
Per mimare quello che accade, quasi inconsciamente, a un essere umano quando riconosce oggetti o persone all’interno di immagini o video, è necessario avere la disponibilità di software e hardware con prestazioni elevate. Lo sviluppo delle reti neurali ha incrementato l’evoluzione dell’image recognition, ma per comprendere meglio come le reti neurali artificiali sono sempre più simili a quelle naturali, bisogna capire cos’è una rete neurale e come funziona.
Indice degli argomenti:
Brevi cenni sulle reti neurali
In breve, si definisce artificial neural network (ANN) un modello computazionale parallelo, costituito da numerose unità elaborative omogenee fortemente interconnesse mediante collegamenti di varia intensità. Cercando di semplificare: ci sono delle unità di input che recepiscono i dati del problema da risolvere; c’è poi il processo di elaborazione che si propaga in parallelo nella rete fino alle unità di output, che forniscono il risultato (ved. Fig. 1). Ovviamente una ANN non viene programmata per risolvere un dato problema ma deve essere addestrata mediante una serie di esempi della realtà da modellare.
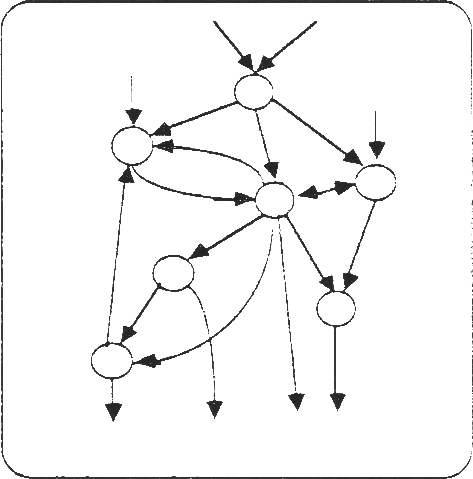
figura 1
Cos’è la image recognition
La vista, come gli altri sensi, concorre negli esseri viventi alla percezione del mondo circostante; ma si può affermare lo stesso riferendosi a un computer? Per rispondere a questa domanda è necessario unire i risultati salienti di studi e ricerche effettuati già a partire dagli anni Cinquanta. Infatti i primi studi in materia risalgono a un articolo pubblicato da due neurofisiologi — David Hubel and Torsten Wiesel — che dopo aver collocato degli elettrodi nella corteccia visiva di un gatto anestetizzato provarono a registrare l’acquisizione di immagini trasmesse da un proiettore. I risultati di questo esperimento stabilirono che la corteccia visiva primaria è composta dall’insieme di strutture neuronali semplici e che il processo visivo si attiva utilizzando proprio queste strutture (figura2).
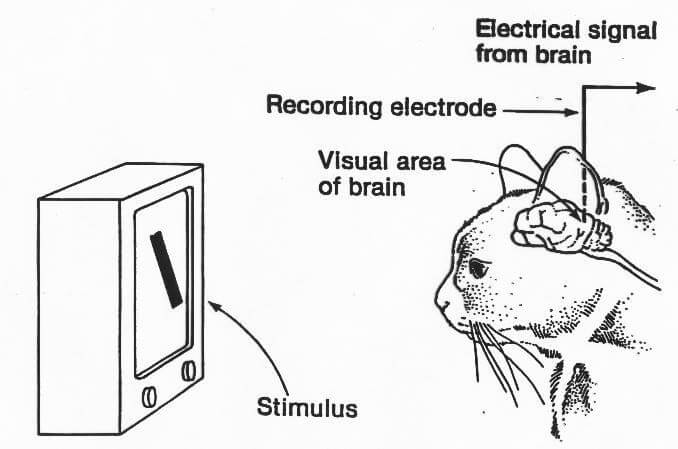
Figura 2
Nel 1959, Russell Kirsh, con il suo team, sviluppò un dispositivo in grado di trasformare le immagini acquisite in una griglia di numeri binari, che poi poteva essere trasferita a un qualsiasi computer. Nel 1963 Lawrence Roberts elaborò un processo che trasformava immagini da 2 a 3 dimensioni. Infine, saltando alcune decadi, furono gli studi sulla neonata intelligenza artificiale, svolti prima da Kunihiko Fukushima e poi da Yann LeCun, che nel 1989 gettarono le basi delle convolutional network, utili a mimare il processo utilizzato dagli esseri umani e dagli animali, nell’interpretazione e nella percezione del mondo circostante.
Ma è solo nell’anno 2012, quando Alexnet vince l’ILSVRC con largo margine, che viene introdotto il concetto di image recognition; ovvero che la combinazione fra computer vision e software di intelligenza artificiale permette il riconoscimento di persone, luoghi e oggetti all’interno di immagini o sequenze video.
Quindi grazie a una ANN si riesce a replicare tutta la componente umana relativa all’apprendimento per poi ottenere un risultato, che in questo caso è il riconoscimento di immagini. Questo avviene, come già accennato in precedenza, perché una ANN evita, in un computer, il collo di bottiglia dell’accesso alla memoria ed è intrinsecamente parallelo: infatti integra memorizzazione (nelle connessioni) e computazione (in tante unità elaborative autonome), in analogia con l’intelligenza biologica.
Ma quanto è ottimizzata una ANN nel riconoscimento di immagini? La risposta è: una ANN non è ottimizzata per questo tipo di utilizzo. Infatti una ANN gestisce ogni pixel collegandolo a ogni singolo neurone (input) con la conseguenza che il carico computazionale(connessioni) raggiunto rende meno accurata la rete stessa. Pertanto per risolvere questo problema sono state implementate le convolutional neural networks (CNNs o ConvNets), o reti neurali convolutive. Questo tipo di reti sono ottimizzate per l’image recognition perché traggono vantaggio dal fatto che, in una data immagine, la vicinanza fra due pixel è fortemente correlata alla somiglianza. Quindi piuttosto che collegare ogni input al singolo neurone in un dato layer, le CNNs limitano le connessioni in modo che ogni neurone accetti solo input da una piccola sottosezione del layer precedente (ved. Fig.3 ). Di conseguenza, ogni neurone è responsabile solo dell’elaborazione di una determinata parte di un’immagine; che più o meno è lo stesso principio di funzionamento dei singoli neuroni corticali nel cervello. Prima di descrivere una delle possibili applicazioni dell’image recognition, è utile riassumere il meccanismo, che una CNN segue per riconoscere un oggetto o altro all’interno di una immagine:
- il primo strato è responsabile del rilevamento di linee, bordi, e cambiamenti di luminosità;
- le informazioni vengono quindi passate al livello successivo, che combina le funzioni precedenti e crea dei rilevatori che andranno ad identificare delle semplici forme;
- il processo continua così di livello in livello, diventando sempre più astratto. Il livello più profondo sarà così in grado di rilevare oggetti specifici (indicati nella fase di addestramento);
- gli ultimi strati della rete integreranno tutte queste caratteristiche complesse e produrranno una o più previsioni di classificazione;
- il valore previsto verrà confrontato con l’output (richiesto durante il processo di apprendimento), mentre il valore o i valori errati verranno classificati come tali e la rete riproporrà il processo di apprendimento per ottenere un risultato più accurato;
- quindi la rete procede avanti e indietro, correggendosi, fino a quando non viene raggiunto un risultato soddisfacente (dove l’errore viene minimizzato).
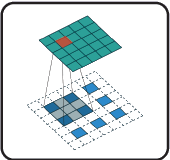
Figura 3
Come si realizza una CNN
Trasformare la teoria in pratica costruendo una CNN da zero può essere un’impresa lunga e costosa. Per prima cosa è necessario avere un dataset abbastanza grande per l’apprendimento automatico delle immagini. ImageNet e Pascal VOC; sono, forse, i database gratuiti più utilizzati che contengono milioni di immagini taggate con parole chiave sul loro contenuto. Una volta ottenuti i dati, è tempo di costruire una macchina che possa imparare da essa. Anche in questo caso sono disponibili diverse librerie open source che permettono la costruzione di sistemi di apprendimento automatico per servire diversi tipi di utilizzo: visione artificiale, dal riconoscimento facciale ed emotivo allo screening medico e al rilevamento di grandi ostacoli nelle automobili; di seguito alcuni fra i più utilizzati:
- Google TensorFlow è una delle librerie più conosciute, se non altro perché è stata pubblicata gran parte del suo codice. Oltre ad essere utilizzato nel mondo opensource, essendo proprietà di Google è il motore di Google Now e Google Foto;
- UC Berkeley Caffe è in circolazione dal 2009 e rimane popolare grazie alla sua facilità di personalizzazione e alla vasta comunità di sviluppatori, per non parlare poi dell’utilizzo da parte di Pinterest e Yahoo! / Flickr. Anche Google si rivolge a Caffe per alcuni progetti come DeepDream;
- Torch diventato popolare grazie all’utilizzo da parte di Facebook AI Research (FAIR).
Questi strumenti, sebbene flessibili e robusti, richiedono un investimento in conoscenza e competenze da parte delle aziende che hanno intenzione di investire nell’image recognition e renderla parte del loro core business. Per questo motivo alcune aziende cambiano strategia, non investono al loro interno ma sfruttano al massimo le possibili applicazioni dell’image recognition utilizzando, quelle che in gergo vengono definite delle ready-to-wear API(Application Programming Interface) dove:
- Google Cloud Vision, ad esempio, offre una serie di servizi di rilevamento di immagini dal riconoscimento di caratteri facciali e ottici (testo) al rilevamento di punti di riferimento;
- Microsoft Cognitive Services (nata Project Oxford) offre una raccolta di API per il riconoscimento di immagini visive, tra cui rilevamento di volti ed emozioni;
- Clarifai offre API che aiutano le aziende a organizzare i loro contenuti e filtrano immagini e video generati dagli utenti non sicuri.
Ovviamente questi servizi di tipo hosted sono tutti a pagamento in modalità pay per use o basati sul numero di transazioni che dovranno essere effettuate.
Le applicazioni che utilizzano reti neurali convolutive
Quali sono le applicazioni di uso comune che si avvalgono di questa tecnologia? Di seguito alcuni esempi di uso:
- Industria automobilistica: non solo le grandi case automobilistiche tradizionali stanno lavorando sulle auto a guida autonoma, ma anche i giganti della tecnologia stanno mettendo le mani sulla produzione di tali auto. Il motivo alla base della ricerca e sviluppo di queste macchine è sicuramente la riduzione degli incidenti stradali, e di conseguenza il rispetto delle regole e dei regolamenti del traffico, ecc. Oltre a Google e Apple è recente l’annuncio da parte di Cisco per una sua partnership con la società di produzione automobilistica tradizionale, Hyundai, per consentire aggiornamenti via etere alle auto autonome;
- Gioco: allo stato attuale, la tecnologia image recognition consente al giocatore di utilizzare la propria posizione reale come campo di battaglia per avventure virtuali, cambiando la modalità di accesso al gioco(riconoscimento facciale) oltre che la fruizione dello stesso;
- Settore sanitario: la tecnologia di riconoscimento delle immagini sta fornendo un immenso aiuto nel settore sanitario; partendo dalle procedure microchirurgiche con l’aiuto anche della robotica per il riconoscimento, ad esempio, di masse tumorali da asportare, fino al rilevamento delle emozioni in tempo reale può anche essere utilizzato per verificare lo stato dei pazienti durante il periodo di ricovero o quando stanno per essere dimessi;
- Merged reality: per superare le carenze di realtà virtuale(VR) e realtà aumentata(AR), è stata creata questa nuova “realtà” che offre esperienze del mondo virtuale in modo più dinamico e naturale. Ad esempio, la Windows Holographic Shell di Microsoft, una cuffia wireless che ti consente di portare oggetti reali nel mondo virtuale usando webcam 3D;
- Commercio al dettaglio: esiste una grande richiesta di questa tecnologia nel settore del commercio al dettaglio. Un esempio fra tutti potrebbe essere Trax progettato per elaborare fino a 40.000 immagini all’ora, che permette di confrontare qualità e il prezzo di un prodotto basandosi sulle immagini che vengono fornite dal cliente e tutto questo in tempo reale;
- Sicurezza: che si tratti di un ufficio, uno smartphone, una banca o una casa, le misure di sicurezza sono parte integrante di molte piattaforme. Infatti sono stati sviluppati molti dispositivi di sicurezza che includono droni, telecamere di sicurezza, dispositivi biometrici per il riconoscimento facciale, ecc. La società Netatmo, ha sviluppato una videocamera per interni intelligente, che ha una funzione che avvia la registrazione di video solo quando il sistema rileva volti sconosciuti;
- Social media: il riconoscimento delle immagini ha reso più facile per gli esperti di marketing trovare immagini all’interno dei social media. Inoltre offre enormi vantaggi alle aziende per quanto riguarda il servizio clienti. Ad esempio, nel 2016, Facebook ha aggiunto una funzionalità per i non vedenti combinando la tecnica di riconoscimento facciale e le tecnologie di testo automatiche per generare una descrizione accurata del contenuto della foto senza che la stessa fosse taggata;
- Motori di ricerca visivi: questa tecnologia utilizza il riconoscimento delle immagini per fornire agli utenti risultati di ricerca più accurati. Google e Bing sono quelli più conosciuti e forse più longevi sul mercato.
Le reti neurali convolutive e il comportamento del cervello umano
A questo punto sembrerebbe che l’image recognition, grazie all’utilizzo delle CNN sia riuscita a diventare simile se non addirittura uguale come comportamento a quanto accade alla corteccia visiva umana, pertanto potrebbe essere ovvia la seguente domanda: quanto sono simili questi due sistemi e quali sono le loro somiglianze? (ved. Fig. 3)
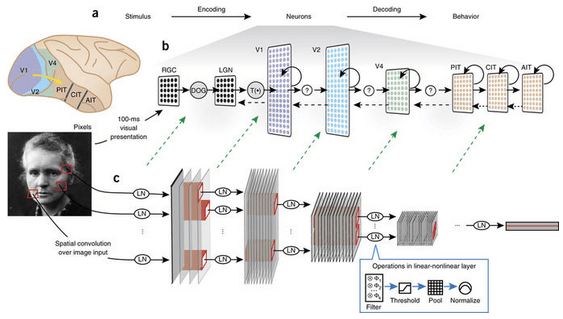
Figura 3
Attualmente, la maggior parte dei metodi di apprendimento applicati sono supervisionati, ciò significa che è necessaria una enorme quantità di dati il cui accesso è a volte costoso e difficile da ottenere.
C’è poi il tema delle cosiddette adversarial images (ved. Fig. 4), che, in breve, sono immagini la cui categoria di classe sembra ovvia a un essere umano, ma causa errori di comprensione da parte di una rete neurale. Errori di questo tipo possono far sorridere se durante una cena fra amici, la rete neurale scambiasse un piatto di pasta al pesto con un piatto di verdure, ma cosa accadrebbe a una macchina a guida autonoma in caso di errore di riconoscimento degli ostacoli o dei pedoni?

figura 4
Gran parte dei progressi nell’apprendimento è diretta conseguenza dei miglioramenti dell’hardware, in particolare delle GPU. Le GPU consentono l’elaborazione ad alta velocità di calcoli che possono essere eseguiti in parallelo. In conclusione, sebbene l’elaborazione possa sembrare simile in entrambi i sistemi, è un errore credere che questo sia il modo in cui i neuroni biologici si comportano effettivamente o che le nostre reti neurali usano lo stesso modello di feedforward e backpropagation per apprendere.
La percezione visiva è un processo lineare che procede dalla retina ad altre regioni di elaborazione specializzate; questa è la rete che il machine learning (ML) ha tentato di imitare senza avere una idea precisa di come siano stabiliti i pesi biologici sinaptici.



