
- VoiceDesign di ElevenLabs è progettato per essere facile da usare. Per un uso professionale, sono disponibili piani in abbonamento a partire da 5 dollari al mese.
- ElevenLabs offre due strumenti principali per generare file audio: Speech Synthesis e VoiceLab. Speech Synthesis permette di configurare parametri come preset vocale, stabilità della voce, chiarezza espressiva e lingua del modello.
- Le voci sintetizzate da AI trovano applicazione in marketing, creazione di contenuti audio (podcast e audiolibri) e servizio clienti.
VoiceDesign di ElevenLabs è stato concepito per garantire la massima semplicità di utilizzo. Il primo step consiste nella creazione di un account. Grazie al piano gratuito, è possibile generare voci sintetizzate che leggono fino a 10mila caratteri al mese in varie lingue, tra cui inglese, tedesco, spagnolo, italiano, francese, portoghese e hindi. Tali registrazioni possono essere utilizzate per scopi non commerciali, attribuendole ad ElevenLabs. Per un utilizzo più professionale dello strumento, sono disponibili diversi piani in abbonamento tra cui scegliere, a partire da 5 dollari al mese.
Indice degli argomenti:
Ascolta una sintesi dell’articolo (tecnologia ElevenLabs)
Speech Synthesis
Per generare i file audio sono disponibili due strumenti. Il più semplice da utilizzare si chiama Speech Synthesis. Dal pannello di configurazione del servizio è possibile selezionare i seguenti parametri chiave:
- preset vocale
- livello di stabilità della voce
- livello di chiarezza espressiva
- lingua del modello.
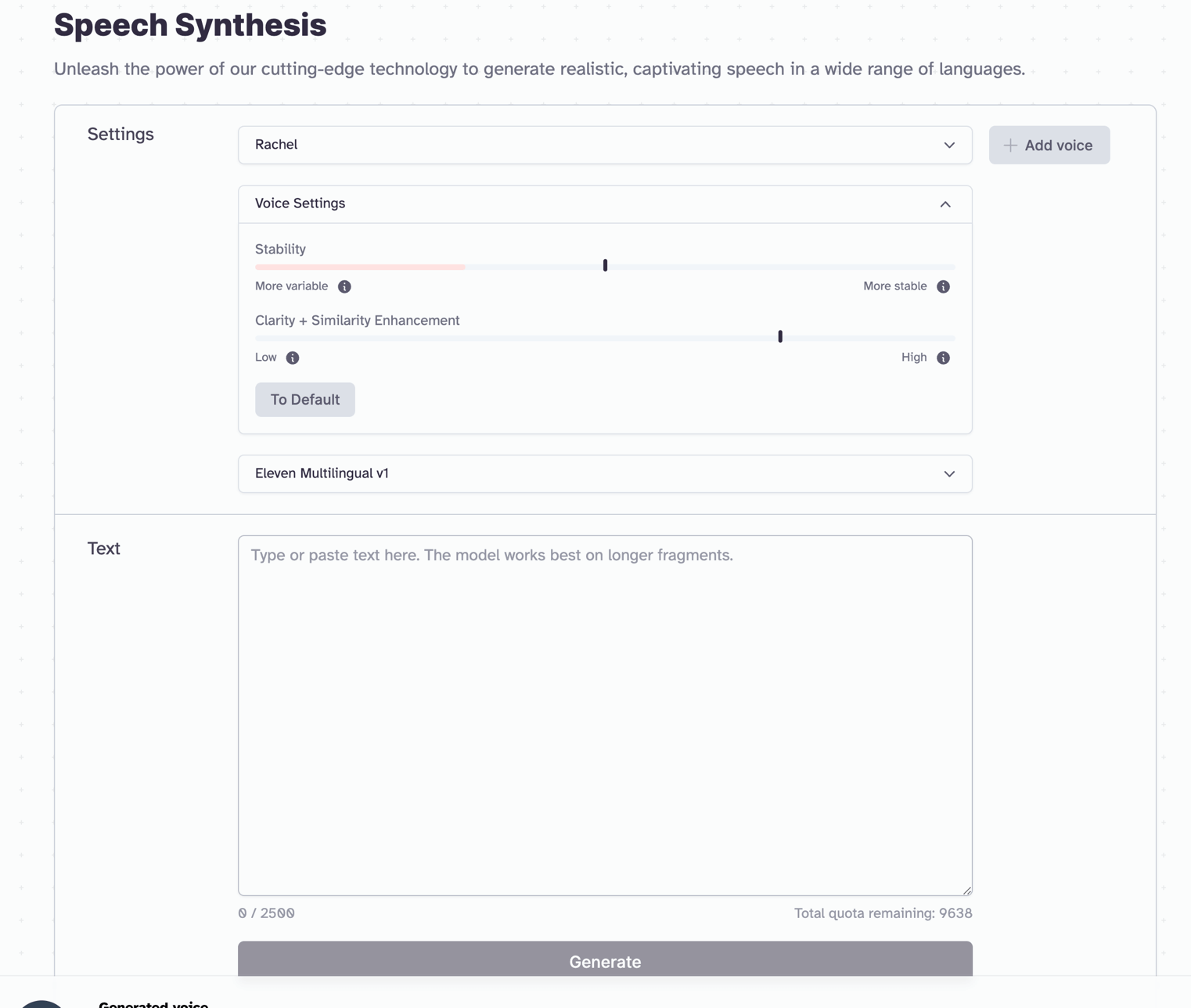
Dopo aver selezionato i parametri, si può inserire un testo, che deve essere compreso tra i 100 e i 2500 caratteri, e dare alla rete neurale il tempo necessario per generare il file audio pronto all’uso.
VoiceLab
La seconda modalità generativa è denominata VoiceLab, che offre una flessibilità superiore nella configurazione. Il primo passo per utilizzare VoiceLab consiste nella creazione di una voce, che può essere generata seguendo determinati parametri oppure clonata da un campione audio. I principali parametri per configurare la voce includono:
- Genere
- Età
- Accento
- Intensità dell’accento
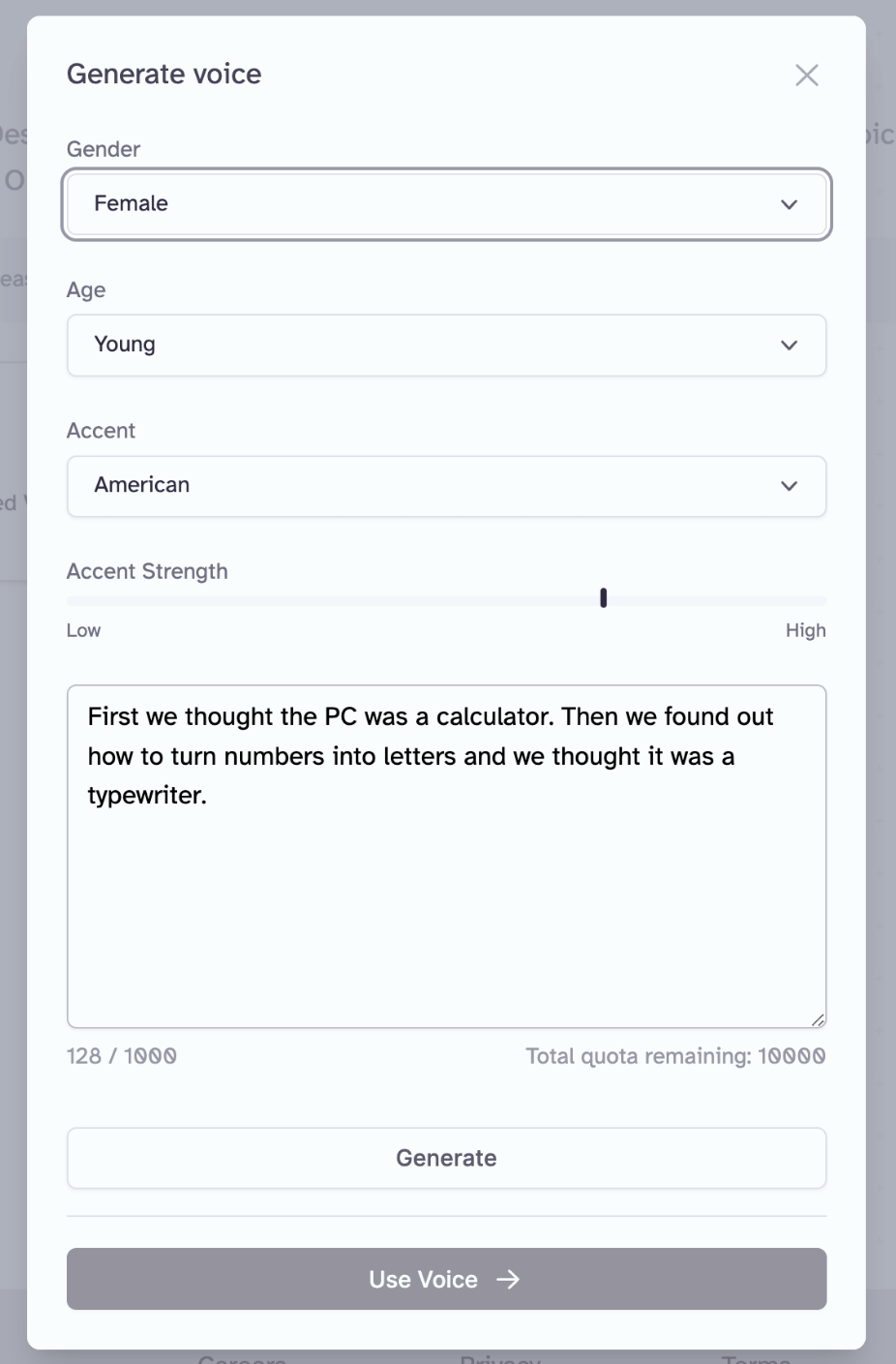
È possibile creare una nuova voce e condividerla con la comunità di ElevenLabs. Ovviamente, esiste anche la possibilità di esplorare le voci condivise dagli altri utenti, così da avere sempre accesso alla “voce giusta” senza necessità di fare molti tentativi per trovare i parametri ideali.

Video VoiceLab tutorial
Applicazioni pratiche delle voci AI-Powered
I costi per generare voci tramite l’intelligenza artificiale stanno diventando sempre più accessibili, con tempi di produzione che si riducono costantemente. Numerosi fornitori, come ElevenLabs, offrono l’accesso a delle API per integrare queste voci nei processi aziendali, richiedendo un impegno minimo.
Uno dei primi settori applicativi per le voci sintetizzate da AI è il marketing, dove sono utilizzate per creare messaggi pubblicitari personalizzati da veicolare attraverso vari canali di comunicazione. Ciò accresce l’efficacia con cui le aziende raggiungono il loro pubblico, riducendo allo stesso tempo i costi pubblicitari.
La sintesi vocale ha anche trovato applicazione nello sviluppo di contenuti audio. Le aziende possono sfruttare questa tecnologia per generare contenuti multimediali, come podcast e audiolibri. Questo sistema consente di ottenere materiale più rapidamente e a costi minori rispetto alla registrazione vocale tradizionale.
Le voci sintetizzate dall’AI vengono anche utilizzate nel campo del servizio clienti. Le aziende si affidano sempre più a chatbot e assistenti virtuali per rispondere tempestiva e accuratamente alle domande più frequenti dei clienti. Ciò consente di risparmiare del tempo al cliente in attesa di risposta e ridurre le attività di monitoraggio da parte dei dipendenti, diminuendo notevolmente i costi operativi. L’efficacia di questo sistema si riflette nell’incremento della soddisfazione del cliente e nell’efficientamento complessivo del supporto clienti.
Come funzionano le AI per la generazione di voci
Le intelligenze artificiali (AI) che generano voci umane si fondano su una tecnologia molto similare, in termini concettuali, ai vocoder dei primi periodi. Il sistema viene addestrato a produrre un audio partendo da un input testuale. Queste AI fanno uso di reti neurali profonde, addestrate mediante migliaia di ore di registrazioni audio trascritte. Durante questo processo, l’AI analizza e apprende vari aspetti del linguaggio umano, come la pronuncia delle parole e la fraseologia, l’intonazione, l’accento, e altre qualità sonore. Il risultato è dunque una registrazione estremamente realistica.
Successivamente alla fase di addestramento, il sistema è capace di convertire il testo in fonemi (ovvero i suoni base che costituiscono le parole in una lingua), quindi in parole, e infine in frasi. L’AI prende in considerazione anche il contesto della frase, e può modificare l’intonazione o l’enfasi in base al significato previsto. Il prodotto finale è una voce simulata che risulta naturalmente umana e può essere impiegata in una vasta gamma di applicazioni, inclusi assistenti virtuali, servizi di trascrizione, audiolibri, e tanto altro.
La parametrizzazione del modello riveste un ruolo cruciale in questa specifica applicazione dell’AI. Con i parametri corretti, è infatti possibile modulare la voce risultante in modo tale da personalizzarla. Ogni impostazione conferisce dunque un carattere distintivo e unico, creando una vera e propria personalità. Questa capacità di personalizzare il risultato moltiplica gli scenari operativi in cui questa tecnologia può essere utilizzata.
Breve storia della generazione della voce con il computer
Il primo computer in grado di parlare risale a un esperimento del 1961, realizzato dai fisici dei Bell Labs J.L. Kelly e L. Gertsman. Utilizzando una macchina IBM 704, riuscirono a creare il primo sintetizzatore vocale elettronico. Questo vocoder non solo era in grado di riprodurre una voce umana, ma riusciva anche a cantare una canzone. In effetti, è stato proprio questo sintetizzatore a ispirare la voce di HAL 9000, l’intelligenza artificiale nel famoso film “2001: Odissea nello spazio”. Da allora, le voci sintetiche hanno rivoluzionato l’accessibilità dei computer e hanno fornito un’alternativa all’interfaccia tradizionale per la fruizione di contenuti. Oggi, le voci sintetizzate sono ampiamente utilizzate e supportano molte persone nelle loro attività quotidiane.
Nonostante i progressi dei sintetizzatori vocali tradizionali, l’ascolto di un testo più lungo di qualche frase risulta ancora complesso e talvolta irritante. L’assenza di espressività e la monotonia del tono rendono difficile per l’ascoltatore cogliere l’intonazione emotiva e il significato del messaggio. La mancanza di dinamismo e di espressività nel timbro delle voci sintetizzate può facilmente indurre stanchezza e disinteresse nell’ascoltatore, compromettendo l’esperienza d’ascolto e riducendo l’efficacia della comunicazione.
Conclusioni
Come per tutte le innovazioni, gli strumenti tecnologici avanzati possono essere utilizzati anche per scopi criminali. Si registra un aumento di notizie relative a truffe eseguite tramite registrazioni vocali generate da intelligenza artificiale; pertanto, è fondamentale prestare la massima attenzione nel rapportarsi virtualmente con gli altri. Questi strumenti facilitano la volontà di impersonare altri individui, rendendo quindi la consapevolezza degli utenti un fattore cruciale per la loro sicurezza.
La generazione di una voce sintetica tramite l’intelligenza artificiale è un’operazione che, essendo semplice, può trovare applicazione pratica in numerosi settori. Strumenti come VoiceDesign di ElevenLabs consentono di sperimentare personalmente questa tecnologia in modo del tutto gratuito. Man mano che si acquisisce familiarità con questo strumento, si scoprono sempre nuovi modi per applicare le potenzialità dell’intelligenza artificiale alla risoluzione di problemi concreti.


