
Meta Platforms ha presentato Voicebox, un modello di apprendimento automatico in grado di generare il parlato a partire dal testo. Ciò che distingue Voicebox da altri modelli di sintesi vocale è la sua capacità di eseguire molti compiti per i quali non è stato addestrato, tra cui l’editing, la rimozione del rumore e il trasferimento dello stile.
Il modello è stato addestrato con un metodo speciale sviluppato dai ricercatori di Meta. Sebbene Meta non abbia rilasciato Voicebox a causa di preoccupazioni etiche circa l’uso improprio, i risultati iniziali sono promettenti e possono essere utili per molte applicazioni future. Qui è possibile scaricare il paper.
Video: Voicebox di Meta
Indice degli argomenti:
Voicebox sintetizza il parlato in sei lingue
Voicebox è un modello generativo in grado di sintetizzare il parlato in sei lingue, tra cui inglese, francese, spagnolo, tedesco, polacco e portoghese. Come i grandi modelli linguistici, è stato addestrato su un compito molto generale che può essere utilizzato per molte applicazioni. Ma mentre gli LLM cercano di apprendere le regolarità statistiche delle parole e delle sequenze di testo, Voicebox è stato addestrato per apprendere i modelli che mappano i campioni audio vocali alle loro trascrizioni.
Tale modello può essere applicato a molti compiti a valle, con una messa a punto minima o nulla. “L’obiettivo è costruire un unico modello in grado di eseguire molti compiti di generazione vocale guidata dal testo attraverso l’apprendimento nel contesto”, scrivono i ricercatori di Meta nel documento (PDF) che descrive i dettagli tecnici di Voicebox.
Il modello è stato addestrato con la tecnica Meta “Flow Matching“, più efficiente e generalizzabile rispetto ai metodi di apprendimento basati sulla diffusione utilizzati in altri modelli generativi. Questa tecnica consente a Voicebox di “imparare da dati vocali diversi senza che tali variazioni debbano essere accuratamente etichettate”. Senza bisogno di etichettatura manuale, i ricercatori sono riusciti ad addestrare Voicebox su 50mila ore di parlato e trascrizioni di audiolibri.
Il modello utilizza come obiettivo di addestramento il “text-guided speech infilling”, ossia deve prevedere un segmento di parlato in base all’audio circostante e alla trascrizione completa del testo. In pratica, significa che durante l’addestramento al modello viene fornito un campione audio e il testo corrispondente. Alcune parti dell’audio vengono quindi mascherate e il modello cerca di generare la parte mascherata utilizzando l’audio circostante e la trascrizione come contesto. Facendo questo più volte, il modello impara a generare un discorso dal suono naturale a partire dal testo in modo generalizzabile.
Fonte: Meta
Le varie funzionalità di Meta Voicebox
A differenza dei modelli generativi che vengono addestrati per un’applicazione specifica, Voicebox è in grado di eseguire molti compiti per i quali non è stato addestrato. Ad esempio, il modello può utilizzare un campione vocale di 2 secondi per generare il parlato di un nuovo testo. Meta sostiene che questa capacità può essere utilizzata per far parlare le persone che non sono in grado di parlare o per personalizzare le voci dei personaggi non giocabili dei giochi e degli assistenti virtuali.
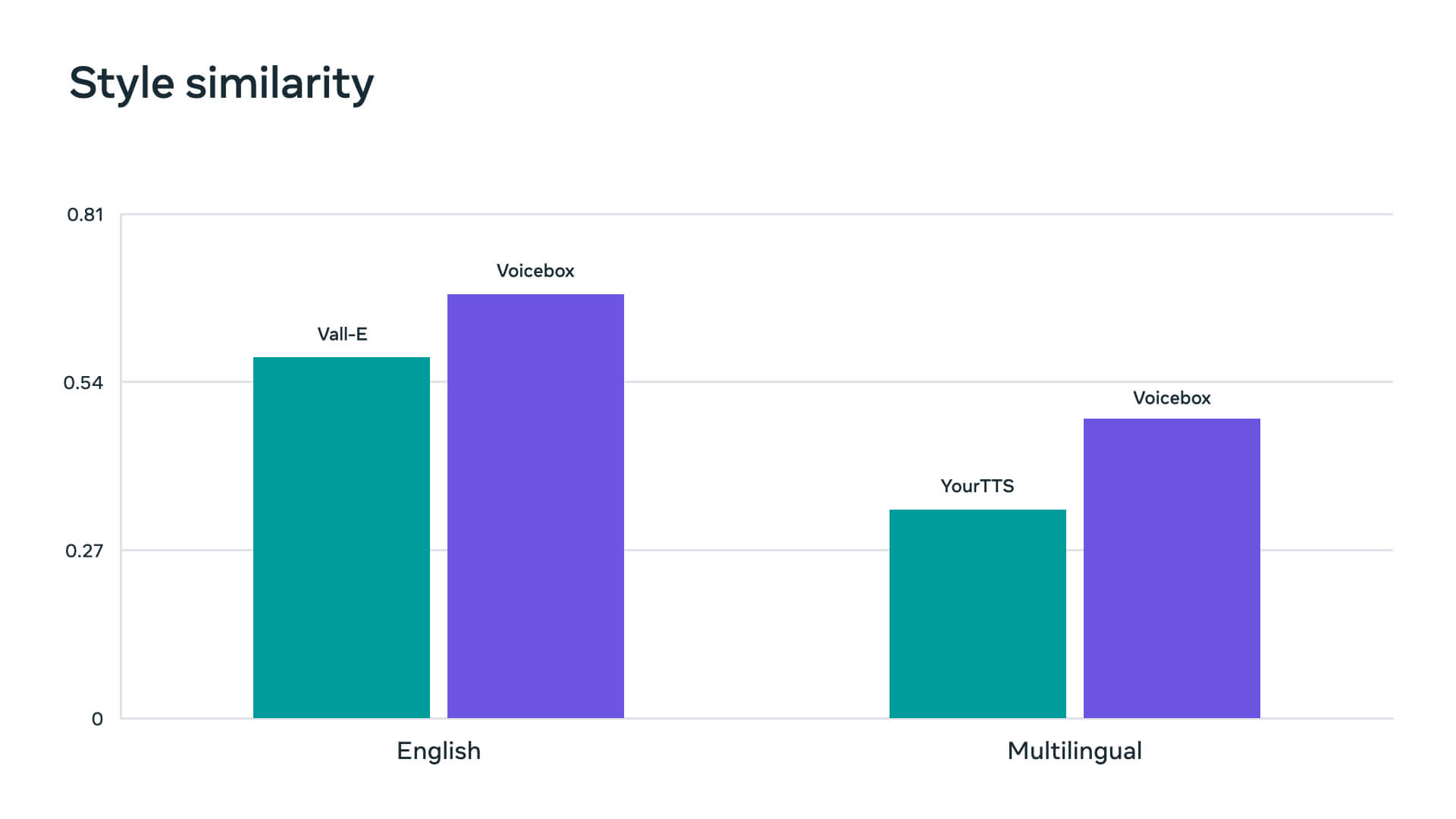
Voicebox esegue il trasferimento di stile in diversi modi. Ad esempio, è possibile fornire al modello due campioni audio e di testo. Il modello utilizzerà il primo campione audio come riferimento stilistico e modificherà il secondo per adattarlo alla voce e al tono del riferimento. È interessante notare che il modello può fare la stessa cosa in diverse lingue, il che potrebbe essere utilizzato per “aiutare le persone a comunicare in modo naturale e autentico, anche se non parlano la stessa lingua”.
Editing
Il modello è anche in grado di eseguire una serie di operazioni di editing. Ad esempio, se un cane abbaia in sottofondo durante la registrazione della voce, è possibile fornire l’audio e la trascrizione a Voicebox e mascherare il segmento con il rumore di fondo. Il modello utilizzerà la trascrizione per generare la parte mancante dell’audio senza il rumore di fondo.
Modificare il parlato
La stessa tecnica può essere utilizzata per modificare il parlato. Ad esempio, se si è pronunciata una parola in modo errato, è possibile mascherare quella parte del campione audio e passarla a Voicebox insieme a una trascrizione del testo modificato. Il modello genererà la parte mancante con il nuovo testo in modo che corrisponda alla voce e al tono circostante.
Campionamento vocale
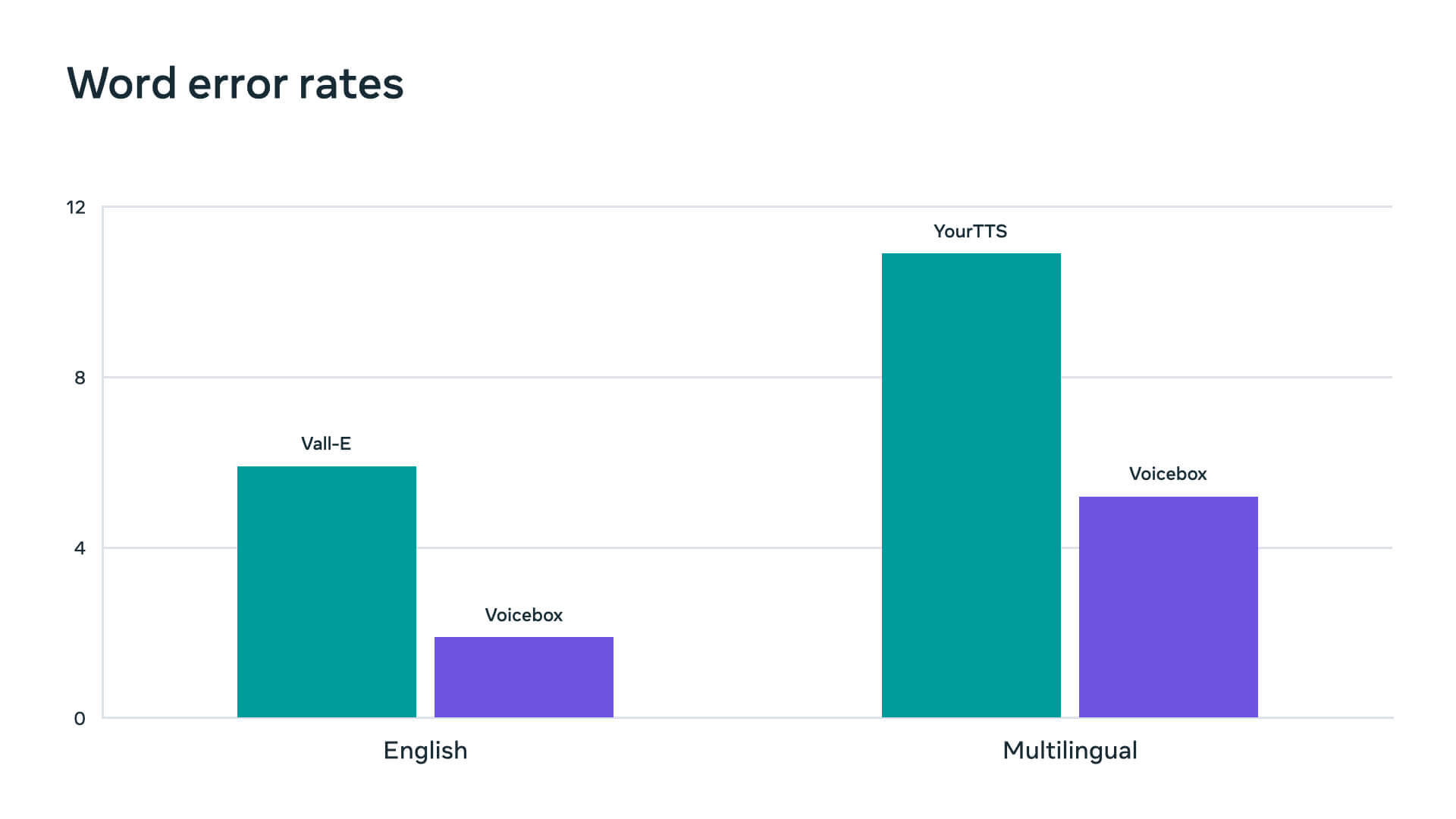
Una delle applicazioni interessanti di Voicebox è il campionamento vocale. Il modello può generare diversi campioni vocali da una singola sequenza di testo. Questa capacità può essere utilizzata per generare dati sintetici per addestrare altri modelli di elaborazione vocale. “I nostri risultati dimostrano che i modelli di riconoscimento vocale addestrati sul parlato sintetico generato da Voicebox hanno prestazioni quasi uguali a quelle dei modelli addestrati sul parlato reale, con un degrado del tasso di errore dell’1% rispetto a un degrado compreso tra il 45 e il 70% con il parlato sintetico dei precedenti modelli text-to-speech”, scrive Meta.
I limiti
Anche Voicebox ha dei limiti. Essendo stato addestrato sui dati di un audiolibro, non si trasferisce bene a un discorso colloquiale che è casuale e contiene suoni non verbali. Inoltre, non fornisce un controllo completo sui diversi attributi del parlato generato, come lo stile vocale, il tono, l’emozione e la condizione acustica. Il team di ricerca di Meta sta esplorando tecniche per superare questi limiti in futuro.
Fonte: Meta
Perché Meta non ha rilasciato il modello di Voicebox
Cresce la preoccupazione per le minacce dei contenuti generati dall’intelligenza artificiale. Ad esempio, di recente dei criminali informatici hanno tentato di truffare una donna chiamandola e utilizzando una voce generata dall’intelligenza artificiale per impersonare suo nipote. Sistemi avanzati di sintesi vocale come Voicebox potrebbero essere utilizzati per scopi simili o per altre azioni nefaste, come la creazione di prove false o la manipolazione di audio reali.
“Come per altre potenti innovazioni nel campo dell’intelligenza artificiale, riconosciamo che questa tecnologia comporta il potenziale di un uso improprio e di danni non intenzionali”, ha scritto Meta sul suo blog dedicato all’intelligenza artificiale. A causa di queste preoccupazioni, Meta non ha reso pubblico il modello, ma ha fornito dettagli tecnici sull’architettura e sul processo di addestramento nel documento tecnico. Il documento contiene anche dettagli su un modello di classificatore in grado di rilevare il parlato e l’audio generato da Voicebox per mitigare i rischi dell’uso del modello.


