- Il clustering è un insieme di algoritmi non supervisionati utilizzati per raggruppare elementi con similarità tra loro in classi omogenee.
- Gli algoritmi di clustering possono essere suddivisi in tre macro-categorie: quelli che individuano un centro di similarità (es. k-means), quelli gerarchici (es. hierarchical clustering) e quelli basati sulla densità (es. DBSCAN).
- Gli algoritmi di clustering trovano larga applicazione aziendale per esplorare e analizzare dati non classificati, permettendo di scoprire somiglianze e connessioni utili in vari contesti come rilevazione di frodi, segmentazione della clientela per marketing, e ottimizzazione delle offerte di prodotti. Possono emergere correlazioni inaspettate, difficilmente individuabili manualmente.
Il clustering è un insieme di algoritmi che consente di raggruppare elementi in classi omogenee; un cluster è costituito da un insieme di elementi che hanno una o più similarità tra loro.
Gli algoritmi di clustering fanno parte dei metodi di apprendimento non supervisionato, un sottoinsieme degli algoritmi di machine learning che è parte del dominio dell’intelligenza artificiale. In questo senso il clustering è uno degli algoritmi di AI che consente di fare analisi sui dati ed estrarre conoscenza; si tratta di metodi statistici, con un buon livello di spiegabilità (Explainability) e con diverse applicazioni in ambito aziendale. Possiamo dire che gli algoritmi di clustering hanno lo scopo di raggruppare oggetti, dati, informazioni, persone il più simili tra loro.
Indice degli argomenti:
Cosa si intende con AI per il clustering dei dati
L’obiettivo del clustering è quello di individuare un raggruppamento naturale presente nei dati.
La natura degli algoritmi di clustering è di essere esplorativi, applicati a dati non etichettati o classificati precedentemente. Il pregio degli algoritmi di clustering è di poter lavorare su dati di cui non si conosce nulla a priori.
I principali algoritmi di clustering
Gli algoritmi di clustering di base possono essere divisi in tre macro-tipologie all’interno delle quali si possono trovare varianti e alternative in base alla specifica necessità applicativa:
- Quelli che individuano un centro di similarità; fanno parte di questa categoria k-means, fuzzy C-means, e loro varianti. K-Means è efficace dal punto di vista computazionale; è molto efficace nel trovare cluster di forma sferica. Il suo punto debole è che bisogna decidere a priori il numero di cluster in cui segmentare i dati; pertanto, è necessario valutare a posteriori su più prove quale sia il numero k di cluster ottimale.
- Quelli che con approccio agglomerativo (si parte dal singolo campione e si aggiungono gli altri sulla base della similarità fino ad arrivare a un cluster unico) o divisivo (si parte da un unico cluster con tutti i campioni e si suddivide in cluster più piccoli fino al singolo campione) identificano raggruppamenti gerarchici; appartiene a questa categoria il “hierarchical clustering”. Un vantaggio degli algoritmi a clustering gerarchico è il fatto che consentono di tracciare dei dendrogrammi che possono aiutare nell’interpretazione dei risultati, creando regole e relazioni significative. Un altro vantaggio di questo approccio gerarchico è il fatto che non abbiamo bisogno di specificare fin da subito il numero di cluster. Dal dendogramma è possibile ottenere la migliore divisione in cluster (visibili tracciati in rosso nell’immagine).
- Quelli che identificano modelli con un approccio basato sulla densità; DBSCAN (Density Based Spatial Clustering of Applications with Noise): è un algoritmo che assegna l’appartenenza a un cluster in base alla densità di regioni di punti; per densità si intende il numero di punti entro un determinato raggio. I vantaggi del DBSCAN sono che non è necessario specificare a priori il numero di cluster, che può individuare cluster di ogni forma (anche uno contenuto nell’altro), che non è necessario che tutti i campioni siano censiti in un cluster, sono ammessi dati isolati.
Nelle immagini seguenti un esempio di rappresentazione di cluster ottenuti con l’algoritmo k-means e con il clustering gerarchico. In quest’ultimo sono evidenziati in rosso i cluster individuati come migliore raggruppamento dei dati e questa informazione viene fornita automaticamente dall’algoritmo.
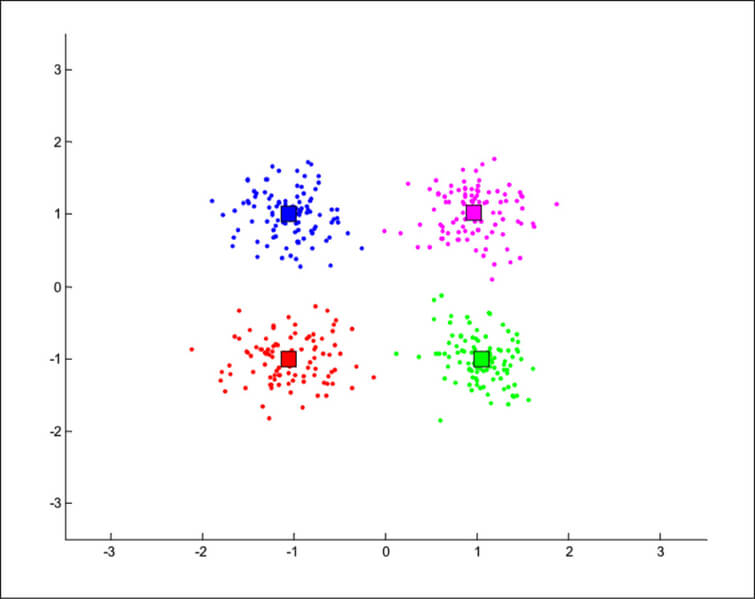
Da “Python Machine Learning” – di Sebastian Raschka
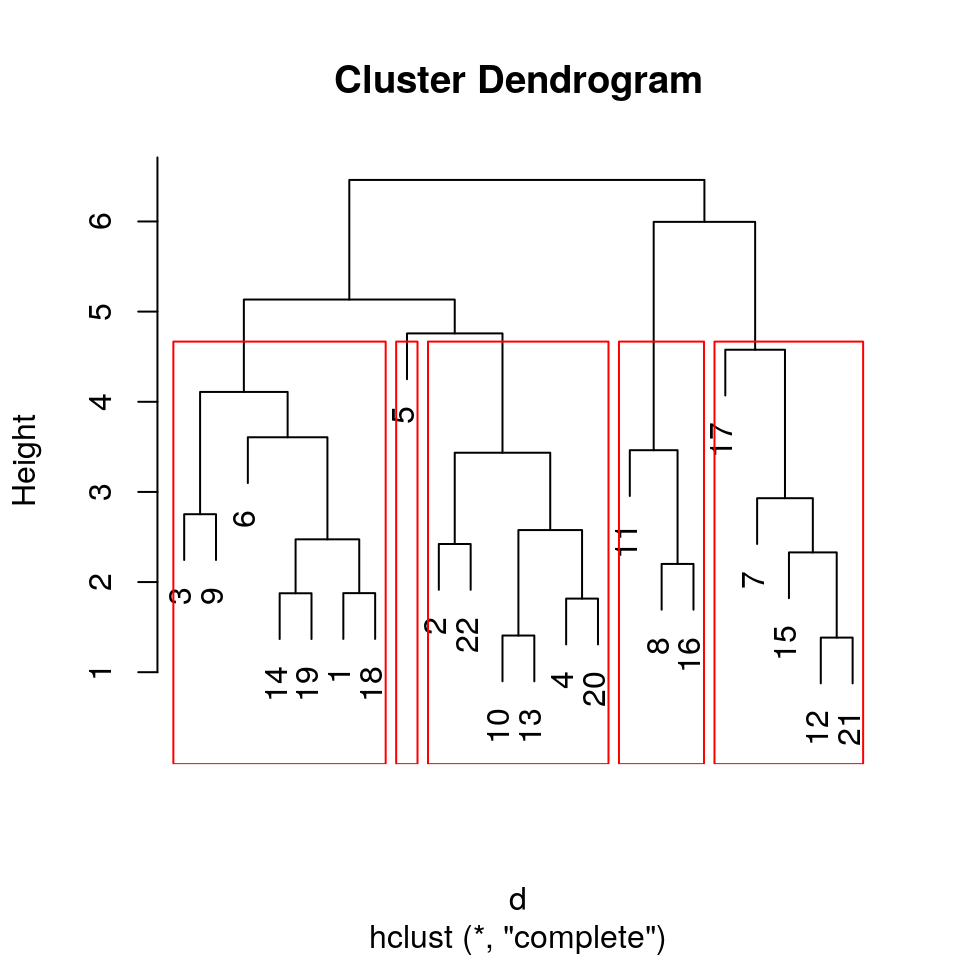
Da “Statistica per data science con R” – di Enrico Pegoraro – R Project.
Gli algoritmi di clustering lavorano calcolando la distanza tra gli elementi per aggregare in un cluster gli elementi più “vicini” tra loro. Per questo motivo è necessario scegliere una distanza, che in genere è quella euclidea (lunghezza del segmento che congiunge due punti) ma potrebbe anche essere una metrica diversa più adatta, per esempio, a calcolare la differenza fra due record di una tabella.
Quando applichiamo gli algoritmi ai dati prodotti nel mondo reale utilizzando una metrica euclidea, è necessario che i dati siano sempre numerici e le etichette o dati categorici siano trasformati in numeri, inoltre dobbiamo assicurarci che le caratteristiche vengano misurate tutte sulla stessa scala, applicando, se necessario, la standardizzazione) o la riduzione in scala min-max.
Applicazioni aziendali dell’intelligenza artificiale: clustering
Gli algoritmi di clustering trovano larga applicazione in tutti i contesti in cui si hanno poche informazioni sui dati e si vogliono scoprire le somiglianze in base alle caratteristiche a disposizione. I dati in possesso di un’azienda in genere non sono classificati, anzi, ci si rende conto di avere una enorme quantità di dati che devono essere riordinati, analizzati, rappresentati in dashboard e presentati. Quale miglior contesto per applicare degli algoritmi di clustering per iniziare a esplorare ed estrarre informazioni utili.
Potrebbe essere necessario provare diversi algoritmi prima di individuare quello ottimale, ma lo sforzo è giustificato dall’ impagabile conoscenza che se ne estrae; possono emergere connessioni e correlazioni inaspettate o difficilmente immaginabili e individuabili da un essere umano.
Alcune applicazioni del clustering sono la rilevazione di frodi, il riconoscimento di notizie false, la classificazione di libri in biblioteche, la segmentazione della clientela a fini di marketing, personalizzazione di prodotti per incrementare le vendite.
Ci focalizziamo sulle applicazioni in ambito aziendale nei diversi contesti di gestione della clientela, del marketing, della produzione, dei sistemi aziendali.
Come utilizzare l’AI per segmentare i clienti in base alle loro caratteristiche
Una delle necessità in un’azienda è la gestione dei clienti e quanto più si riescono a caratterizzare tanto più sarà possibile ottimizzare le attività per la cura e soddisfazione di questi (customer care). In genere si pensa a questo compito come tipico di un CRM (Customer Relationship Management). A questi strumenti si può affiancare un sistema di intelligenza artificiale basato sull’apprendimento non supervisionato per raggruppare in modo automatico le diverse tipologie di clienti.
Le aziende si possono concentrare sull’offerta dei loro prodotti analizzando le caratteristiche particolari degli acquirenti e promuovendo dei programmi per attirarli. Gli algoritmi di clustering possono raggruppare individui con caratteristiche simili e permettono di effettuare l’analisi sul comportamento della clientela; la creazione di gruppi di individui con abitudini e interessi comuni aiuta le aziende a determinare come migliorare la proposta di mercato e la vendita di prodotti e servizi.
Le variabili che caratterizzano i clienti sono diverse in base al contesto; per esempio, in un contesto di eCommerce i dati della clientela sono costituiti da molte informazioni sulle azioni e sulla navigazione nel sito web, sulla periodicità di visita e di acquisto. Se si tratta di vendita al dettaglio diretta, non da web, si avranno meno indicazioni, ma sarà più importante l’informazione geospaziale, l’uso di una tessera fedeltà e i relativi dati che si possono raccogliere sugli acquisti. Se il cliente è a sua volta un’azienda, le informazioni saranno altre. Il concetto fondamentale è che per ogni cliente bisogna raccogliere un insieme di dati e non importa se le variabili sono molte, perché gli algoritmi di clustering sono particolarmente efficienti; più sono le variabili e più la clientela sarà segmentata con dettagli significativi.
Come utilizzare l’AI per identificare i cluster dei dati in modo automatico
Gli algoritmi di clustering, come per tutto quello che fa parte del Machine learning, necessitano di alcuni parametri; tra questi alcuni devono essere scelti da chi esegue l’analisi dei dati. La scelta può essere affidata all’intuizione del data scientist in base alla sua esperienza, tuttavia, volendo automatizzare il processo si deve ricorrere alla valutazione di coefficienti che stabiliscono la qualità dei risultati ottenuti. In particolare, gli algoritmi k-means e i suoi derivati devono avere in input il numero di cluster desiderato. La soluzione in questo caso consiste nel provare diversi valori di k e poi stabilire il migliore in base alla valutazione di indici di qualità (Elbow, Silhouette). Per altri algoritmi il problema non si pone. In generale alcuni parametri devono essere fissati a priori, ma questo non impedisce di creare un sistema che in modo automatico – in modalità batch – esegua una pipeline di questo tipo:
- lettura dati
- operazioni di cleansing
- trasformazioni – scaling o standardizzazione
- applicazione algoritmo di clustering k-means con diversi valori di k (da 2 a 10 per esempio)
- calcolo coefficienti di qualità dei cluster ottenuti per ogni k
- scelta del k che fornisce la migliore segmentazione
- passaggio in produzione del modello
Segue infine la rappresentazione dei risultati in una dashboard visualizzabile con un elenco delle caratteristiche tipiche dei singoli cluster che fornisce una spiegazione della segmentazione effettuata e suggerisce le variabili di attenzione su cui lavorare per migliorare l’aspetto aziendale in analisi.

Come utilizzare l’AI per analizzare le relazioni tra i dati
Tra i vari algoritmi di ML, ce ne sono diversi per scoprire le relazioni tra i dati e per analizzarle; si tratta di metodi di apprendimento sia di tipo supervisionato sia di tipo non supervisionato. Tra gli algoritmi supervisionati troviamo regressione, alberi decisionali, k-nearest neighbour (kNN). Tra gli algoritmi non supervisionati troviamo le macro-classi: riduzione di dimensionalità, clustering, apriori. L’utilizzo di sistemi supervisionati richiede una analisi preliminare che va sotto il nome di EDA (Exploratory Data Analysis) per stabilire la qualità delle fonti, quali siano gli algoritmi più adatti e avere una prima intuizione su cosa aspettarsi. Gli algoritmi non supervisionati per loro natura non hanno necessità di informazioni preliminari, si usano per scovare le relazioni; tuttavia, è consigliabile fare un’esplorazione iniziale dei dati e sfruttare i diversi coefficienti di correlazione per una indagine preliminare sui possibili legami tra le variabili a disposizione.
La valutazione di diversi indici di correlazione evidenzia le eventuali relazioni di dipendenza tra le variabili, mentre il clustering evidenzia relazioni di similarità e “distanza” tra le informazioni.
Poniamo quindi l’attenzione sugli algoritmi di clustering e sul tipo di relazioni che possono rivelare tra i dati. Come abbiamo visto questi algoritmi sono in grado di trovare relazioni nascoste, inaspettate, difficilmente rilevabili da un osservatore umano, specialmente se la quantità di dati e di cluster è elevata. Il clustering consente di rilevare le similitudini tra elementi, raggruppare gli elementi in cluster sulla base di caratteristiche comuni. La relazione primaria che rileva un algoritmo di clustering è che un gruppo di entità (persone, clienti, luoghi o altro) possiede caratteristiche comuni e possono essere gestiti tutti allo stesso modo; l’analisi di queste caratteristiche in comune è la base di partenza per ottimizzare la strategia aziendale.
Come utilizzare l’AI per generare report personalizzati e analizzare i dati
Sembra scontato, in un’azienda che punta alla crescita, la disponibilità di dati e la loro analisi produce informazione e questa deve essere organizzata e presentata agli alti livelli per una conduzione strategica efficace. È importante prendere coscienza in azienda della disponibilità di dati che naturalmente vengono prodotti con il normale flusso operativo. La produzione di report scaturiti dall’analisi delle informazioni deve essere adatta ai fruitori e al loro dominio di appartenenza. La cluster analysis, per esempio, può essere utilizzata per:
- esaminare l’offerta di prodotti rispetto ai concorrenti
- raggruppare zone geografiche in cluster a fini di marketing
- identificare gruppi di acquirenti che hanno criteri di scelta e acquisto simili
- in generale, segmentare il mercato
- la “geo-segmentazione” può fornire informazioni su che prodotti vengono acquistati, in che negozio (fisico o virtuale) l’utente preferisce acquistare, fino a stimare la costituzione e le tendenze di un gruppo familiare.
Questo esempio è un caso di tipico uso delle tecniche di clustering per supportare il marketing e incrementare le vendite di prodotti; lo sforzo operativo risiede nella creazione della catena di elaborazione delle sorgenti di informazioni fino alla realizzazione di report personalizzati. Nei report deve essere visibile l’entità del raggruppamento, ovvero i cluster individuati; deve essere accessibile la lista degli elementi di ogni cluster insieme alle caratteristiche che li accomunano. La produzione costante di report specifici consente di osservare rapidamente le variazioni in positivo o in negativo il trend di vendita e di dedurne le possibili cause.
Come utilizzare l’AI per l’ottimizzazione delle campagne pubblicitarie
Che sia la vendita di un prodotto, di un servizio, o che sia il lancio di un sito web con una applicazione specifica, la riuscita e il successo dipendono molto dalla preparazione e dalla campagna di marketing o campagna pubblicitaria. Identificare segmenti di mercato per caratteristiche geografiche, demografiche, psicologiche e comportamentali è indubbiamente una fonte di informazioni che permette di attuare una strategia di maggior successo per l’approccio al mercato. Segmentare la clientela sulla base del comportamento, applicare strategie di mantenimento della clientela, predisporre buoni e sconti per la clientela, sono alcune delle attività supportate da strumenti di intelligenza artificiale.
Come per altri aspetti aziendali, quale miglior terreno per applicare algoritmi di clustering per definire segmenti di mercato che identifichino nuovi clienti; le caratteristiche riconosciute nei nuovi segmenti di mercato guideranno l’impostazione della campagna pubblicitaria per un maggior ritorno di investimento.
Ma su che dati si può lavorare per effettuare queste analisi di mercato?
Il suggerimento principe è di usare variabili facilmente accessibili, una fonte sempre presente è costituita dai dati dei software gestionali in azienda. A queste aggiungiamo quelle che si possono collezionare senza operazioni di censimento ovvero senza intervistare un campione di una possibile clientela. Ci si può affidare a informazioni raccolte dai social, informazioni ricavate dall’analisi sul mercato di prodotti concorrenti, informazioni provenienti da dataset pubblici di analisi di mercato. Se si tratta di utenti web è possibile raccogliere molte informazioni nel completo rispetto della privacy, sul comportamento e sul livello di coinvolgimento dell’utente, oltre alla fruibilità dell’applicazione web.

Come integrare l’AI per il clustering dei dati con altri sistemi aziendali
Abbiamo visto che i metodi di clustering lavorano bene su dati in cui ci sono caratteristiche accomunabili; i dati in un’azienda sono concentrati in un singolo sistema o distribuiti in più sistemi e possono essere raccolti in continuo nel caso di applicazioni web oppure risiedere in uno o più database. Sicuramente in un’azienda ci sono sistemi di tipo ERP (Enterprise Resource Planning), CRM (Customer Relationship Management) o equivalenti oltre ad applicativi specifici; questi si appoggiano ognuno a un database proprietario. Integrare il clustering con altri sistemi aziendali significa integrare le sorgenti dati in un flusso verso il modello di analisi. Ci sono diverse modalità di integrazione delle sorgenti dati:
- attraverso delle API verso le applicazioni proprietarie quando non è possibile accedere direttamente al database; in questo caso poi si procede con uno dei punti successivi.
- attraverso processi di ETL (Extract Transform Load) o anche ELT; questi processi spesso copiano i dati e producono una base dati intermedia
- attraverso software (tecnicamente parliamo di middleware) di data virtualization; i dati provenienti da fonti multiple vengono aggregati velocemente e sono resi disponibili in un sistema logico senza copiare o spostare i dati originali. Questa soluzione sembra essere quella attualmente più vantaggiosa.
In tutti i casi si converge verso un database unico con dati aggregati, fisico (copia dei dati) o logico (virtualizzazione) che è la base di partenza per il processo visto nel paragrafo precedente su come identificare in automatico i cluster.
Come implementare una soluzione di clustering basata sull’AI in azienda
A conclusione dei vari aspetti affrontati riassumiamo i passi fondamentali per implementare una soluzione di clustering in azienda:
- verificare la disponibilità di dati, le fonti e la loro accessibilità
- stabilire il dominio per cui vogliamo fare l’analisi dei dati; può essere il marketing, la customer engagement, la ritenzione dei clienti, la valutazione dei fornitori, la gestione delle risorse interne e quant’altro.
- integrare le fonti dati disponibili, API, ETL, Data virtualization.
- effettuare le trasformazioni necessarie e la pulizia dei dati (cleansing). Ricordiamoci che gli algoritmi di clustering lavorano su numeri e stabiliscono l’appartenenza di un dato a un cluster con la valutazione della distanza tra elementi; pertanto, è opportuno prevedere sempre lo scaling delle caratteristiche.
- applicare uno o più algoritmi e valutare quale dà i risultati migliori; variare i parametri per ottenere un modello ottimizzato.
- preparare i report e le dashboard per pubblicare i risultati
Per eseguire al meglio tutte le attività indicate può essere utile un approccio MLOps costituito dalle tecniche per gestire le risorse, implementare e automatizzare l’integrazione continua, la distribuzione continua, l’addestramento continuo per i sistemi di machine learning e per effettuarne il monitoraggio. Un approccio con MLOps garantisce una gestione di successo dei modelli di clustering e in generale di AI in azienda.
Tutta questa tecnologia permette di avere il giusto messaggio per il cliente giusto al tempo giusto e permette di misurare i risultati degli investimenti in marketing.