
L’epidemia Covid-19 che si è abbattuta sulle nostre società ha portato con sé paura e incertezza. Le persone di tutti i paesi si sono affidate ai diversi medium informativi per ricercare le ultime notizie, informazioni sull’andamento della malattia, sui metodi per proteggersi e sulle cure, come già discusso su Agenda Digitale. La crescita del volume di informazioni – vere, verosimili o decisamente false – sull’epidemia in corso ha mosso l’Organizzazione Mondiale della Sanità (OMS) a parlare di vera e propria “infodemia” in riferimento a notizie che “si diffondono più velocemente e più facilmente del virus stesso”.
La situazione di emergenza ha spinto tutti i soggetti coinvolti ad adottare, in parallelo alle misure sanitarie e, tutto sommato, in supporto a queste, delle misure di contenimento dell’infodemia di fake news attraverso l’implementazione di diverse strategie. Ad esempio, l’OMS ha costituito un team di esperti che collaborano con istituti di ricerca e social media come Facebook, Google, Pinterest, Tencent, Twitter, TikTok, YouTube e altri, proprio per contrastare la diffusione di voci non verificate o false. I social media procedono poi a filtrare consigli su pratiche sanitarie non verificate, bufale e altre false informazioni che, secondo gli esperti, potrebbero mettere a rischio la salute pubblica. L’eliminazione di contenuti ritenuti falsi o dannosi si è spinta al punto che Tweeter ha censurato un video del presidente brasiliano, Jair Bolsonaro, accusato di diffondere disinformazione sul virus (fonte Onu).
Oltre alla rimozione di contenuti considerati non veritieri, molti siti rispondono alla ricerca di informazioni sul Covid-19 rimandando alle fonti ufficiali, nazionali o internazionali, mentre Whatsapp ha modificato il proprio software per impedire di effettuare il forward dei contenuti “troppo diffusi” a più di una persona alla volta, in modo da rendere più difficile la “viralizzazione” degli stessi.
Indice degli argomenti:
Come arginare le fake news: fa uso di AI il modello di Facebook
Nel suo ultimo Community Standards Enforcement Report, Facebook mostra i risultati conseguiti dai propri sistemi di intelligenza artificiale per arginare il diffondersi di diverse categorie di contenuti offensivi o pericolosi: hate speech, disinformazione, bullismo, pedofilia, contenuti violenti.
Il successo ottenuto per alcune di queste categorie è molto rilevante: ad esempio, per i post di incitamento all’odio Facebook afferma che l’88,8% di tutti i post rimossi in questo trimestre è stato rilevato dall’AI, in crescita rispetto all’80,2% del trimestre precedente.
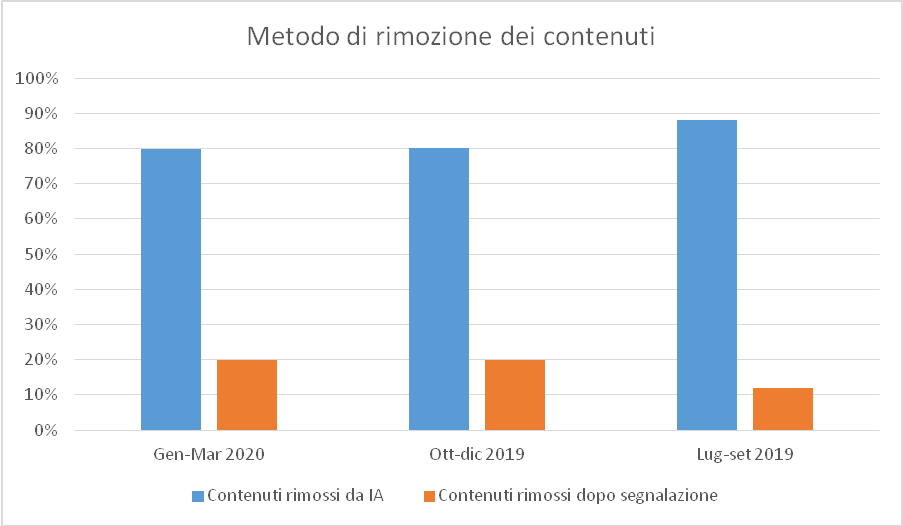
Elaborazione dell’autore su dati Facebook
Il sistema automatico può rimuovere automaticamente i contenuti se ha un alto grado di confidenza nel fatto che si tratti di post che incitano all’odio, anche se la maggior parte di essi viene comunque controllata una seconda volta da un revisore umano.
Questi risultati sono in gran parte dovuti a due aggiornamenti dei sistemi di AI di Facebook. Grazie al primo, l’azienda sta ora utilizzando modelli del linguaggio naturale che possono decifrare meglio la sfumatura e il significato di un post. Questi modelli si basano sui progressi della ricerca sull’AI degli ultimi due anni, che permettono alle reti neurali di essere addestrate sul linguaggio senza alcuna supervisione umana, eliminando il collo di bottiglia causato dalla necessità di avere una preventiva identificazione dei contenuti (labeling), necessaria per l’apprendimento cosiddetto “supervisionato”.
Il significativo aumento della capacità dell’AI di identificare i testi è dovuto in larga parte all’uso di modelli pre-addestrati (pre-trained). Nei sistemi di AI delle generazioni precedenti, il modello destinato a riconoscere determinati tipi di contenuti (ad esempio i post di hate speech) veniva addestrato solo su esempi di testo simili a quelli riscontrabili in un post, alcuni contenenti testi che incitavano all’odio e altri no. Con i modelli pre-addestrati, invece, l’algoritmo viene prima addestrato su un insieme molto vasto di testi, ad esempio l’intera Wikipedia in una certa lingua. In questo modo la rete neurale forma una propria “conoscenza” del linguaggio e dei suoi meccanismi. In una seconda fase questa stessa rete viene addestrata su un tema specifico come nel caso della rete precedente. Questo metodo è la trasposizione al linguaggio naturale di una tecnica usata, con grande successo, per i sistemi dedicati al riconoscimento delle immagini.
A dimostrazione della rapidità con cui si stanno compiendo progressi nella elaborazione del linguaggio naturale, si consideri che il punteggio sul benchmark GLUE[1] è passato da 69 a 88 in 13 mesi, dove 87 è il livello ottenuto in media da un essere umano. I progressi sono stati così rapidi che è stato necessario introdurre un nuovo metodo di verifica: “SuperGLUE”[2].
Il secondo aggiornamento, invece, permette ai sistemi di Facebook di analizzare contenuti che consistono di immagini e testi combinati, come i meme che incitano all’odio. Per migliorare la capacità ancora limitata dell’AI di interpretare tali contenuti misti, Facebook ha anche rilasciato una nuova serie di esempi di meme incitanti all’odio, indicendo un concorso per promuovere il crowdsourcing di algoritmi più efficaci nel rilevarli[3].
Il sistema usato da Facebook per la rilevazione di contenuti misti si chiama “Rosetta”. Rosetta estrae testi dalle immagini e dai fotogrammi video postati su Facebook e Instagram (oltre un miliardo al giorno), per poi passarli a un modello di riconoscimento e classificazione del testo, con l’obiettivo di identificare il contesto grazie all’unione del significato testuale con quello dell’immagine. In questo modo si cerca di distinguere tra, ad esempio, un’immagine di cani con sovraimpressa la scritta “cani” e l’immagine di un particolare gruppo etnico con la stessa scritta in sovraimpressione. Per un osservatore umano è evidente il carattere denigratorio della seconda immagine, non altrettanto per un sistema automatico[4].
Nonostante questi aggiornamenti, tuttavia, l’AI non ha giocato un ruolo altrettanto importante nella gestione dell’ondata di disinformazione sui coronavirus, come ad esempio le teorie cospirazioniste sull’origine del virus e le notizie di cure più o meno miracolose. In questo caso, Facebook si è affidato principalmente ai revisori umani di oltre 60 organizzazioni partner per controllare la veridicità delle informazioni postate. Solo dopo che un contenuto viene segnalato da un revisore in carne e ossa – ad esempio un’immagine con un titolo fuorviante – i sistemi di AI si attivano per cercare tutti gli elementi simili, a cui aggiungono automaticamente etichette di avvertimento o li eliminano direttamente.
Sempre Facebook fornisce dei dati quantitativi: le organizzazioni partner hanno identificato 7.500 articoli falsi o fuorvianti, e questa analisi è stata utilizzata per segnalare oltre 50 milioni di post. Facebook dichiara che tali etichette di avvertimento provocano una significativa diminuzione della percentuale di utenti che vi clicca[5].
A oggi non esiste un modello di apprendimento automatico capace di trovare da solo nuovi casi di disinformazione e il modello appena descritto ricorda quello utilizzato dai sistemi antivirus. In questi sistemi degli esperti umani riconoscono che uno specifico contenuto costituisce una minaccia, magari a seguito di un’analisi effettuata su una macchina infetta. Una volta identificato il virus viene elaborata la sua “impronta digitale” (virus signature) e immediatamente diffusa a tutti i sistemi antivirus installati nel mondo. Questi ultimi, a ogni ricezione di un nuovo file, utilizzano un algoritmo per estrarre l’impronta digitale del file ricevuto e la confrontano con il database delle impronte (signature) dei file malevoli. Nel caso in cui il file sotto esame corrisponda a uno di questi, l’antivirus lo blocca e notifica l’utente.
Benché non in grado di rilevare automaticamente nuovi contenuti falsi o fuorvianti, l’Intelligenza Artificiale ha comunque un ruolo importante. Grazie all’AI è possibile rilevare contenuti simili a quelli già identificati, permettendo di rispondere più velocemente – e su una scala impensabile se affidata solo a revisori umani – alla diffusione di questo tipo di contenuti.
Come l’AI aiuta la diffusione delle fake news
Se l’intelligenza artificiale ha un ruolo importante nel limitare la diffusione di notizie false sui social media, permettendo di valutare volumi enormi di post e di identificare rapidamente quei post che tentano di passare i filtri inserendo piccole modifiche in contenuti già identificati come falsi, è anche vero il contrario: strumenti e tecniche di AI costituiscono un’arma potente nelle mani di chi, invece, ha interesse alla diffusione su larga scala di notizie false.
Campagne di disinformazione di questo tipo richiedono la creazione di un gran numero di account, l’utilizzo di software in grado di “rispondere” e “rilanciare” contenuti, magari con delle variazioni che permettano di nascondere meglio la natura automatica dell’account (“bot”) e contribuire a ingannare i filtri anti-fake news discussi nella sezione precedente.
Una campagna di disinformazione su larga scala ha bisogno di centinaia o migliaia di account automatici che possano essere usati come “megafono” per la diffusione di certe “linee narrative”. In una recente ricerca dell’università Carnegie Mellon di Pittsburgh, i ricercatori hanno esaminato da gennaio in poi più di 200 milioni di tweet che avevano come oggetto il Covid-19, e hanno scoperto che circa il 45% sono stati inviati da account che si comportavano più come bot che come umani. Questa percentuale saliva addirittura all’82% far i primi 100 retweeting account![6]
La semplice creazione di un numero così elevato di account falsi richiederebbe, già da sola, uno sforzo enorme per degli operatori umani. Per questo vengono impiegati sistemi per analizzare il modulo di creazione dell’account e, magari, usare le API del social network per creare automaticamente nuovi account falsi, riempiendo automaticamente i moduli di iscrizione. Inoltre, i sistemi di creazione di volti sintetici sono utilizzati per fornire a ogni account un volto univoco e sfuggire quindi alle analisi che mirano a identificare account falsi o identità duplicata grazie al riconoscimento delle immagini.
Anche in questo caso i social network più esposti, ad esempio Facebook, lavorano incessantemente per migliorare i sistemi di rilevamento degli account falsi, sfruttando la capacità dell’IA di correlare innumerevoli caratteristiche dell’account (fino a 20.000 elementi), non solo la foto del profilo. Per dare un’idea dei volumi in gioco, Facebook ha dichiarato che negli ultimi due anni, grazie ai propri sistemi, ha potuto identificare 900 milioni (900.000.000) di account falsi, riducendo la percentuale di account falsi dal 27% di due anni fa al 3,8% di oggi[7].
Una volta superato lo scoglio della creazione dell’account falso, è necessario che questi profili siano in grado di riprodurre il comportamento umano, per sfuggire alle maglie dei tool automatici di rilevamento dei falsi account, mantenendo la capacità di fungere da strumento per la diffusione della propaganda. Qui possiamo individuare alcuni elementi in cui il ruolo dell’intelligenza artificiale è molto importante: la creazione dei contenuti, il successivo rilancio degli stessi e la traduzione in più lingue, tutti elementi nei quali i progressi raggiunti dall’intelligenza artificiale rendono queste attività semplici e scalabili.
Per avere un esempio concreto delle potenzialità e pericolosità di questi sistemi, il modo migliore è visitar il blog “This Marketing Blog Does Not Exist”. Il blog è intestato a una persona che non esiste; la foto del profilo è stata creata con il tool StyleGAN, una rete neurale di tipo Generative Adversarial Network (GAN) rilasciata da Nvidia nel 2018, in grado di creare volti sintetici estremamente realistici.

Esempio di volto generato da StyleGAN (fonte: Wikipedia)
Non solo il creatore del blog è artificiale, ma lo sono anche i testi realizzati con il modello Grover, mentre i titoli non sono altro che il “seme” utilizzato da Grover per generare il testo artificiale. In pratica gli strumenti per dare vita ad account artificiali sono tutti esistenti e di pubblico dominio. A questo ventaglio di opportunità va aggiunta la capacità di generare deepfake, ovvero dei video, manipolati grazie all’intelligenza artificiale, che possono cambiare i volti delle persone sullo schermo con quelli di altri – politici, scienziati, attori – creando situazioni in cui il soggetto-bersaglio dice e fa cose in realtà mai accadute.
Infine, nella creazione di campagne di opinione su vasta scala, non può mancare il ricorso a sistemi in grado di tradurre velocemente i testi da una lingua all’altra. Qui la tecnologia è veramente avanzata e estremamente diffusa: non solo Google Translate, ma anche DeepL o le funzionalità native dei software Microsoft Office 365 permettono di realizzare in pochi secondi una traduzione abbastanza credibile.
Se negli ultimi anni uno dei temi più discussi è stato quello della cybersecurity delle infrastrutture critiche (generazione e distribuzione di energia, trasporti, sanità telecomunicazioni ecc.), tanto da convincere l’Unione Europea della necessità di una normativa di protezione apposita[8], il rapido sviluppo delle tecnologie di intelligenza artificiale sta delineando uno scenario in cui l’attacco alle infrastrutture di un paese non passa solo per l’utilizzo di tecniche di hacking contro i relativi sistemi informatici, ma anche per l’esecuzione coordinata di attività di manipolazione dell’opinione pubblica, tale da rendere politicamente impraticabile determinate scelte.
Chi pensa che questo sia uno scenario del tutto fantascientifico, deve considerare che tra le diverse “narrative” sul Covid-19 propagate dagli account falsi, una in particolare riguardava il legame fra reti 5G e la diffusione del virus. In Inghilterra dozzine di antenne 5G sono state incendiate, i tecnici delle società telefoniche in alcuni casi aggrediti e le autorità ritengono che questi atti siano stati propiziati proprio dalla diffusione di questo tipo di false notizie[9], la cui diffusione è stata amplificata da account falsi che agivano come bot.
Il ruolo dei social media nel contrasto alla diffusione delle fake news
Come discusso in un altro articolo relativo al ruolo dell’AI nella cybersecurity[10], anche nel settore della propagazione di false informazioni assistiamo alle dinamiche che contraddistinguono una “corsa agli armamenti” sul terreno dei social network: da una parte l’utilizzo di tecniche di AI per sfruttare le potenzialità (dis-)informative dei social network, dall’altra una risposta, ancora basata sull’AI, per potenziare le capacità di rilevare e bloccare questi tentativi. Abbiamo visto che questa seconda parte è al momento del tutto demandata a chi gestisce i social network, che ha le capacità tecniche, il personale, l’interesse (anche economico), l’accesso alle competenze e alle capacità tecnologiche per realizzare l’attività di contrasto.
In questo modo, in sostanza, si sta tacitamente accettando – e spesso addirittura auspicando – che i gestori dei social network assumano con sempre maggiore decisione il ruolo e di censore dei contenuti veicolati attraverso le loro piattaforme, e tutto in nome della “difesa della democrazia” messa in pericolo dalle fake news.
A parere di chi scrive questo “dovere” censorio nei confronti dei contenuti pubblicati dagli utenti rischia di divenire anche l’assegnazione di un diritto, il diritto dei social network di decidere “chi” e “cosa” può avere cittadinanza sulle proprie piattaforme. Il tema, secondario fino a qualche anno fa, quando gli utenti che usavano tali piattaforme erano pochi rispetto alla popolazione, dovrebbe invece essere considerato centrale ora che queste stesse piattaforme sono utilizzate da una fetta rilevante dell’intera popolazione mondiale per ricevere e scambiare informazioni.
Alcuni casi, presi dalla cronaca recente, mostrano le implicazioni non sempre tranquillizzanti di questo dovere/diritto. A settembre 2019 Facebook decide di bandire la pagina di CasaPound dalla propria piattaforma per violazioni delle policy (di Facebook) sulla diffusione di messaggi di incitamento all’odio. Il ricorso di CasaPound contro tale decisione è stato successivamente accolto dal Tribunale Civile di Roma il 12 dicembre 2019[11].
Il 16 aprile 2020 un giornalista di Radio Radicale che segue l’attualità e la politica della Turchia ha avuto il proprio account personale revocato, apparentemente in seguito a un suo post sulla liberazione di un membro della criminalità turca avvenuta il 15 aprile.
Infine, il 26 maggio scorso Twitter ha marcato un tweet del presidente degli Stati Uniti sulla possibilità di brogli a causa dell’utilizzo del voto postale, con un’etichetta che lo identificava come informazione non corretta, rinviando il lettore verso altri siti di informazione per “verificare i fatti”.
Non è mia intenzione entrare nel merito della validità o meno di tali decisioni, piuttosto sottolineare come, al crescere della rilevanza comunicativa delle piattaforme social, diventa fondamentale chiedersi chi decide e su quali parametri. Non bisogna infatti dimenticare che il modello di business dei social media è quello di rendere il più facile possibile per chiunque pubblicare sulle loro piattaforme, un modello talmente vincente che una parte molto consistente del budget dei media pubblicitari tradizionali si è ora spostato sui social media.
Inevitabilmente i social network si trovano ad affrontare lo stesso tipo di pressione da parte degli inserzionisti (e dei governi) che anche i media tradizionali hanno sempre subito, ma per loro l’incentivo a capitolare è più forte. La ragione è semplice: non hanno alcun investimento nei contenuti e nessuna responsabilità editoriale o commerciale verso i propri utenti, a differenza di un giornale tradizionale. Per questo motivo possono rivelarsi molto più pronti a rimuovere i contenuti e persino a bandire gli utenti se questa decisione è “buona per il business”.
A questo si aggiunga che i social media sono a tutti gli effetti un oligopolio molto stretto: Facebook, che possiede Whatsapp e Instagram, Google, che possiede YouTube, Twitter, per quanto riguarda i social più diffusi in occidente. Questi tre complessivamente sono usati da 8,8 miliardi di utenti[12] (il numero è superiore alla popolazione mondiale perché molti utenti usano più di una piattaforma). Poche aziende, tutte americane, a gestione estremamente verticistica e concentrate in California, che decidono in grande autonomia i criteri di “cittadinanza” sulle loro piattaforme, delegando l’effettiva applicazione dei criteri di policing delle informazioni ad algoritmi che, come sappiamo sono tutt’altro che esenti da bias e polarizzazioni. Si potrebbe dire che mai come ora il potere di controllo delle notizie è stato concentrato in così poche mani.
E si tratta di un potere occulto ma molto reale: nel 2012 Facebook ha autonomamente deciso di eseguire un esperimento sui propri utenti, mostrando a un campione composto da 1,9 milioni di persone un banner che li esortava ad andare a votare e a condividere con i propri amici questo fatto. Secondo i dati diffusi dallo stesso Facebook, l’esperimento causò una crescita della percentuale di votanti del 3%.
Nell’incitare i social media a “fare pulizia” rispetto ai varie classi di contenuti senza nessun tipo di supervisione pubblica, accettando di delegare questo delicatissimo compito a un apparato dirigenziale opaco, che utilizza algoritmi addirittura coperti da segreto industriale e che obbedisce a logiche di massimizzazione del profitto, potrebbe esporre le democrazie a rischi che, nel lungo periodo, rischiano di essere paragonabili a quelli oggi associati alla diffusione di notizie false.
Insomma, l’operazione – di pulizia – è riuscita ma il paziente – la democrazia – è morto.
- GLUE: General Language Understanding Evaluation. https://gluebenchmark.com/ ↑
- Anadiotis, G.: “The state of AI in 2019: Breakthroughs in machine learning, natural language processing, games, and knowledge graphs”, ZDnet, Luglio 2019 ↑
- Facebook Artificial Intelligence Blog, 12 maggio 2020. https://ai.facebook.com/blog/hateful-memes-challenge-and-data-set ↑
- Sivakumar V., Gordo A., Paluri M. “Rosetta: Understanding text in images and videos with machine learning”, Facebook Engineering Blog, Settembre 2018 ↑
- Perry T. K., “How Facebook Is Using AI to Fight COVID-19 Misinformation”, IEEE Spectrum, 12 maggio 2020 ↑
- Young, V. A., “Accounts Discussing ‘Reopening America’ May Be Bots” School of Computer Science, Carnegie Mellon University, 20 maggio 2020 ↑
- Deutscher, M., “Facebook details AI system that helped it catch 900M fake accounts last year”, SiliconANGLE, 4 marzo 2020 ↑
- Direttiva (UE) 2016/1148, cd. Direttiva NIS, recepita in Italia Con il Decreto Legislativo 18 maggio 2018, n.65 ↑
- Gallagher, R., “5G Virus Conspiracy Theory Fueled by Coordinated Effort”, Bloomberg news, 9 aprile 2020 ↑
- Benedetti, D., “Intelligenza artificiale per la sicurezza informatica: gli ambiti di utilizzo e i vantaggi”, Agenda Digitale, 14 febbraio 2019 ↑
- Rijtan, R., “Facebook contro la riapertura della pagina Casapound: ‘Non vogliamo che utilizzino i nostri servizi’”, la Repubblica, 27 dicembre 2019 ↑
- Fonte: Statista. https://www.statista.com/statistics/272014/global-social-networks-ranked-by-number-of-users/ ↑


