Parallelamente allo scoppio ed evoluzione della pandemia di COVID-19 si è registrato un incremento del fenomeno delle fake news. L’intelligenza artificiale (IA) può avere un duplice ruolo in questo contesto: da un lato fornisce un ottimo supporto per la individuazione di contenuti fake, ma allo stesso tempo è utilizzata per la generazione degli stessi. I cosiddetti visual deepfakes sono contenuti digitali (immagini o video) generati artificialmente per mezzo di tecniche basate su AI e che coinvolgono in particolare i volti dei soggetti ivi raffigurati .
Vediamo in dettaglio alcuni dei principali algoritmi specifici per la generazione di visual deepfakes, quali sono le difficoltà nell’individuazione di un contenuto visuale contraffatto e quale potenziale strategia per poterne prevenire la diffusione.
Indice degli argomenti:
Pericoli derivanti dalla diffusione di deepfakes
I deepfake possono minare molti dei valori su cui si basa la civiltà moderna, quali ad esempio la dignità delle persone, la libertà, la democrazia, l’uguaglianza e i diritti umani. Essi possono essere utilizzati per influenzare l’opinione pubblica in modo da far credere a una platea molto vasta in qualcosa che non è reale. Le conseguenze sono molteplici: influenza sull’esito di elezioni politiche, danneggiamento della reputazione di persone e/o organizzazioni, diffusione di false nozioni scientifiche, disordini sociali, generazione di forti impatti emozionali di massa e agevolazione di ogni genere di truffa basata su social engineering. Insomma, i deepfake sono un fenomeno che non può essere ignorato e verso il quale bisogna avere un approccio proattivo, prima che il problema vada fuori controllo.
Già adesso diversi casi eclatanti si sono verificati, quali ad esempio, la pubblicazione su Facebook ad Aprile 2020 di un deepfake video[2] che mostrava il Primo Ministro del Belgio Sophie Wilmes parlare di una possibile connessione tra la deforestazione e la diffusione del virus COVID-19. In sole 24 ore il video aveva superato le centomila visualizzazioni e ricevuto tantissimi commenti di utenti che avevano percepito tale video come autentico.
Mentre fino a qualche anno fa sofisticate e costose tecnologie per la creazione di visual deepfakes erano appannaggio solo di università e studios hollywoodiani, i recenti e rapidi progressi nel Deep Learning e l’accesso ad algoritmi open source, database di immagini e video free per il loro training e tecnologie di calcolo a basso costo (on-premises o nel cloud) da parte di una più ampia fetta di popolazione hanno consentito anche a singoli individui di poter realizzare visual deepfakes difficilmente distinguibili da contenuti reali.
A titolo di esempio, l’immagine sotto rappresenta un deepfake molto realistico generato da zero da me stesso con meno di un’ora di coding e pochi secondi di esecuzione per un singolo deepfake utilizzando un computer dotato di una sola GPU, 16 GB di RAM e 12 CPU. La donna ivi raffigurata non esiste nella realtà.

Esempio di home-made deepfake
Tecniche di generazione di visual deepfakes
I visual deepfakes possono essere classificati come appartenenti a una delle seguenti tipologie:
- sintesi facciale completa
- manipolazione di attributi di un’immagine/fotogramma
- sostituzione di identità
- sostituzione di espressione
Il denominatore comune a tutte e quattro è il ricorso al Deep Learning[3] (DL, una specializzazione del Machine Learning che fa uso di reti neurali artificiali) e Generative Adversarial Networks (GAN). Una GAN è un’architettura composta da due reti neurali in competizione (da cui l’aggettivo adversarial nel nome, che appunto in inglese significa letteralmente antagonistico) l’una con l’altra. Sono usate principalmente in quei casi dove è necessaria la generazione di dati (di diversa natura, tra cui anche immagini). La prima delle due reti neurali coinvolte è chiamata generator ed è quella che genera nuovi dati. Questi ultimi vengono quindi dati in pasto alla seconda rete, chiamata discriminator, che viene addestrata a discernere i contenuti creati artificialmente da quelli reali. Il compito del generator è quindi quello di trarre in inganno il discriminator e, sfruttando le risposte fornite dal discriminator, è programmato per migliorarsi in modo da creare dati sempre più simili a originali. La seguente figura mostra il tipico flusso di una GAN in cui i dati coinvolti sono immagini:
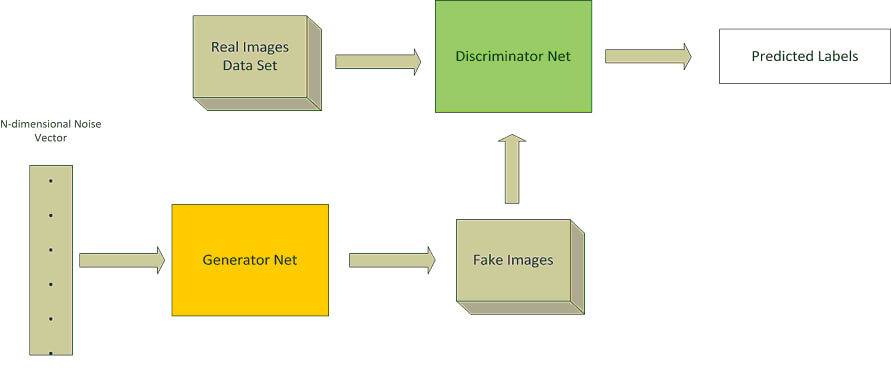
Un esempio di architettura GAN[4]
Attualmente esistono diverse tecniche GAN-based utilIzzate per la generazione di deepfakes, ognuna specifica per una delle quattro tipologie elencate in precedenza. Ecco una breve panoramica di quelle Open Source più diffuse.
StyleGAN, introdotta da NVIDIA nel 2018, e la sua più recente implementazione StyleGAN 2, sono indicate per casi di sintesi facciale completa. La proposta di NVIDIA è un passo da gigante grazie alla implementazione alternativa (se comparata con le precedenti architetture GAN) della generator neural network. La nuova architettura introduce un apprendimento automatico senza supervisione e in maniera separata per gli attributi di alto livello (quali ad esempio, nel caso di volti umani, la posa e l’identità), una variazione di tipo stocastico nelle immagini che vengono generate e inoltre consente un maggior controllo del processo di sintesi. In questo modo la qualità finale delle immagini risulta nettamente superiore a quella ottenibile con precedenti GAN.
La manipolazione di attributi di una immagine consiste, come si evince dal nome, nella modifica di uno o più attributi facciali (colore della pelle, età, sesso, aggiunta di occhiali, cambio pettinatura, etc.). StarGAN, introdotta da CLOVA AI Research, e la sua più recente implementazione StarGAN 2, rappresenta lo stato dell’arte nei casi di manipolazione di attributi. StarGAN ha dato una grande accelerata al processo di image-to-image translation tra domini multipli. I modelli precedenti, a causa di una scalabilità limitata, non erano in grado di operare in più di due domini, facendo sì che si dovesse ricorrere a diversi modelli indipendenti per poter effettuare image-to-image translation tra multipli domini. StarGAN invece rappresenta un unico modello per eseguire lo stesso tipo di operazioni. Inoltre questa soluzione ha contribuito a fornire una qualità delle immagini finali superiore alle soluzioni in cui precedentemente si utilizzavano più modelli.
Il modo in cui StarGAN è stata implementata la rende anche un ottimo approccio per i casi di sostituzione di espressione o di identità, ma altre tecniche come Neural Textures, proposta dalla Technical University di Monaco di Baviera e Stanford University, in cui la rete neurale generator, a differenza di quelle di altre implementazioni GAN, la cui natura è principalmente una sorta di black box bi-dimensionale, utilizza una rappresentazione tri-dimensionale che fornisce più controllo esplicito sull’output che essa genera. Questo fa si che possa essere utilizzata anche su input 3D di non eccelsa qualità e in casi d’uso di manipolazione di contenuti video in real-time.
Una potenziale strategia di identificazione dei visual deepfakes
Come descritto nel paragrafo precedente, le tecniche attuali di generazione di deepfakes sono basate su DL e GAN (lo stesso per nuove tecniche a venire nel breve e medio termine). I tentativi di generazione di visual deepfakes utilizzando le prime generazioni di GAN erano soliti produrre immagini e video in cui spesso difetti erano evidenti anche a occhio nudo, rendendo la identificazione di manipolazioni più semplice. Non è più il caso con le recenti generazioni.
Le sfide da affrontare in questo contesto sono legate al fatto di non poter disporre delle immagini/fotogrammi di partenze e alla varietà di algoritmi utilizzati dai creatori di deepfakes. Sarebbe ideale quindi identificare una strategia di identificazione agnostica rispetto all’architettura GAN utilizzata dagli autori di deepfake. Ciò è possibile ponendo l’attenzione sulle caratteristiche intrinseche delle immagini sotto esame: in questo modo non si ha la necessità di dover accedere al contenuto originale (prima della contraffazione) dei deepfakes. Come fare in pratica? Si ricorre al DL: così come i deepfakes sono generati via DL, le stesse armi si usano anche per identificarli. Una strategia vincente plausibile in questa direzione è composta da due fasi. La prima si basa sulla ricerca di perdite di contrasto come caratteristiche tipiche di immagini/fotogrammi video generati tramite diverse tecniche basate su GAN. La seconda fase è quindi quella in cui un classificatore ha il compito di discernere contenuti leciti da fake. La seguente figura riassume l’idea appena descritta:
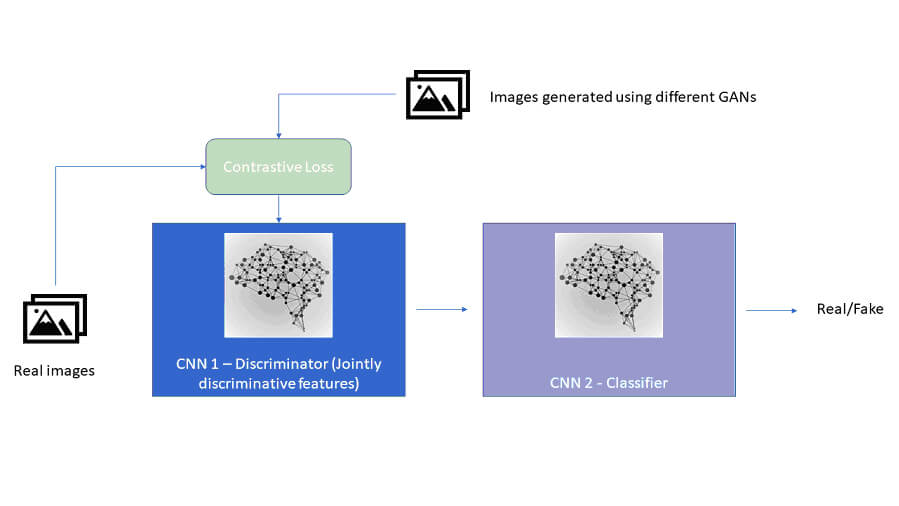
Schema logico di una strategia per l’individuazione di deepfake basata su una caratteristica intrinseca delle immagini
Come si evince dalla figura, l’architettura proposta è basata su DL: infatti sono presenti due Convolutional Neural Network (CNN)[5], reti neurali specializzate in problemi di Computer Vision. La prima CNN, detta Discriminator, è stata addestrata a imparare caratteristiche discriminatorie utilizzando un data set di immagini reale e uno di deepfakes generati utilizzando diverse implementazioni di GAN. La seconda CNN, detta Classifier, viene istruita utilizzando l’output del Discriminator ed è quella che che esegue la classificazione delle immagini/fotogrammi (vere o fake) tramite individuazione di dettagli non realistici. In questo modo è evidente che, al sorgere di nuove tecniche di deepfake basate su GAN, non sarà necessariemente richiesto eseguire di nuovo il training del Discriminator aggiungendo al data set di deepfake nuovi campioni generati tramite le nuove architetture, in quanto il tutto è basato su caratteristiche intrinseche, rendendo così la soluzione robusta nel tempo.
Conclusioni
Attualmente la capacità di individuare e quindi bloccare contenuti fake è completamente demandata ai gestori dei principali social network (nel caso di immagini e video, una grossa fetta viene con altissima probabilità pubblicata su YouTube, Facebook, Instagram, Twitter, Linkedin o condivisa attraverso Whatsapp). Quindi l’onere spetta a uno sparuto numero di corporazioni che, oltre al rischio che esse possano assumere ruoli di censori e difensori della democrazia in maniera tacita (con tutti i rischi che ne conseguono), a mio avviso non hanno interesse a investire in strumenti tecnologici di ausilio alla lotta ai deepfakes (e contenuti fake in generale), sia per motivi di ritorno economico, sia per altre motivazioni di tipo “politico”. L’unica iniziativa concreta, di cui si parla da circa due anni e che sembra finalmente verrà alla luce negli ultimi mesi del 2020, è di Microsoft, implementata sulla loro piattaforma cloud Azure e che, guarda caso, diventerà operativa in coincidenza con le elezioni presidenziali USA di novembre[6].
Iniziative come quella di Microsoft (o altre che dovessero venire da altre parti coinvolte, quali ad esempio Google o Facebook), oltre che essere proprietarie e potenzialmente soggette a bias di diverso tipo, non sarebbero comunque disponibili per tutti i consumatori web, ma solamente per quelli aventi una sottoscrizione ad una specifica piattaforma o servizio. Ritengo che di questo tipo di iniziative, atte a prevenire conseguenze gravi su persone, imprese e governi, si debbano fare carico gli Stati e altre istituzioni come per esempio la UE, e che si debba creare una collaborazione mondiale per trovare ed implementare soluzioni al problema descritto in questo articolo, che dovrebbero inoltre diventare parte dell’architettura del World Wide Web e non di singole piattaforme o servizi cloud: solo così si potrà pensare di identificare i contenuti falsi e bloccarli prima che essi possano raggiungere, se non tutti, almeno la grande maggioranza gli utenti finali. Finora nessun segnale concreto in questa direzione. La speranza è che la stalla non venga chiusa dopo che saranno già scappati i buoi.
- https://spectrum.ieee.org/facebook-ai-launches-its-deepfake-detection-challenge ↑
- https://www.brusselstimes.com/news/belgium-all-news/politics/106320/xr-belgium-posts-deepfake-of-belgian-premier-linking-covid-19-with-climate-crisis/ ↑
- https://www.forbes.com/sites/bernardmarr/2018/10/01/what-is-deep-learning-ai-a-simple-guide-with-8-practical-examples/#1c501f788d4b ↑
- Immagine tratta dal libro “Hands-On Deep Learning with Apache Spark” di Guglielmo Iozzia, Packt Publishing, 2019 – https://www.packtpub.com/product/hands-on-deep-learning-with-apache-spark/9781788994613 ↑
- https://en.wikipedia.org/wiki/Convolutional_neural_network ↑
- https://www.cnet.com/culture/microsoft-can-identify-deepfakes-now-just-in-time-for-the-2020-us-election/ ↑


