
Poco più di un anno fa, l’azienda di San Francisco OpenAI – nota al mondo per aver creato il modello linguistico GPT-3 – presentò DALL-E, un sistema di intelligenza artificiale in grado di generare immagini partendo da una didascalia testuale. DALL-E (nome ispirato dall’artista Dalì e dal personaggio della Pixar WALL-E) consentiva agli utenti di esplorare il mondo dell’intelligenza artificiale in modo creativo, offrendo un affascinante scorcio sul futuro dell’arte generata attraverso l’AI. Qualche settimana fa, OpenAI ha rilasciato la versione aggiornata di questo progetto, chiamato semplicemente DALL-E 2, in grado di realizzare creazioni di qualità ancora superiore e di manipolare le immagini in modo finora mai visto da un sistema AI. Le novità di questa versione sono la capacità di eseguire modifiche selettive, la possibilità di generare immagini simili ma diverse dall’originale e la tecnologia con cui opera la rete neurale generativa.
Indice degli argomenti:
La catena di montaggio dietro DALL-E 2
Tecnicamente DALL-E 2 non è una singola rete neurale, bensì una serie di modelli AI che svolgono il loro lavoro in sequenza, come descritto dalla ricerca pubblicata dall’azienda. All’inizio vi è un modello – chiamato CLIP (Contrastive Language-Image Pre-training) – che mappa una didascalia testuale verso uno spazio di rappresentazione (una modalità di codifica per rappresentare matematicamente il testo), dopodiché un altro modello mappa questa codifica testuale assieme a una codifica visiva – un’immagine – che cattura le informazioni semantiche mappate dalla didascalia. In poche parole, il sistema usa un metodo che consente a testo e a immagine di essere statisticamente affini, in modo poi da mettere in grado il modello successivo di “disegnare” l’immagine più corretta secondo la didascalia fornita dall’utente.
Tale modello si chiama GLIDE e grazie al lavoro preparatorio di CLIP ha la capacità di generare un’immagine fedele al testo che appare nella didascalia, mostrando all’utente il contenuto desiderato. Ma non finisce qui: poiché l’immagine generata può solo avere dimensioni di 64×64 pixel, invero troppo piccola per consentire usi normali, vengono utilizzati in sequenza due modelli di upsampling – cioè la capacità di creare immagini ad alta definizione partendo da definizioni più basse – per portare l’immagine prima verso la risoluzione intermedia di 256×256 pixel, dopodiché con un nuovo passaggio verso la risoluzione finale di 1024×1024 pixel. A questo punto l’immagine generata è pronta per essere presentata all’utente. Questi passaggi si sono resi necessari poiché far generare subito da GLIDE immagini con dimensioni maggiori di 64×64 pixel avrebbe comportato un notevole aumento delle risorse computazionali necessarie.
Quello che differenzia DALL-E 2 dalla sua versione precedente è la tecnologia di generazione delle immagini, che ora si basa su un modello a diffusione.
Modelli a diffusione
Non sono nuovissimi, ma si stanno affermando sempre di più nel mondo dell’AI generativa. I modelli a diffusione creano immagini invertendo un processo di rumore gaussiano. Sul piano visivo è come guardare un’immagine che pian piano nasce da una nuvola di disturbo, simile a quello che si vedeva nei vecchi televisori.

Figura: Immagini selettivamente prese dallo studio “Denoising Diffusion Probabilistic Models” per illustrare il meccanismo. Fonte: Ho, J., Jain, A. and Abbeel, P., 2020. Denoising diffusion probabilistic models. Advances in Neural Information Processing Systems, 33, pp.6840-6851.
Di loro si è iniziato a parlare già nel 2015, con lo studio “Deep Unsupervised Learning using Nonequilibrium Thermodynamics”, ma lo studio seminale per l’affermazione di questo metodo è stato “Denoising Diffusion Probabilistic Models”, che ha dimostrato come sia possibile usare questa nuova tecnica per generare immagini di alta qualità anche migliori delle GAN (Generative Adversarial Network), le reti generative avversarie oggi usate soprattutto per generare volti digitali di persone che non esistono. La cosa, fra l’altro, viene chiaramente descritta da uno studio apposito, intitolato “Diffusion Models Beat GANs on Image Synthesis”, dove è possibile osservare numerosi esempi dove i modelli a diffusione generano risultati migliori delle GAN.
I modelli a diffusione sono ispirati dalla termodinamica, e imparano a generare le immagini attraverso un addestramento dove osservano un processo di diffusione distruggere un segnale aumentando il disturbo. Questo consente alla rete neurale di imparare a prevedere la componente di disturbo in un dato segnale (come ad esempio un’immagine), andando poi a ridurla applicando il processo inverso, dove dal disturbo nasce l’immagine.

DALL-E 2, esempi e possibilità
Come già successo per il suo predecessore, anche DALL-E 2 viene presentato assieme a diversi interessanti esempi e capacità. Per generare un’immagine è sufficiente scrivere una didascalia di quello che si vorrebbe vedere e il modello genererà alcune idee. Come questo “astronauta a cavallo”.
Oppure come queste divertenti “statue imbottigliate nel traffico dell’ora di punta”:


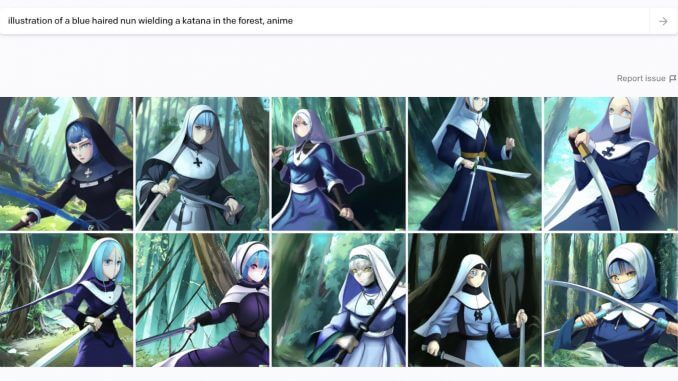
Ma volendo è possibile usare DALL-E 2 anche per creare i propri personalissimi fumetti. Un utente ha chiesto al sistema di disegnare una “illustrazione di una suora con i capelli blu mentre brandisce una katana nella foresta, in stile anime”:
Con DALL-E 2, rispetto alla versione precedente, le cose possono diventare ancora più interessanti. Il sistema, infatti, è in grado di modificare un’immagine fornita dall’utente – o anche creata dalla stessa AI – aggiungendo o modificando oggetti a piacere.
Prendiamo ad esempio questa stanza vuota, dove l’utente ha evidenziato un determinato punto (cerchiato in rosso):

Alla richiesta di inserire un divano nel punto indicato, DALL-E 2 restituisce la seguente immagine:

Inutile far notare come i casi d’uso per architetti e designer saranno innumerevoli. Ma il sistema è anche in grado di modificare con precisione una data immagine, come questa foto di un coniglio fornita da un utente:

All’utente in questione è bastato evidenziare con il mouse l’area interessata dalla modifica, in questo caso le zampe posteriori del coniglio, e scrivere “Zampe di rana”, ottenendo questo risultato:

Il sistema AI ha creato un’improbabile chimera coniglio-rana, modificando la parte posteriore dell’animale in maniera che fosse graficamente coerente con l’immagine precedente, usando la stessa tonalità di colore del pelo e generando ex-novo la parte di tappeto prima coperta dalle vere zampe del coniglio.
La possibilità di eseguire modifiche incrementali, selezionando le zone interessate e richiedendo variazioni o aggiunte, è una delle più importanti novità di questa nuova versione del sistema. Assieme alla possibilità di creare “varianti” di immagini fornite. Supponiamo, ad esempio, che ci piaccia la seguente fotografia:

Nel nostro esempio, tuttavia, la fotografia in questione è coperta da copyright e non possiamo usarla per il nostro articolo, illustrazione o brochure. È però sufficiente chiedere a DALL-E 2 di realizzare una variante, ed ecco spuntare diverse versioni:



Come si può notare sono tutte simili all’immagine precedente, ma anche tutte diverse. Il fotografo che ha catturato l’immagine originale probabilmente non riconoscerà il proprio scatto, mentre l’ipotetico autore dell’articolo o della brochure potrà usare un’immagine che comunica lo stesso stile e la stessa atmosfera di quella che voleva usare, ma con la fondata speranza di non incorrere in problemi di diritto d’autore.
DALL-E 2, casi d’uso
Come per la versione precedente, anche DALL-E 2 strizza l’occhio ai creativi, ai designer, a tutti coloro che lavorano nel mondo delle immagini. Poter descrivere un’immagine e vedersela creare in pochi minuti, con la possibilità di far effettuare all’intelligenza artificiale modifiche selettive, è il sogno di qualsiasi creativo con poche competenze di disegno grafico. Ma non saranno solo i meno talentuosi a rivolgersi alla generazione automatica delle immagini, poiché il sistema si rivelerà molto utile a velocizzare il lavoro anche di chi sa disegnare bene ma ha sempre meno tempo per farlo.
A parte la realizzazione di immagini, fotografie, quadri e fumetti, DALL-E 2 sarà utile anche ai designer di ambienti, per accondiscendere alle fantasie dei clienti, o dai clienti stessi, che potranno autonomamente e facilmente creare diverse ipotesi di arredamento per la loro casa. In futuro non è escluso che la stessa tecnologia sia usata dai creatori di videogiochi, per realizzare ambienti virtuali e oggetti digitali, e ovviamente dai designer di ambienti nel metaverso per le stesse ragioni.
Ovviamente in questi casi servirà la capacità – oggi assente in DALL-E – di generare coerentemente strutture tridimensionali e immersive, ma con i pesanti investimenti di Microsoft in OpenAI (un miliardo di dollari), nonché l’acquisizione da parte del colosso di Redmond di ZeniMax/Bethesda e l’annunciata acquisizione di Activision Blizzard, è lecito pensare che le importanti ricerche nell’AI generativa portate avanti da OpenAI possano un giorno essere messe a frutto per i videogiochi della galassia Microsoft.


