempio, training del modello, includendo adversarial samples nel data set o simulando Adversarial Attacks durante il training stesso:
- Nessuna necessità di eseguire di nuovo (nel caso il modello serializzato sia già disponibile) o di modificare la procedura di training regolare della rete neurale: questo si traduce in un notevole risparmio in termini di tempo ma anche di costi, in quanto non è necessario consumare ulteriori risorse, quali ad esempio GPU, Cloud storage, network, etc.
- L’introduzione dei due nuovi layer aggiunge un payload trascurabile al processo di inference del modello: quindi le performance anche di applicazioni real time or near real time non subiranno un impatto significativo.
- La tecnica proposta è agnostica rispetto all’architettura della rete da proteggere. Praticamente è compatibile con qualsiasi architettura CNN. Quindi nessuna necessità di modificarne lo schema originale.
- Anche l’impatto sulla precisione del modello è minimo. I benchmark di questa tecnica mostrano performance comparabili per le principali architetture CNN.
- Infine, la tecnica proposta è agnostica della tecnica di attacco utilizzata. Quest’ultimo rappresenta un grandissimo vantaggio, in quanto il panorama delle tecniche di attacco basate su GAN è in continua evoluzione e comunque è impossibile prevedere a priori quale tecnica un eventuale attaccante utilizzerà contro il nostro sistema.
Ovviamente nulla vieta, in casi in cui tempo e budget non presentino vincoli molto stretti, di applicare la tecnica proposta insieme ad altre (quali ad esempio rieseguire il training della rete dopo aver incluso i due nuovi layer) o utilizzare tecniche di pre-processing defence.
Conclusioni
Purtroppo, nonostante siano state individuate da alcuni anni (già Google nel 2014) e siano una concreta realtà, queste tipologie di rischio non hanno ancora la dovuta attenzione. Recentemente il trend sta cambiando, ma si osservano ancora solo iniziative isolate da parte di alcune aziende big tech e non sforzi congiunti a livello più ampio. A titolo di esempio, nella lista dei top 15 threats di ENISA (the European Union Agency for Cybersecurity) non c’è alcun accenno ad Adversarial Attacks.
Per fortuna alcune tecniche efficaci come quella dettagliata in questo articolo per mitigare gli effetti di questo tipo di attacchi sono già disponibili, quindi le aziende con il giusto livello di maturità in termini di cyber sicurezza possono attingere da metodologie e casi d’uso esistenti in modo da accelerare i loro sforzi per rendere i loro modelli di rete neurale più robusti. Un limite delle soluzioni esistenti è rappresentato dal fatto che esse sono specializzate per CNN, architetture di reti neurali basati su layer convoluzionali.
Le CNN sono lo stato dell’arte per applicazioni di Computer Vision, ma un altro tipo di architettura detta transformer, originariamente pensata per applicazioni di NLP (Natural Language Processing), recentemente sta iniziando ad essere utilizzata anche in casi di Computer Vision. Anche i transformer sono soggetti a specifici Adversarial Attacks (un esempio in figura 6), ma a causa delle differenze con le reti neurali convoluzionali, tecniche difensive esistenti per queste non possono essere riutilizzate. Ma anche su questo fronte qualcosa si sta per fortuna muovendo.