
Dopo anni di hot topic sull’IA e hashtag spopolanti sui social circa le mirabolanti promesse dell’intelligenza artificiale, soprattutto quella “forte”, in grado di replicare l’intelligenza umana – chiamata Artificial General Intelligence, AGI – e superare a pieni voti il test di Turing, è tempo di uscire dall’hype (termine utilizzato nel marketing che sta per “montatura”). Non vi è tuttavia evidenza scientifica di essere nemmeno vicini a un livello tale per cui le macchine possano essere considerate pensanti e il loro “pensiero” possa avvicinarsi o addirittura superare quello umano [1].
Indice degli argomenti:
L’AI da John Searle a Kai-Fu Lee
John Searle, filosofo americano, nel 1980 descrisse l’esperimento mentale della Stanza cinese nell’articolo “Minds, Brains and Programs” pubblicato dalla rivista scientifica Behavioral and Brain Sciences, ove riuscì a dimostrare che non si può paragonare la mente umana a un computer, opponendosi ai teorici della Strong AI. Secondo Searle, infatti, il computer ha la capacità di eseguire una serie di istruzioni, un programma, cioè ha capacità di sintassi, ma ciò non implica che possa conoscere il significato delle sue azioni, cioè che abbia capacità semantica. Nell’ipotesi di trovarsi da solo in una stanza e di ricevere dall’esterno dei foglietti di carta scritti in cinese, pur non conoscendo la lingua cinese, egli può ordinare i foglietti provando a seguire su un manuale una regola stabilita a priori, producendo così un brano in lingua cinese di cui però non comprende il significato. Così si dimostra che la mente umana ha intenzionalità che il computer invece non possiede.
È lo stesso principio di Kai-Fu Lee, scienziato ed executive per Apple, Microsoft e Google, che ci ha invece convinto che l’AI riuscirà perfettamente a sostituire l’uomo in una serie di operazioni ripetitive basate su quantità di variabili note e lunga a piacere, ma ciò che l’AI non sarà mai in grado di sostituire è tutto ciò che avrà a che fare con la sensibilità, con i sentimenti, con la creatività.
L’AI tra regole costitutive e regole vincolanti
Occorre distinguere tra regole costitutive e regole vincolanti: è la stessa differenza tra giocare a scacchi e giocare a calcio. L’AI funziona bene sulle prime, perché ha capacità computazionale e applica tecniche statiche di collegamento e confronto, mentre sulle seconde gioca bene chi sa avere a che fare con madre natura, chi ha estro.
Come anticipava Alberto Sangiovanni-Vincentelli, professore di scienze computazionali alla University of California Berkeley e pioniere dell’electronic design automation, all’inaugurazione del 155mo Anno Accademico del Politecnico di Milano, la vera sfida non è sviluppare l’intelligenza delle macchine, ma abilitare il collegamento tra intelligenza umana e potenziamento tecnologico. Il 95% dei progetti di innovazione si basa su scienza, ricerca e studio. Sudore. Il resto dei tentativi di utilizzare l’IA si risolverà in fuffa: spesso perché mancano i dati. Eppure quanti sono gli algoritmi di apprendimento automatico? 57, quelli censiti da Wikipedia, oltre a decine di metodi.
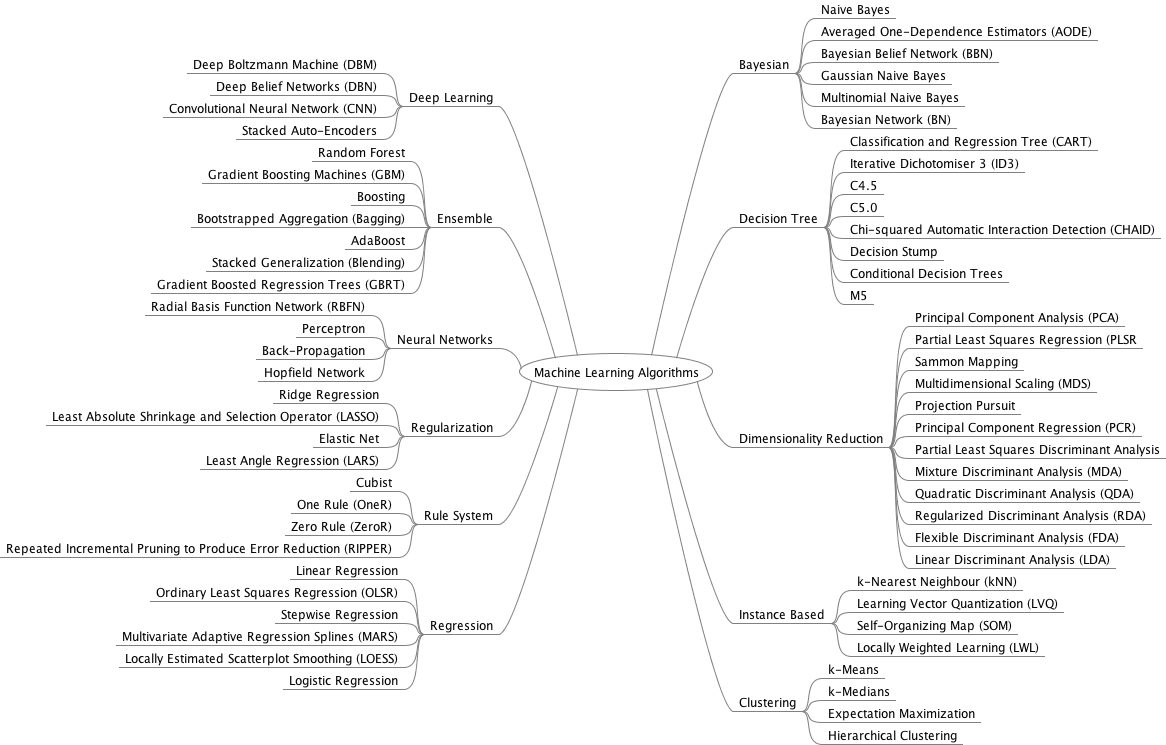
La scienza, la conoscenza dei fondamentali è l’ingrediente principe di qualsiasi ricetta a base di AI. Ma da qui parte anche il dramma del Data scientist, che da profilo professionale modello “unicorno” e 21st century sexiest job, si è ritrovato davanti a una realtà un po’ diversa, disillusa, in quanto è finita l’utopia dei giovani data scientist che volevano entrare nel cerchio magico della data science perché arrogava a sé la capacità unica di risolvere problemi complessi con algoritmi di apprendimento automatico sempre più “cool”, performanti e dall’altissimo impatto sul business. La polvere magica è diventata presto sabbia che un colpo di vento ha portato via.
Del resto, anche Luciano Floridi, professore di filosofia ed etica dell’Informazione all’Università di Oxford, ricorda che l’AI è un ossimoro, un odi-et-amo, il cui successo non è basato sul matrimonio tra macchine e intelligenza, ma sul divorzio tra la capacita di agire con successo per un fine – diciamo, come risolvere un problema – e la necessità di essere intelligenti nel farlo.
Da qui i problemi di etica e di governance delle risorse cognitive, perché ciò che conta è cosa ci facciamo con l’innovazione e in che direzione vogliamo andare, come il ciberneta platoniano che conoscendo i venti e le maree, sapendo leggere le mappe, arriva a destinazione. Disposto a fare compromessi su come si arriva all’obiettivo finale, ma non sull’essenza dell’obiettivo. Quanti sono i modi per fare bene la governance? Infiniti. Tutti quelli che si trovano sulla frontiera dell’ottimo di Pareto, ossia la buona notizia è che non esiste una sola soluzione a tutti i problemi (utopia) ma una tendenza ad avvicinarsi asintoticamente all’ottimo, in ottica di continuous improvement.
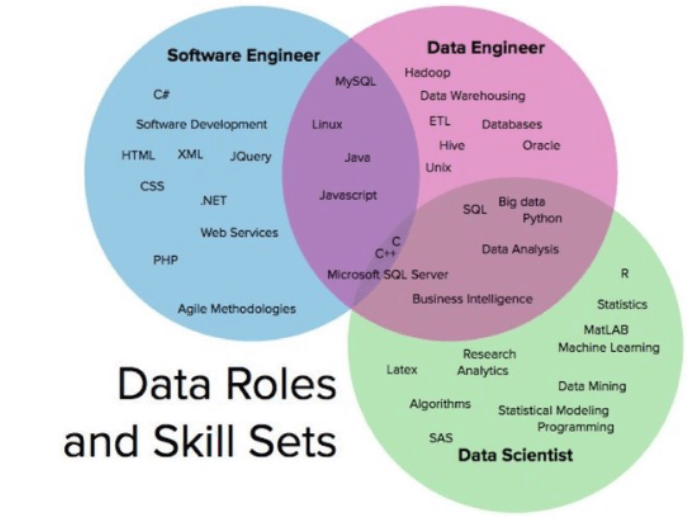
Che cos’è la data science
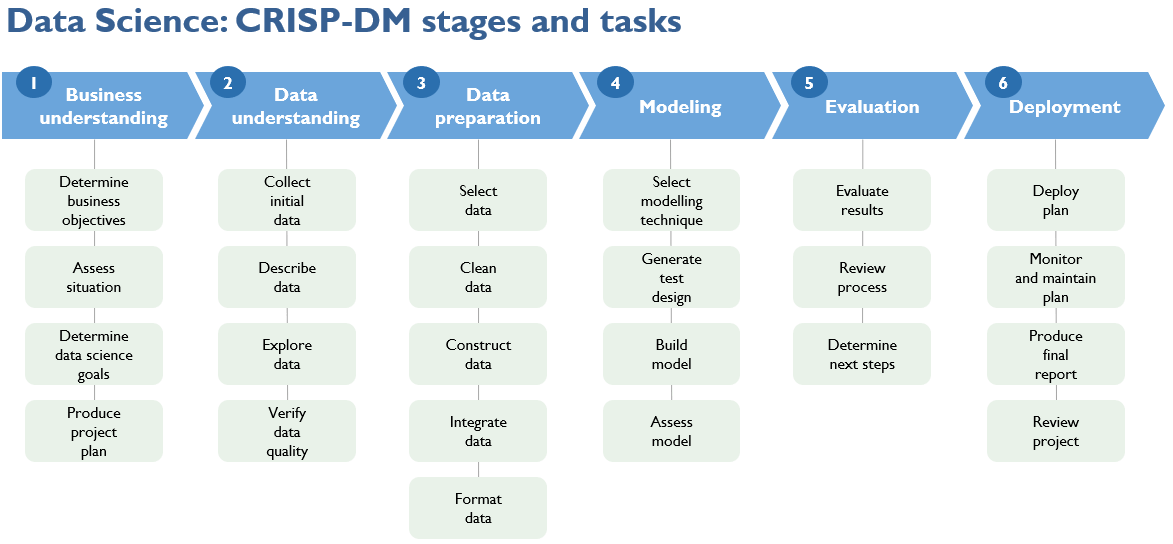
La data science è in realtà un viaggio, un percorso interdisciplinare che, come insegna la metodologia Cross Industry Standard Process for Data Mining (CRISP-DM) [2], muove i primi passi attraverso 3 step iniziali, che non è possibile saltare, nemmeno se si dispone del silver bullet dato dal 58mo, più recente e più performante algoritmo di machine learning: business understanding, data understanding, data preparation. È necessaria la competenza di dominio e, oltre alla raccolta di dati di qualità, la consapevolezza degli stessi e di come trarne valore. E non a caso è ampiamente riconosciuto in letteratura che circa l’80% del tempo di un progetto di data science viene impiegato in tali prime fasi, mentre le successive di data modeling, evaluation e deployment richiedono scienza e tecnica, oltre all’immancabile ricorso al business per la necessaria validazione. È la chiave di volta per le aziende data-driven. Ed è anche una grande sfida di governance per la Pubblica amministrazione e per le società in-house che, in qualità di responsabili al trattamento, gestiscono moli di dati significative, ad esempio in ambito sanitario. Progetti di successo di collective intelligence, interdisciplinari, devono fondere conoscenza sui dati e data literacy alla competenza universitaria di data science.
Per questo, al di là degli strumenti di machine learning, pure fondamentali, per il futuro sarà sempre più necessario aiutare i data scientist a diventare più consapevoli nella lettura e nell’interpretazione dei dati, investendo in generale nell’alfabetizzazione dei dati e nella costituzione di uno Shazam dei dati, anche attraverso algoritmi che stimolino i sistemi di analytics nella feature selection, nell’anomaly detection e nel suggerire nuovi dati significativi da prendere in considerazione nel challenging dei diversi modelli. Da qui anche la possibilità di vedere in azione nuove figure professionali – data custodian, data steward e data evangelist – con il compito di “educare” l’intera organizzazione aziendale al corretto utilizzo dei dati.
L’AI e la privacy
Il Regolamento Europeo sulla Protezione dei Dati Personali nr. 679/2016 , c.d. GDPR, è riuscito anche in questo: l’ultimo pezzo mainstream del rapper Marracash parla di data protection, algoritmi, dati sensibili e degli effetti derivanti dallo scandalo Cambridge Analytica:
Oh, algoritmo che sei nei server | Manda il mio pezzo nella Top 10 e il mio video nelle tendenze | Mandami uno spot, ad hoc, non so cosa comprare | Tocca i miei dati sensibili per guidarli a votare
Sembra una banalità, ma anche se il messaggio non avrà il tenore di un intervento in materia di Antonello Soro, contribuisce a diffondere una maggiore cultura della privacy.
È innegabile: superato l’hype, una AI senza regole desta preoccupazioni. E per questo, sempre all’insegna dell’interdisciplinarietà, filoni di sicuro interesse e attualità coinvolgono l’etica e la spiegabilità degli algoritmi automatizzati, nonché la sfida nell’attribuzione delle responsabilità o delle negligenze qualora si verifichi un errore con relativa valutazione delle implicazioni. Va affermato con forza il principio antropocentrico, secondo cui l’intelligenza artificiale deve essere sempre messa al servizio delle persone e non viceversa.
Anche ai sensi dell’art.22 del Regolamento Europeo 679/2016, “l’interessato ha il diritto di non essere sottoposto a una decisione basata unicamente sul trattamento automatizzato, compresa la profilazione, che produca effetti giuridici che lo riguardano o che incida in modo analogo significativamente sulla sua persona”.
Poche settimane fa, al PyTorch Dev Conference di San Francisco, Facebook ha rilasciato Captum, una libreria per spiegare le decisioni di reti neurali attraverso il confronto nell’attribuzione dei neuroni ai diversi strati rispetto ai modelli esistenti, oltre a uno strumento di visualizzazione (Insights), fornendo altresì l’implementazione dei cosiddetti gradienti integrati come DeepLift e Conductance. Captum non è che l’ultimo in ordine cronologico strumento rilasciato recentemente per l’interpretazione dell’AI, oltre IBM AIExplainability360toolkit e Microsoft InterpretML.
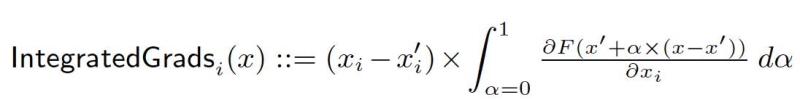
Un tema decisamente attuale, considerata anche la chiusura delle consultazioni, avvenuta il 24 gennaio 2020, sulle Linee Guida riguardo l’Explainable AI emesse da Alan Turing Institute e ICO, l’autorità UK di tutela dei dati personali.
Sono concetti di salvaguardia dei diritti basilari dell’uomo, all’insegna di un Human rights by design and by default: trasparenza, minimizzazione dati, sistemi di consenso flessibile, analisi rischio sono concetti applicati da sempre alla data protection, anche se è innegabile quanto siano ancora controversi. Il percorso legislativo non è compiuto ed è notorio che la velocità dell’innovazione tecnologica è di più ordini di grandezza diversa da quella normativa. Emblematico l’esempio delle procedure di impact assessment in Olanda che hanno impiegato un anno per valutare la sola introduzione dei pacchetti Microsoft Office nella pubblica amministrazione.
Il GDPR ha ampliato i diritti riconosciuti all’interessato con riferimento ai dati che lo riguardano, in un contesto permeato sempre più dal ricorso a nuove tecnologie. Quando il GDPR introduce il diritto delle persone di ottenere una “comprensibile spiegazione della logica coinvolta” nei processi di decisione automatica qualora abbiano “effetti legali” sugli individui stessi, senza tecnologie capaci di esplicitare la logica delle black box questa indicazione rischia di restare dead letter o di rendere fuorilegge molte tecnologie oggi utilizzate. Insomma, c’è un sottile confine tra il rischio di rallentare il progresso che nel campo dell’AI procede a velocità vertiginosamente più elevate di quelle che possano occorrere al legislatore per normare il settore, così come di lasciare immotivatamente nella black box le logiche degli algoritmi decisionali.
È apprezzabile a tal proposito l’invito di Giusella Finocchiaro ai giuristi a utilizzare lo strumento più importante, l’interpretazione, soprattutto nei casi come quello dell’AI in cui manca una corrispondenza diretta fra fattispecie e norma (ad hoc), evitando la tendenza, esaltata dai mezzi di comunicazione, di richiedere una norma nuova per ogni nuovo fenomeno illecito.
Pubblicata di recente anche l’indagine conoscitiva sui big data condotta congiuntamente ma, sotto tre prospettive diverse e complementari, dall’Autorità per le Garanzie nelle Comunicazioni, dall’Autorità Garante della Concorrenza e del Mercato e dal Garante per la Protezione dei Dati Personali.
In essa è evidente quanto susciti ancora attualissima discussione la vexata quaestio atta a riconciliare da un lato il rispetto del criterio di minimizzazione nell’uso dei dati personali, dovendo essere utilizzati solo i dati indispensabili, pertinenti e limitati a quanto necessario per il perseguimento delle finalità per cui sono raccolti e trattati, dall’altro l’esigenza degli algoritmi di utilizzare quanti più dati possibili per identificare relazioni nascoste ma significative (insights).
Si tratta di paradossi non troppo distanti dal “gatto di Schroedinger”, ove il GDPR va sì considerato una grande pietra miliare, ma non un traguardo in quanto sarebbe errato considerarlo strumento per la difesa dell’ordine pubblico da parte degli Stati dell’UE: chi fa sul serio analisi del rischio, sa che anzitutto deve capire da chi difendersi, altrimenti non sarebbe in grado di identificare quali siano le contromisure da applicare. Questa componente spesso viene trascurata, ma nessuno potrebbe definire in tempi umanamente ragionevoli un’analisi rischio fatta bene. Senza contare che parlando delle minacce del cyberspazio, non va dimenticato che proprio cyberspazio è un termine coniato nel 1984 da William Gibson, per definire “un’allucinazione vissuta consensualmente ogni giorno da miliardi di operatori legali, in ogni nazione, da bambini a cui vengono insegnati i concetti matematici”, priva di significato semantico.
Io sono i miei dati
I sistemi di apprendimento automatico hanno bisogno di dati “annotati” da esseri umani (supervised learning) o quantomeno selezionati e preparati (unsupervised learning). Assimilano con questo anche gli errori o i pregiudizi (bias) introdotti anche involontariamente dai progettisti, replicandoli in ogni futura relativa applicazione. Oppure si può incorrere in dataset sbilanciati, che sovrastimano o sottostimano il peso di alcune variabili nella ricostruzione della relazione causa–effetto necessaria per spiegare certi eventi e, soprattutto, per prevederli. A fronte di queste “minacce”, quello che è ragionevole auspicare è una sempre maggior attenzione all’etica delle decisioni instillate da algoritmi automatizzati e alla responsabilità delle implicazioni che da quelle possono derivare.
Sempre Luciano Floridi sottolinea come “my data and my memories are more like my hand, my liver, my lungs, my heart”. È una nuova consapevolezza socratica che si sposta verso l’Io sono i miei dati. Indipendentemente dalla capacità della legge di proteggere i nostri dati, sta a noi valutare quando un uso dei dati sia legittimo e positivo oppure quando si configura una distorsione. Da qui parte una nuova responsabilità che è dovere di tutti noi attivare e promuovere.

Nella locuzione di giovenalesca memoria, Quis custodiet custodes? , è implicito il quesito, tutt’altro che retorico, riguardo chi ci proteggerà dai protettori stessi. Diciamo che la parte più grossa la dovremo fare sempre noi stessi, magari istituendo comitati etici indipendenti nelle aziende che sviluppano l’IA oppure appellandosi a un codice ippocratico di algor-etica, essendoci richiesta una sempre maggior consapevolezza nella condivisione dei nostri dati. Per tutto il resto, l’ausilio viene ancora dalla tecnologia. Sono ad esempio già disponibili delle app che alterano impercettibilmente i nostri dati somatici con un filtro ostacolando gli algoritmi di facial recognition che generalmente impiegano 6 secondi per mappare e riconoscere un volto [3]. Per non parlare, poi, degli occhiali da sole (Reflectacles block IR scan night&day) che bloccano la mappatura 3D degli scanner di riconoscimento facciale, anche se non è escluso si riesca a passare inosservati.
In generale, comunque, investire nella protezione dei dati personali rende, come dichiarano i risultati dell’edizione 2020 del data Privacy Benchmark di Cisco: il ROI della privacy vale il doppio degli investimenti, ovvero il 70% delle aziende che ha sviluppato piani sulla data protection ha ottenuto benefici pari a 2,7 volte.
Infine sul consenso si potrebbe aprire un altro vaso di pandora, con discorsi molto interessanti che vanno dal federated machine learning al trusted middleware per portare gli algoritmi ai dati e non viceversa, ai dubbi che ancora si riscontrano circa la reale comprensione da parte del consumatore: sapevate che Amazon Web Services all’art 57.10 delle proprie condizioni di servizio, cita tra le condizioni di inapplicabilità un attacco zombie?
RIFERIMENTI
[1] “Google says its latest chatbot is the most human-like ever – trained on our species’ best works: 341GB of social media”, The Register, 31 Jan 2020.
[2] Metodologia CRISP-DM, by SPSS, Teradata, Daimler AG, NCR Corporation e OHRA, 1996
[3] App Faceshield, sviluppata dai ricercatori dell’università di Toronto, manipola in modo impercettibile i nostri selfie, in modo che una volta caricati online risultino inusabili dal software di Facebook.

