
L’espressione umana è multiforme e complessa. Ad esempio, un oratore comunica non solo attraverso le parole, ma anche attraverso la cadenza, l’intonazione, le espressioni facciali e il linguaggio del corpo. È per questo che preferiamo tenere riunioni di lavoro di persona anziché fare chiamate in tele o video conferenza (che comunque sono preferibili rispetto alle e-mail o ai messaggi di testo). Più siamo vicini, più esiste una specie di “larghezza di banda di comunicazione”.
Il software di riconoscimento vocale è notevolmente migliorato negli ultimi anni. Questa tecnologia ora fa un ottimo lavoro nel riconoscere i suoni fonetici e nel metterli insieme per riprodurre parole e frasi pronunciate. Tuttavia, la semplice traduzione del parlato in testo non esprime al meglio il messaggio di un oratore. Espressioni facciali e linguaggio del corpo a parte, il testo è molto limitato nella sua capacità di catturare l’intento emotivo rispetto all’audio.
Inizialmente ho scelto di costruire un sensore di emozione vocale perché mi sembrava un progetto divertente e interessante su cui lavorare. Pensando di più al problema, però, mi sono reso conto che il rilevamento delle emozioni tramite riconoscimento vocale ha alcune applicazioni davvero interessanti. Immaginate se un home speaker potesse riprodurre canzoni non in base alle vostre richieste ma in virtù del fatto che riconosce il vostro stato d’animo… potrebbe proporvi canzoni che riescano a tirarvi su il morale quando siete tristi. I dipartimenti che si occupano del customer care o customer service potrebbero sfruttare il rilevamento delle emozioni tramite riconoscimento vocale per misurare se i clienti sono davvero felici e soddisfatti del servizio ricevuto durante una chiamata.
Indice degli argomenti:
Riconoscimento vocale: i dati utilizzati per classificare le emozioni
Per costruire il mio classificatore di emozioni ho utilizzato i seguenti set di dati: RAVDESS, TESS e SAVEE, tutti liberamente disponibili al pubblico (SAVEE richiede una registrazione molto semplice).
Questi set di dati contengono file audio in sette categorie comuni: neutri, felici, tristi, arrabbiati, impauriti, disgustati e sorpresi.
Combinando questi set di dati, ho avuto accesso a oltre 160 minuti di audio attraverso 4.500 file vocali già etichettati e prodotti da 30 attori e attrici. I file generalmente sono tracce vocali di attori o attrici che pronunciano una breve frase, semplice e con uno specifico intento emotivo.
Estrazione le funzionalità del riconoscimento vocale
Successivamente ho dovuto trovare funzionalità utili che potevano essere estratte dall’audio. Inizialmente ho pensato di utilizzare trasformazioni di Fourier di breve durata per estrarre informazioni sulla frequenza. Tuttavia, alcune ricerche sull’argomento hanno rivelato che le trasformazioni di Fourier sono piuttosto imperfette quando si tratta di applicazioni di riconoscimento vocale. Il motivo è che le trasformazioni di Fourier, sebbene siano un’eccellente rappresentazione fisica del suono, non rappresentano il modo in cui il suono umano percepisce.
Un modo migliore per estrarre funzionalità dall’audio è utilizzare i coefficienti cefalici in frequenza MEL o, in breve, gli MFCC (Mel Frequency Cepstral Coefficient).
Per approfondimenti e una spiegazione abbastanza utile e dettagliata di come funzionano gli MFCC la trovate nel tutorial di Practical Cryptography
Gli MFCC di fatto cercano di “rappresentare” l’audio in un modo che è meglio allineato alla percezione umana.
Per derivare gli MFCC dall’audio è necessario decidere quanti bin di frequenza utilizzare e quanto tempo di un passo temporale dobbiamo segmentare. Queste decisioni determinano la granularità dei dati MFCC in uscita. Una pratica standard per le applicazioni di riconoscimento vocale consiste nell’applicare 26 bin di frequenza tra 20Hz – 20kHz e utilizzare solo i primi 13 per la classificazione. Le informazioni più utili si trovano in intervalli di frequenza inferiori e l’inclusione di intervalli di frequenza più elevati spesso porta a prestazioni peggiori. Per le dimensioni del gradino temporale, sono comuni valori compresi tra 10 e 100 millisecondi. Personalmente, ho scelto di usare un arco temporale di 25 millisecondi.
Una volta derivati, gli MFCC possono essere tracciati su una mappa di calore e utilizzati per visualizzare l’audio. Anche se una simile mappa non rivela alcuna evidente differenza tra le categorie emotive (non tanto per la mancanza di schemi ma perché gli umani non sono addestrati a riconoscere visivamente queste sottili differenze emotive), da queste mappe di calore è abbastanza facile vedere le differenze tra altoparlanti maschili e femminili.
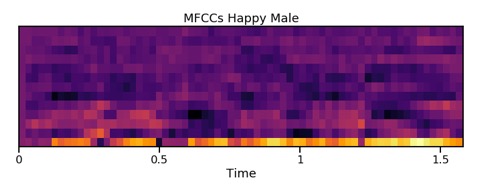
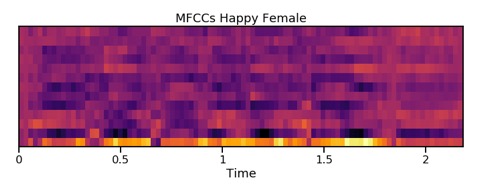
Una voce che esprime felicità, nelle donne tende ad avere componenti ad alta frequenza più forti, come mostrato dai colori più luminosi verso la parte superiore della mappa di calore.
Formazione di una rete neurale convoluzionale per il riconoscimento vocale delle emozioni
Derivando gli MFCC, i problemi di classificazione audio sono essenzialmente tradotti in problemi di riconoscimento delle immagini. Pertanto, gli strumenti, gli algoritmi e le tecniche che sono altamente efficaci nel campo del riconoscimento delle immagini sono anche molto efficaci nella classificazione audio.
Per affrontare il problema della classificazione delle emozioni, ho scelto di utilizzare una rete neurale convoluzionale (CNN, convolutional neural network) poiché si è dimostrato efficace per il riconoscimento sia dell’immagine sia dell’audio.
Prima di allenare la mia CNN, ho assegnato casualmente i file nel mio set di dati a training o set di test con una divisione 80/20. Ho quindi eseguito una serie di passaggi di pre-elaborazione sui file di allenamento.
Il processo per ogni file era:
- eliminare tutto il silenzio;
- selezionare un numero di finestre casuali 0.4s;
- determinare gli MFCC per ogni finestra, producendo 13 x 16 array;
- ridimensionare gli MFCC nell’intervallo da 0 a 1 (questo passaggio è estremamente importante! Impedisce al modello di adattarsi al livello del volume delle registrazioni audio);
- associare ogni finestra all’etichetta delle emozioni del file di origine.
Al termine della pre-elaborazione ho generato 75.000 finestre con etichetta 0.4s per la formazione, ciascuna finestra rappresentata da un array 13 × 16. Ho quindi addestrato la mia CNN su questi dati per 25 “epoche” [nell’ambito dell’intelligenza artificiale, in particolare delle reti neurali artificiali, un’epoca si riferisce a un ciclo completo di addestramento attraverso l’intero set di dati – ndr].
Test del modello
Per confrontare il modello sul set di test, ho applicato un flusso di lavoro di processo simile a quello utilizzato per creare i dati di training. Il processo per ciascun file nel set di test è stato:
- eliminare tutto il silenzio;
- creare finestre “scorrevoli” 0.4s con passo 0.1s (ad esempio, la prima finestra va da 0,0 a 0,4 secondi, la seconda da 0,1 a 0,5 secondi, ecc.);
- determinare gli MFCC per ciascuna finestra, scala su un intervallo da 0 a 1;
- classificare ciascuna finestra e restituire l’output di softmax;.
- fare previsioni aggregate per ogni finestra;
- fare la previsione finale che è la classe massima dopo l’aggregazione.
L’applicazione di questo processo a tutti gli 889 file del set di test ha prodotto un punteggio di precisione complessivo dell’83%. Dubito fortemente che sarei in grado di etichettare questi file da solo con una precisione prossima all’83%. La precisione per ogni emozione specifica è mostrata sul grafico a barre in basso.
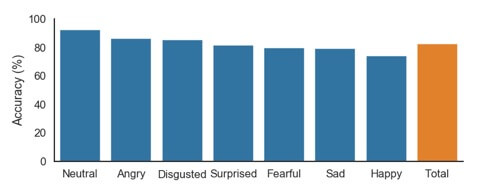
Le “lezioni apprese”
Questo articolo può far sembrare che costruire, addestrare e testare il modello sia semplice e diretto. Posso assicurarvi che non è proprio così. Prima di raggiungere una precisione dell’83%, c’erano molte versioni del modello che funzionavano abbastanza male. In una iterazione non ho ridimensionato correttamente i miei input, il che ha portato a prevedere quasi tutti i file nel set di test come “sorpresi”.
Quindi cosa ho imparato da questa esperienza?
Prima di tutto, questo progetto è stato una grande dimostrazione di come semplicemente la raccolta di più dati può migliorare notevolmente i risultati. La mia prima iterazione di successo del modello ha utilizzato solo il set di dati RAVDESS, circa 1400 file audio. La migliore precisione che ho potuto ottenere con questo solo set di dati è stata del 67%. Per ottenere una precisione dell’83%, tutto ciò che ho fatto è stato aumentare la dimensione del mio set di dati a 4500 file.
In secondo luogo, ho imparato che per la pre-elaborazione dei dati di classificazione audio è fondamentale. L’audio non elaborato e persino le trasformazioni di Fourier di breve durata sono quasi completamente inutili. Come ho imparato a mie spese, un corretto ridimensionamento può creare o distruggere un modello. La mancata rimozione del silenzio è un’altra semplice trappola. Una volta che l’audio è stato correttamente trasformato in funzionalità informative, la costruzione e la formazione di un modello di apprendimento profondo è relativamente semplice.
Per concludere, la costruzione di un modello di classificazione per il rilevamento delle emozioni vocali è stata un’esperienza stimolante ma gratificante. Nel prossimo futuro probabilmente rivisiterò questo progetto per espanderlo. Alcune cose che vorrei fare sono: testare il modello su una gamma più ampia di input, adattare il modello a una gamma più ampia di emozioni e distribuire un modello per il cloud per il rilevamento delle emozioni dal vivo.
***

*Alexander Muhr è un Data Scientist appassionato di scienza e tecnologia cui piace, come sottolinea lui stesso, tenere il passo con le nuove tecnologie. Scrive sul suo blog Data Science Odyssey da cui proviene l’articolo che ha gentilmente concesso in pubblicazione ad AI4Business
