
Come funzionano gli algoritmi? E in che modo riescono a riconoscere oggetti o persone all’interno di un’immagine, anche quando queste appaiono in posizioni, dimensioni o contesti differenti? La risposta passa per una combinazione di modelli matematici, apprendimento automatico, rappresentazioni neurali gerarchiche e architetture sempre più raffinate.
Nel 2025, il riconoscimento visivo non si basa più soltanto sulle reti neurali convolutive tradizionali, ma anche su modelli ibridi come i Vision Transformer, che sfruttano meccanismi di attenzione per catturare relazioni spaziali su larga scala, e su tecniche di self-supervised learning, che permettono ai modelli di apprendere anche senza etichette. Questi progressi hanno migliorato la robustezza, la scalabilità e la capacità di generalizzazione dei sistemi di visione artificiale, rendendoli adatti a contesti reali e dinamici, come la guida autonoma, la diagnostica medica e la robotica collaborativa.
Indice degli argomenti:
Neuroni e perceptroni nelle reti neurali
La struttura di base che consente a un algoritmo di riconoscere, ad esempio, un gatto in un’immagine è fornita dalle reti neurali artificiali. Questi modelli computazionali imitano il funzionamento del cervello umano attraverso neuroni artificiali, ciascuno dei quali riceve uno o più input, applica a ciascuno un determinato peso e restituisce un output. Ogni neurone elabora così informazioni semplici come la presenza di determinati contorni, forme geometriche o variazioni di colore, trasmettendole ai neuroni dei livelli successivi.
Attraverso questa elaborazione distribuita e gerarchica, la rete riesce a riconoscere caratteristiche sempre più complesse: da semplici bordi a strutture intermedie (come gli occhi o le orecchie di un gatto), fino alla sagoma completa dell’oggetto. Questo processo, noto come estrazione progressiva delle feature, permette al sistema di identificare un gatto anche se varia per colore, razza, posa o sfondo.
Ogni neurone può essere rappresentato come una funzione matematica che calcola una somma pesata degli input ricevuti e produce un output. L’input può essere una costante o una variabile, ma in genere si lavora con variabili numeriche continue che rappresentano l’intensità di pixel o altri parametri visivi.
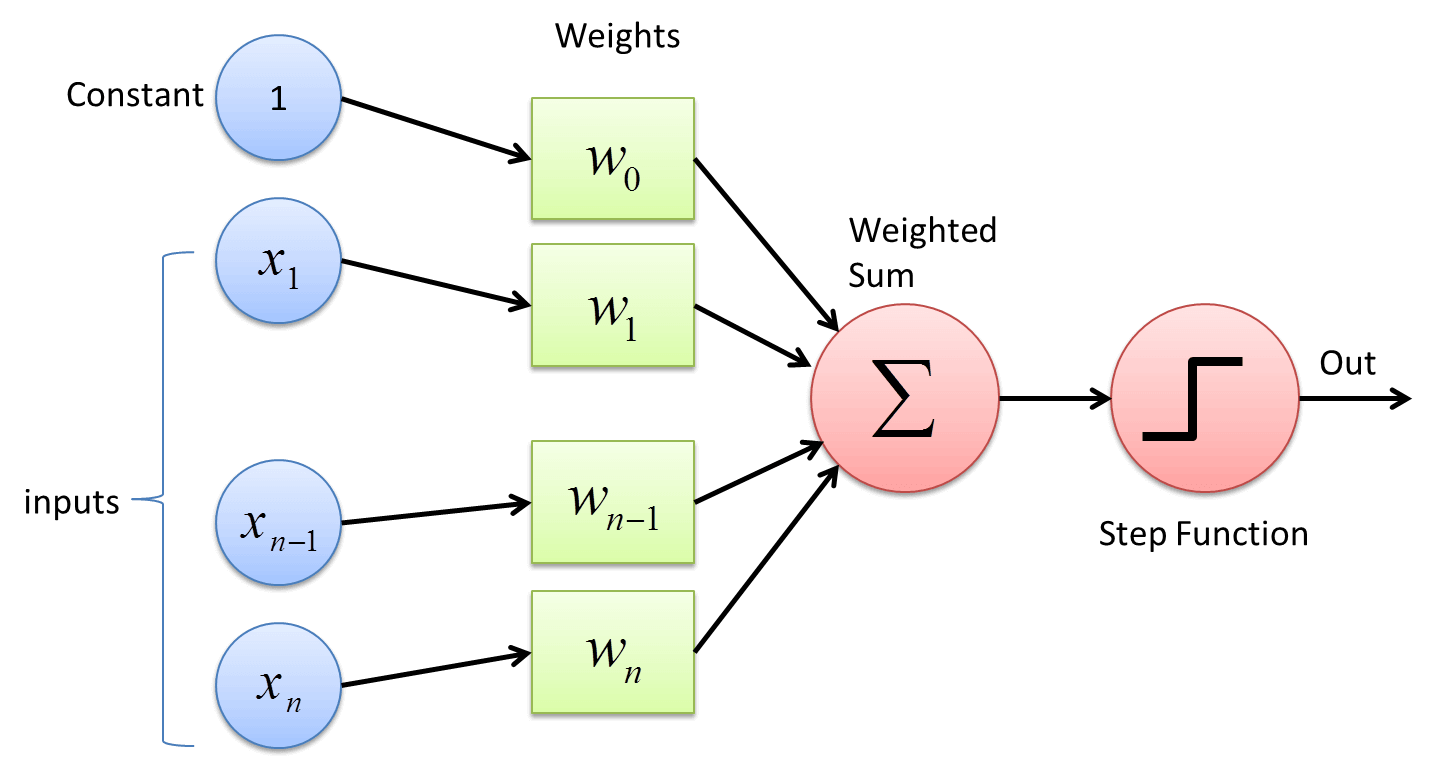
Ad esempio, se un neurone ha 3 input, rappresentati dai valori 1, 2 e 3, e tre pesi associati pari a 11, 12 e 13, l’output sarà dato dalla somma pesata degli input: 1×11 + 2×12 + 3×13 = 11 + 24 + 39 = 74. Questo è un esempio di neurone che utilizza una funzione di identità, cioè una funzione lineare che restituisce direttamente la somma algebrica, senza alcuna soglia di attivazione.
Quando invece si utilizza una step function, l’output è 1 se il risultato supera una certa soglia e 0 altrimenti. In questo caso il neurone viene chiamato perceptrone, considerato il modello originario delle reti neurali per la sua semplicità. In alternativa, molte reti moderne usano funzioni sigmoidali o ReLU (Rectified Linear Unit): la sigmoide restituisce un valore compreso tra 0 e 1, utile per modellare probabilità, mentre la ReLU restituisce 0 per input negativi e l’input stesso per quelli positivi, favorendo la propagazione del gradiente nelle reti profonde.
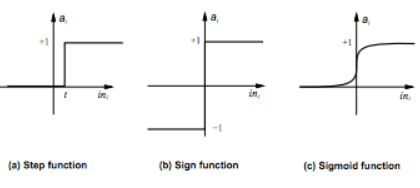
Le reti neurali si compongono tipicamente di tre livelli fondamentali:
- input layer, che riceve i dati grezzi (es. pixel);
- hidden layer, uno o più strati intermedi che elaborano l’informazione;
- output layer, che fornisce il risultato finale della rete.
Un singolo neurone non è in grado di rappresentare funzioni complesse, ma l’interconnessione di migliaia di neuroni organizzati in più layer consente di rappresentare strutture e concetti molto sofisticati.
Negli ultimi anni, sono stati introdotti elementi fondamentali per migliorare l’apprendimento e la stabilità dei modelli:
- Batch Normalization, che normalizza le attivazioni per ogni mini-batch e accelera il training;
- Dropout, che spegne casualmente alcuni neuroni durante il training per evitare l’overfitting;
- ResNet e DenseNet, architetture che sfruttano connessioni residue (skip connections) per permettere a reti molto profonde di apprendere senza perdere informazioni.
In una rete neurale, ogni neurone è collegato a più neuroni del livello successivo, permettendo così una propagazione progressiva e combinata delle informazioni.
Cosa rappresenta un input in image detection
Nel campo della image detection, l’input di una rete neurale è tipicamente rappresentato da una matrice di pixel, ovvero un insieme bidimensionale di valori numerici che descrivono l’intensità luminosa o i canali di colore di ciascun punto di un’immagine.
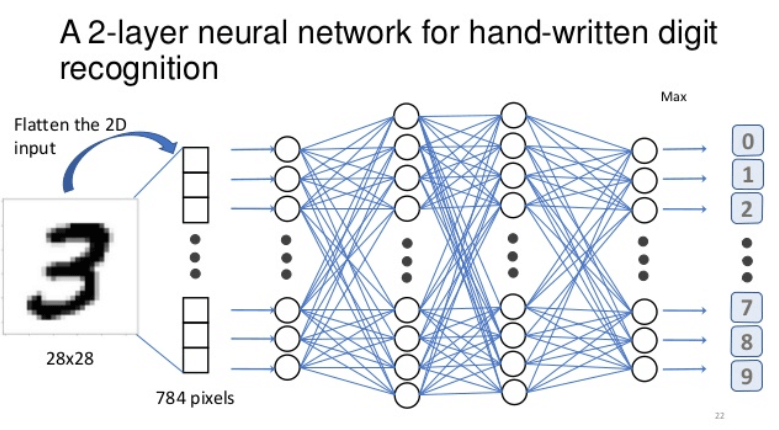
Un esempio classico, ancora oggi utilizzato nei benchmark e nell’apprendimento introduttivo, è la classificazione di digit scritti a mano, come nel dataset MNIST. MNIST è un dataset ampiamente utilizzato per addestrare e testare algoritmi di riconoscimento visivo, in particolare reti neurali. Contiene 70.000 immagini in scala di grigi di cifre scritte a mano (da 0 a 9), ognuna in formato 28×28 pixel. È considerato uno dei benchmark più semplici ma efficaci per introdurre concetti come classificazione, apprendimento supervisionato e backpropagation nel machine learning.
Ogni immagine ha dimensioni 28×28 pixel, e ogni pixel in scala di grigi corrisponde a un valore compreso tra 0 (nero) e 255 (bianco), per un totale di 784 input che entrano nella rete.
Questi input vengono elaborati dagli hidden layer, che trasformano progressivamente le informazioni grezze in rappresentazioni astratte utili alla classificazione. Inizialmente la rete non ha alcuna conoscenza e commette errori. Tramite un dataset di training, le uscite prodotte dalla rete vengono confrontate con le etichette corrette (apprendimento supervisionato). Grazie all’algoritmo di backpropagation, la rete aggiorna i pesi per correggere i propri errori e migliorare la propria capacità di classificazione.
Un’altra variante più complessa prevede che l’immagine sia in formato RGB, quindi con tre canali: rosso, verde e blu. Anche in questo caso, ogni pixel ha tre valori numerici (uno per canale) tra 0 e 255. L’intera immagine viene quindi convertita in un vettore di input che può arrivare a dimensioni elevate (28x28x3 = 2.352 input, ad esempio).
Durante l’addestramento, la rete viene guidata a riconoscere quale cifra (da 0 a 9) sia presente nell’immagine. Se il numero mostrato è un 3, la rete dovrebbe produrre un’uscita (output layer) in cui il neurone corrispondente alla cifra “3” ha attivazione alta (es. vicino a 1), mentre gli altri sono prossimi allo 0.
Questo semplice scenario rappresenta le basi della classificazione visiva, da cui derivano applicazioni molto più complesse che operano su immagini ad alta risoluzione, con più oggetti, colori e contesti ambientali diversi.
Le difficoltà con immagini reali e il ruolo delle CNN
Quando si passa da immagini semplici e normalizzate, come quelle dei digit scritti a mano, a immagini reali ad alta risoluzione, emergono nuove complessità. Come riconoscere, ad esempio, un gatto in una fotografia di 1000×1000 pixel?
- Il gatto può apparire ovunque nell’immagine
- Può assumere dimensioni diverse (a seconda della distanza dalla fotocamera)
- Può essere visto da angolazioni variabili e in condizioni di luce mutevoli
Per affrontare queste difficoltà, si utilizzano le Convolutional Neural Network (CNN), che rappresentano una delle architetture più efficaci nel campo della visione artificiale.
Le CNN si basano su convolutional layer (CL), che analizzano piccole porzioni dell’immagine (dette receptive field) mediante filtri appresi durante il training. Questi filtri sono in grado di individuare pattern locali come:
- bordi e contorni
- transizioni di colore
- texture e motivi geometrici
Nel tempo, e con strati successivi, la rete apprende a costruire rappresentazioni gerarchiche che permettono di riconoscere caratteristiche semantiche complesse, come le orecchie, gli occhi o la postura di un gatto, indipendentemente dalla posizione o dalla scala.
I convolutional layer si trovano generalmente nei primi livelli della rete e agiscono come una sorta di scanner intelligente che percorre l’immagine e ne estrae caratteristiche ricorrenti. Spesso questi layer vengono pre-allenati in modalità non supervisionata, ad esempio tramite autoencoder o tecniche self-supervised, per poi essere raffinati con supervisione nelle fasi successive del training.
Questo approccio permette di ottenere reti robuste, in grado di riconoscere un oggetto anche se ruotato, parzialmente oscurato o presente in più varianti. Le CNN costituiscono ancora oggi la base per molte architetture ibride più avanzate, come i modelli Transformer visivi che integrano il concetto di attenzione su scala globale.
I modelli più recenti (2023–2025)
Negli ultimi due anni, l’evoluzione dei modelli di visione artificiale ha portato alla nascita di architetture sempre più sofisticate, in grado di gestire la crescente complessità delle immagini reali e dei contesti applicativi:
- EfficientNet e ConvNeXt: rappresentano l’evoluzione delle CNN classiche, con un bilanciamento ottimale tra profondità, larghezza e risoluzione. ConvNeXt in particolare adotta alcune strategie strutturali dei Transformer pur mantenendo la struttura convolutiva.
- Vision Transformer (ViT): segmentano l’immagine in “patch” (blocchi rettangolari), trattandole come sequenze simili alle parole nel linguaggio naturale. Grazie all’uso del meccanismo di self-attention, i ViT sono capaci di catturare relazioni spaziali anche a lunga distanza, superando in molti casi le prestazioni delle CNN su dataset complessi come ImageNet.
- DETR (DEtection TRansformer) e Segment Anything Model (SAM): combinano l’attenzione globale con modelli di rilevamento o segmentazione, rivoluzionando il modo in cui si affrontano i compiti di object detection e segmentazione semantica. SAM, in particolare, consente di segmentare qualsiasi oggetto in un’immagine a partire da un semplice prompt.
Parallelamente, l’adozione di tecniche di self-supervised learning ha ridotto la dipendenza da dataset etichettati manualmente. Metodi come SimCLR, BYOL e DINO permettono di pre-addestrare i modelli su grandi quantità di dati non annotati, migliorando la generalizzazione e rendendo il training più scalabile.
Come le reti neurali imparano le istruzioni
Ma come fa una rete neurale ad “imparare”? Per sviluppare una competenza discriminativa, essa ha bisogno di due elementi fondamentali: un dataset di training e un algoritmo di apprendimento.
Il primo ingrediente è il dataset di training, ovvero un insieme di esempi (come immagini) accompagnati da una etichetta che indica la risposta corretta. Per esempio, se vogliamo che la rete riconosca il numero “3” scritto a mano, dobbiamo mostrarle numerose immagini etichettate con il valore corretto. Proprio come un bambino che impara a riconoscere il numero tre osservandolo ripetutamente, anche la rete, grazie all’esposizione continua, inizia a distinguere i tratti caratteristici della cifra.
Il secondo elemento è l’algoritmo di backpropagation, che aggiorna i pesi della rete durante l’addestramento. Ogni volta che la rete fa una previsione, il risultato viene confrontato con il valore atteso. La funzione di errore misura la differenza tra i due. L’algoritmo calcola quindi quanto ogni peso ha contribuito all’errore e lo corregge tramite discesa del gradiente (gradient descent). Questo meccanismo di correzione iterativa consente alla rete di affinare le proprie previsioni man mano che processa nuovi dati.
Nel caso di una rete che analizza immagini RGB 28×28 di cifre scritte a mano, la backpropagation agisce su migliaia di connessioni neurali, migliorando gradualmente la capacità del sistema di identificare un “3” anche se stilizzato in forme diverse. Col tempo, la rete diventa sufficientemente robusta da classificare cifre mai viste prima, purché simili a quelle apprese.
Più ampio e vario è il dataset, migliore sarà la generalizzazione. E proprio come un bambino che impara a distinguere con sicurezza un 3 da un 1 o da un 4, la rete è in grado, dopo un numero sufficiente di esempi, di riconoscere correttamente anche i casi ambigui o stilizzati.
Come può avvenire questo? Chiariamolo con un ulteriore esempio.

Immaginiamo una matrice 5×5 che rappresenta una faccina stilizzata. Ogni pixel della matrice può assumere valore 0 (spento) o 1 (acceso). L’obiettivo è insegnare alla rete a distinguere tra sorrisi e faccine tristi.
Supponiamo che nelle immagini rappresentanti un sorriso, i tre pixel centrali della riga inferiore siano sempre attivi. La rete neurale, esaminando centinaia di esempi, può apprendere che questa specifica configurazione corrisponde a una faccia felice, e assegnare quindi pesi elevati a quei tre pixel, considerandoli fortemente “discriminatori” rispetto alla classe della faccina triste. Questo esempio mostra come la rete possa associare pattern locali ben definiti a un significato semantico.
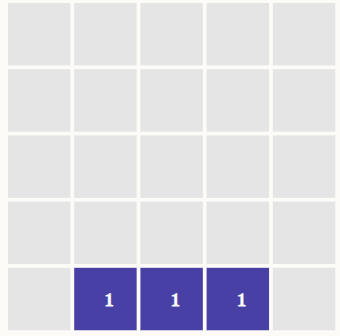
uttavia, tale apprendimento ha limiti evidenti. Se la rete ha visto solo immagini in formato fisso (es. 5×5 o 28×28), non è in grado di generalizzare automaticamente a dimensioni maggiori come una 1000×1000. In teoria si potrebbe ridurre la grande matrice, ad esempio raggruppando i pixel e sintetizzando la loro informazione, ma questa operazione funziona solo in scenari estremamente controllati.
Il problema si aggrava se consideriamo oggetti reali e complessi come un gatto:
- Il gatto può apparire in posizioni differenti
- Può avere scale diverse (essere vicino o lontano)
- Può essere parzialmente visibile, ruotato, o in pose inconsuete
Inoltre, il concetto di gatto richiede una comprensione visiva molto più profonda di quella necessaria per un semplice sorriso stilizzato. La rete deve cogliere strutture ricorrenti ma variabili, come orecchie, occhi e proporzioni del corpo.
Per affrontare questi tre problemi fondamentali:
- Come riconoscere un gatto, indipendentemente da razza e colore?
- Come riconoscerlo a diverse scale?
- Come riconoscerlo in posizioni e angolazioni diverse?
…entrano in gioco le convolutional neural network, o reti neurali convolutive, progettate per risolvere proprio questi limiti.
Il ruolo delle reti neurali convolutive (CNN)
Le convolutional neural network (CNN) sono una componente chiave del moderno deep learning. Una rete neurale profonda (deep neural network, DNN) è costituita da numerosi hidden layer, ovvero strati intermedi che elaborano progressivamente le informazioni.
Lo sviluppo e la diffusione delle CNN sono stati fortemente accelerati dall’avvento delle GPU (unità di elaborazione grafica), che grazie alla loro architettura parallela consentono l’elaborazione simultanea di migliaia di operazioni, rendendo possibile l’addestramento di reti molto profonde in tempi compatibili con le applicazioni reali.
Riprendendo l’esempio delle faccine 5×5, l’ipotesi iniziale prevedeva di classificare come felice una faccina se erano accesi i 3 pixel centrali della riga inferiore. Si tratta di una logica semplice, ma non sufficiente per affrontare problemi reali. Infatti, se si volesse aumentare la complessità del riconoscimento, sarebbe necessario:
- aggiungere più hidden layer,
- aumentare il numero di neuroni per layer,
- gestire un numero molto maggiore di parametri (pesi).
Tuttavia, questa strategia comporta una crescita esponenziale del numero di connessioni da ottimizzare, rendendo il training molto costoso in termini di tempo e dati. Addestrare una rete densa (fully connected) profonda richiederebbe milioni o miliardi di esempi, spesso non disponibili o troppo onerosi da annotare.
Per ovviare a questi limiti, entra in gioco una soluzione estremamente efficace: il convolutional layer (CL). Questo tipo di layer utilizza filtri (o kernel) che si muovono sull’immagine, analizzandola localmente e condividendo i pesi. In questo modo:
- si riduce drasticamente il numero di parametri,
- si catturano pattern locali ricorrenti,
- si migliora la capacità di generalizzare dell’intero modello.
I convolutional layer sono ciò che rende le CNN adatte a interpretare immagini complesse: essi permettono di riconoscere forme, bordi, texture, e successivamente anche strutture semantiche come volti, animali o segnali stradali, con un’efficienza computazionale molto maggiore rispetto ai modelli tradizionali fully connected.
Convolutional layer (CL), cosa sono e a cosa servono
Un CL è uno speciale tipo di layer che si può aggiungere a una rete neurale facendola diventare una CNN (convolutional neural network).
Quale è la sua caratteristica principale? Proprio quella che ci serve per individuare i gatti, ovvero può individuare una caratteristica specifica (nel nostro caso un gatto) perché è in grado di individuare caratteristiche specifiche dell’immagine come ad esempio:
- macchie di luce e buio
- macchie di un colore specifico
- bordi o contorni orientati in maniera diversa
- pattern
- altri oggetti simili
I CL permettono, grazie al loro inserimento, di individuare “concetti più complessi” di un digit o di una faccina, come ad esempio “le orecchie di un gatto” indipendentemente dalla scala o dall’orientamento. Possono essere usati anche per individuare “gli occhi di una persona”, “un segnale di stop” o “una figura ottagonale”.
Questo risponde a tutte e tre le domande sopra, ovvero: come individuo il concetto di “gatto”, come lo individuo se è scalato, come lo individuo in base alla posizione.
Il CL può essere immaginato come uno scanner che invece di prendere l’immagine in toto è in grado di farne una sorta di scansione e “capire” se nell’immagine ci sono le orecchie del gatto. Prima lo fa scansionando l’intera immagine, poi dividendola in 4 quadranti, poi in 8 e così via. Poi la gira di 90 gradi ad esempio e fa lo stesso e così via. Fino a essere in grado di individuare quello che ci serve ovunque sia.
Quindi, ad esempio, un gatto posto in un’immagine in alto a destra viene individuato non purché nel training set ci sia un’immagine con un gatto in alto a destra, bensì purché la rete neurale sia stata allenata (train) per imparare cosa è un gatto.
Questo è eccezionale se pensiamo a come le foto di un gatto possano variare per zoom, angolazione, esposizione, colore ecc.

Come funziona questo? Il “trucco” risiede nella condivisione dei pesi tra neuroni convolutivi, che consente di ridurre notevolmente il numero di parametri e di estendere la generalizzazione del modello. Ciò significa che una rete, anche senza aver mai visto un gatto posizionato esattamente in alto a destra, può riconoscerlo grazie alla capacità di identificare pattern ricorrenti ovunque compaiano nell’immagine — proprio come farebbe un essere umano.
Questo approccio sfrutta la proprietà di traslazionalità delle CNN: i neuroni convolutivi rispondono agli stessi stimoli visivi in posizioni diverse dell’immagine, grazie all’applicazione degli stessi filtri su tutte le regioni.
In pratica, lo stesso filtro convolutivo viene applicato a porzioni diverse del layer di input. Diversi neuroni possono quindi condividere il medesimo pattern attivante (es. l’orecchio di un gatto) anche se questo si trova in posizioni differenti. L’effetto è simile a uno scanner intelligente che attraversa l’immagine per verificare se e dove sono presenti i tratti distintivi dell’oggetto cercato.
Questi convolutional layer (CL) si trovano generalmente nei primi livelli della rete e ricevono i dati visivi allo stato grezzo. Proprio per questo motivo, vengono talvolta pre-allenati in modalità unsupervised, cioè senza etichette, attraverso l’analisi statistica di grandi collezioni di immagini. Ad esempio:
- se si forniscono molte immagini di gatti, i layer inferiori tenderanno a specializzarsi nel riconoscere musi, orecchie, baffi;
- se si forniscono immagini di edifici, apprenderanno a riconoscere cornici, finestre, linee verticali.
Questi CL “specializzati” possono poi essere riutilizzati in altri modelli come base per nuovi task di image recognition, con un notevole risparmio in termini di dati e tempo di addestramento.
I livelli superiori della rete, invece, vengono addestrati con tecniche di supervised learning e backpropagation, per ottimizzare la classificazione finale.
È interessante osservare come i CL costituiscano componenti general purpose: capaci di estrarre macro-caratteristiche visive indipendentemente dalla specifica applicazione. Possono essere considerati una sorta di “alfabeto visivo” neurale, riutilizzabile tra compiti diversi.
Combinando questi layer convolutivi con una rete neurale addestrata tramite backpropagation, si ottengono sistemi in grado di identificare persone, animali o oggetti all’interno di immagini complesse, assegnando a ciascun elemento un grado di probabilità (es. “persona: 0,91”).

Ecco spiegato come una rete neurale, grazie ai convolutional layer (CL), diventa una CNN e riesce a classificare con precisione immagini complesse come quelle contenenti gatti, persone o oggetti di vario tipo. La potenza della CNN deriva proprio dalla capacità di cogliere pattern visivi anche se spostati, ruotati o deformati, e di riconoscerli con un alto grado di accuratezza grazie alla traslazionalità e alla condivisione dei pesi.
Che cosa sono le GAN
Le GAN (Generative Adversarial Network) sono un tipo di rete neurale che non si limita a classificare, ma genera immagini inedite. Si basano su un principio di apprendimento competitivo tra due reti: una generativa e una discriminativa.
In una rete neurale tradizionale, i livelli bassi imparano tratti visivi ricorrenti come contorni e texture, mentre i livelli alti imparano concetti più astratti e specifici, utili per classificazioni mirate (es. distinguere un segnale di stop da altri simboli). Tuttavia, i layer inferiori possono anche essere utilizzati al contrario, chiedendo loro di “immaginare” un’immagine che attivi certi neuroni. Questo processo porta la rete a generare immagini piuttosto che classificarle: è come se, dopo aver imparato a riconoscere un gatto, provasse a disegnarlo. Le immagini ottenute possono apparire surreali o oniriche, come accade con il celebre DeepDream di Google.
Attenzione: quando si parla di “reti sognanti” o “allucinate”, non si fa riferimento a una capacità di sognare in senso umano, ma si intende semplicemente che le immagini generate possono sembrare frutto di una visione psichedelica, poiché riflettono l’attività interna della rete neurale durante la generazione.
Per creare immagini di gatti, volti umani o oggetti realistici, lo scienziato Ian Goodfellow, del team Google Brain, ha introdotto un sistema composto da due reti in competizione:
- una rete generativa, che cerca di produrre immagini realistiche partendo dal rumore;
- una rete discriminativa (avversaria), che deve distinguere le immagini vere (del dataset) da quelle false (generate).
Le due reti si allenano contemporaneamente in uno schema chiamato apprendimento avversariale. Il risultato è una GAN, capace di migliorare progressivamente la qualità delle immagini prodotte.
Come agisce un sistema GAN
All’inizio dell’addestramento, la rete generativa produce immagini rozze e facilmente identificabili come false dalla rete discriminativa. Tuttavia, grazie all’alternanza rapida dei cicli di generazione e verifica, entrambe migliorano: la generativa impara a ingannare la discriminativa, mentre quest’ultima affina la sua capacità di riconoscere falsi.
Con il tempo, la rete generativa diventa talmente abile da produrre immagini indistinguibili da quelle reali, almeno per l’occhio umano. Questa dinamica porta le GAN a essere oggi uno degli strumenti più potenti nel campo dell’intelligenza artificiale generativa, utilizzate in ambiti che vanno dal fotoritocco al design fino alla creazione di volti umani completamente sintetici.
Il sistema quindi allena due modelli, che si allenano insieme. All’inizio dell’allenamento, è facile individuare le immagini reali da quelle generate dalla rete generativa (visto che sono piuttosto diverse). Poi, ripetendosi a “velocità computer” i cicli di creazione immagine e verifica, diventa sempre più difficile distinguere le immagini reali da quelle generate, ovvero la rete neurale generativa impara a generare immagini che sembrano reali.
Questo è permesso dal fatto che mentre migliora la rete generativa, migliora anche la rete avversaria, in un percorso verso l’ottimizzazione di entrambe.
Il risultato si può vedere nelle immagini pubblicate sotto:

Le immagini sopra sono generate da una GAN sviluppata da Nvidia in un progetto del professor Jaakko Lehtinen (articolo di dettaglio). È difficile capire quelle generate da una GAN rispetto a quelle reali!





