
Una parte sempre più consistente della nostra vita finisce online. Molti di questi dati vengono utilizzati per addestrare le intelligenze artificiali a svolgere compiti sempre più complessi, con la massima accuratezza possibile. Una delle sfide dei nuovi algoritmi di Machine learning è quella di garantire la privacy e la sicurezza dei dati utilizzati nella fase di training. L’obiettivo finale è quello di consentire alle AI di apprendere dei dati senza includere nel modello informazioni sensibili. L’approccio della differential privacy al problema può rappresentare una soluzione, fornendo uno strumento in grado di valutare le garanzie di privacy offerte dal sistema, nel caso di un composition attack.
Indice degli argomenti:
Il problema della privacy nel Machine learning
L’applicazione di principi di riservatezza nell’analisi statistica non è un argomento nuovo. Già nel 1977 T. Dalenius diede una definizione interessante di privacy che, tradotta in italiano, dice che la privacy è garantita quando “non viene appreso nulla di un individuo, che non possa essere appreso anche senza l’accesso al database”; di conseguenza, un analista che ha accesso al modello non dev’essere in grado di risalire a nessuna delle informazioni contenute nel dataset.
In altre parole, immaginando un sistema che analizza la correlazione tra la posizione geografica della residenza e l’insorgenza di un certo tipo di tumore, esso dovrebbe apprendere solo che i pazienti che vivono in una determinata area sono più esposti alla malattia, e non che “Mario Rossi” di “Milano” è statisticamente più esposto alla malattia.
Gli algoritmi di training non sono pensati per ignorare, per motivi di riservatezza, alcuni specifici parametri. Questo significa che c’è un notevole rischio di rivelare inavvertitamente informazioni sensibili contenute nel dataset, semplicemente pubblicando un modello di machine learning addestrato su di esso.
Nel corso del tempo sono state proposte diverse soluzioni al problema, che si sono rivelate, però, vulnerabili ai “composition attacks“. Questa tecnica viene utilizzata per violare la privacy dei dataset partendo da un modello di Machine learning, come è stato dimostrato da alcuni ricercatori nel 2009.
Il caso Netflix
Nel 2006, Netflix aveva indetto un contest per la creazione di un’intelligenza artificiale in grado di raccomandare i film migliori in base alle preferenze degli utenti. I partecipanti avevano a disposizione un DB con 100 milioni di recensioni di 500mila utenti per il training del sistema. Per garantire la privacy, il database era stato offuscato, sostituendo i nomi dei film e gli username degli utenti con dei numeri. Questa precauzione non si rivelò, però, sufficiente: due ricercatori dell’Università del Texas riuscirono a ricostruire gran parte dei dati anonimizzati utilizzando una tecnica statistica basata sui dati pubblici recuperati dall’IMDB.
L’approccio della differential privacy al problema risolve molte di queste complicazioni, fornendo uno strumento in grado di valutare le garanzie di privacy offerte dal sistema, nel caso di un composition attack. Questa tecnica può essere applicata ai dati grezzi, quindi non richiede una modifica sostanziale agli algoritmi di apprendimento già utilizzati e rende, al contempo, obsolete le classiche tecniche di offuscamento.
Cos’è la differential privacy
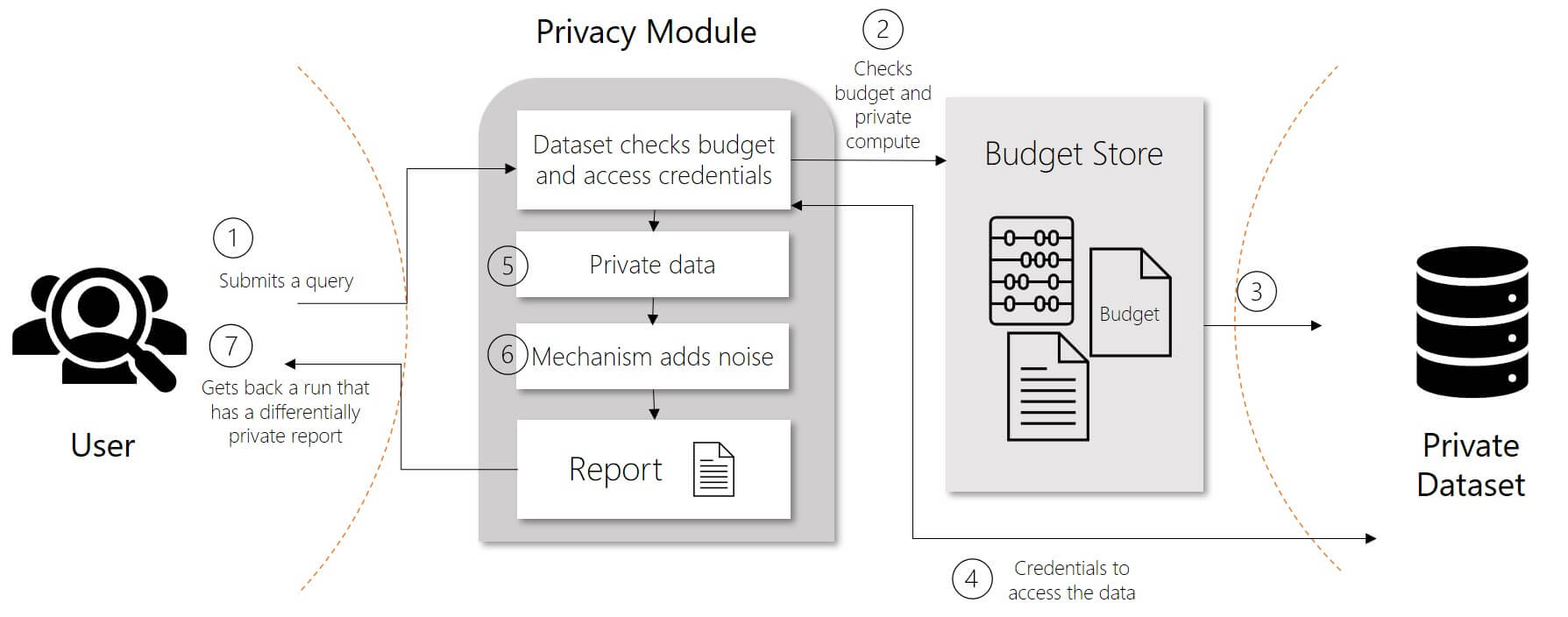
Le tecniche di differential privacy comprendono un set di procedure pensate per garantire la sicurezza e la riservatezza degli eventuali dati personali contenuti nei dataset utilizzati per il training dei sistemi di intelligenza artificiale.
L’idea di base è quella di aggiungere “rumore” ai dati, con l’introduzione, quindi, di un certo grado di entropia nel dataset, tale per cui le informazioni contenute non siano più identificabili o correlabili. Questa operazione viene ripetuta ogni volta che l’algoritmo richiede un accesso al dato per poter eseguire la fase di training.
Facciamo un esempio pratico, semplificando al massimo la base dati, per comprendere il funzionamento di questa tecnica di anonimizzazione.
Partiamo da un dataset d’esempio, che contiene le risposte di un campione formato da 5 persone a un ipotetico sondaggio. I dati sono riassunti in questa tabella:
| Nome | Età | Nazione | Risposta |
| Antonio | 31 | Italia | Sì |
| Marco | 75 | Italia | No |
| Stefano | 19 | San Marino | Sì |
| Luca | 33 | Italia | Sì |
| Giuseppe | 62 | Francia | No |
Per garantire l’anonimizzazione dei dati è necessario aggiungere, come già detto, del rumore. Questo, nel pratico, implica variare i dati introducendo una variabile casuale, che potrebbe essere il lancio di una moneta. Si stabilisce che per ogni riga del dataset viene lanciata una moneta e, nel caso in cui esca “croce”, il valore della risposta sarà alterato. Nella tabella a seguire, un’ipotesi applicata della differential privacy:
| Risultato Lancio | Nome | Età | Nazione | Risposta |
| testa | Antonio | 31 | Italia | Sì |
| testa | Marco | 75 | Italia | No |
| croce | Stefano | 19 | San Marino | No |
| testa | Luca | 33 | Italia | Sì |
| croce | Giuseppe | 62 | Francia | Sì |
L’entropia introdotta fa sì che i dati conclusivi non siano sensibili ad attacchi comparativi esterni. Il modello generato dopo il training, quindi, non potrà essere usato per ledere il diritto alla riservatezza degli individui coinvolti.
Aggiungere questo rumore di fondo significa anche diminuire l’accuratezza dei dati in uso e, quindi, dell’intelligenza artificiale addestrata su questi dati. Bisogna, dunque, trovare un giusto compromesso tra il grado di privacy ottenuto e l’accuratezza del training, calcolato attraverso un’apposita formula.
Applicazioni reali
Per applicare nella realtà i modelli di privacy differenziali vengono utilizzati diversi approcci. I più comuni sono il DP-SGD e il Model Agnostic Private Learning.
DP-SGD
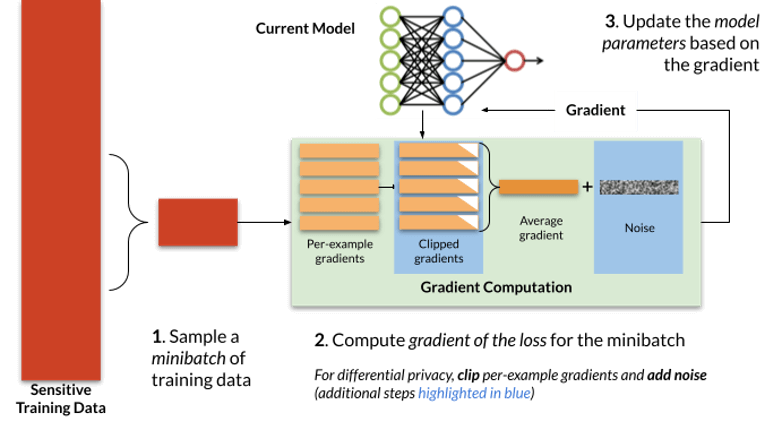
L’approccio DP-SGD (differentially private stochastic gradient descent), descritto accuratamente nel paper “Stochastic gradient descent with differentially private updates“, propone una modifica al sistema di ottimizzazione più comune nei sistemi di machine learning: il stochastic gradient descent.
In questo caso, a ogni step di training, durante la fase di ottimizzazione, viene aggiunto del rumore ai risultati. A garanzia dell’accuratezza, l’entità del rumore aggiunto viene calcolata basandosi sul numero di step necessari a completare l’addestramento. In questo modo, l’intelligenza artificiale addestrata manterrà la stessa accuratezza, pur garantendo la privacy del modello sottostante.
Model Agnostic Private Learning
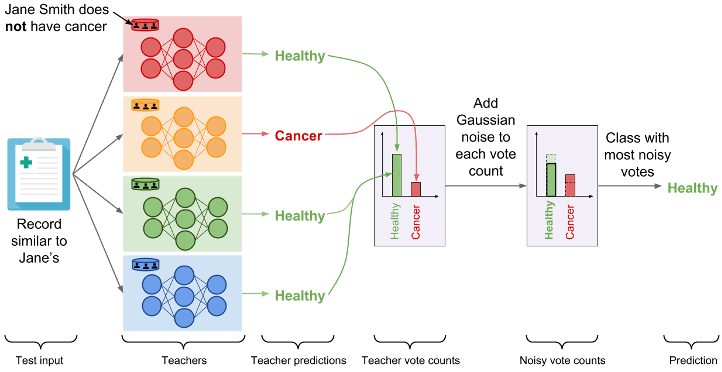
L’approccio del Model Agnostic Private Learning è molto differente da quello del DP-SGD, perché parte da un assunto opposto. L’idea di base è quella di aggiungere il rumore solo all’ultimo step della fase di training, ovvero la predizione del risultato.
Semplificando i processi, una volta che la rete neurale ha valutato tutti i parametri che servono a calcolare la predizione finale dell’AI, il sistema aggiunge del rumore variando i parametri senza modificarne i rapporti.
Privacy ed etica
Come dimostrato nell’articolo, offuscare i dati originali non è assolutamente sufficiente. I modelli per il funzionamento dei sistemi di intelligenza artificiale rappresentano, in alcuni contesti, un rischio non indifferente per la privacy degli individui coinvolti nella raccolta dati. Le soluzioni tecniche esistono e, come dimostrano gli studi, sono anche efficaci nel risolvere il problema. Purtroppo, per ragioni pratiche ed economiche, non sempre queste tecniche vengono applicate in produzione.
Ancora una volta uno degli ostacoli più grandi è la mancanza di una regolamentazione chiara e uniforme. Gli ambiti applicativi dell’AI sono sempre maggiori, ma al momento mancano dei principi etici che guidino sia il processo di addestramento che il suo utilizzo.
Conclusioni
Un’altra nota importante riguarda la raccolta indiscriminata di dati, permessa da condizioni d’uso dei servizi online troppo complesse e spesso troppo permissive. Addestrare reti neurali affidabili, in grado di assistere le persone in modo sempre più invasivo, richiede una grande quantità di dati estremamente sensibili. Se vogliamo che l’AI impari a riconoscere la nostra voce, dobbiamo farle ascoltare una grande quantità di conversazioni private. Se le grandi compagnie hanno bisogno di AI in grado di valutare il personale in maniera accurata, devono fornire quanti più dettagli possibili su queste persone. Se gli inserzionisti vogliono un’intelligenza artificiale in grado di mostrare la pubblicità giusta alla persona giusta, devono fornire informazioni complete sulle preferenze, i gusti e i desideri delle persone. Il controllo delle fasi di raccolta e trattamento di tutti questi dati è una parte fondamentale del processo di garanzia del diritto di riservatezza.



