
Le reti neurali convoluzionali (convolutional neural networks o CNN) rappresentano il tipo di architettura più utilizzato in applicazioni reali di computer vision (CV). Nell’ultimo anno e mezzo circa una nuova categoria di reti neurali, i cosiddetti Transformers, originariamente pensate per applicazioni di Natural language processing (NLP), sono state proposte anche come alternative alle CNN per problemi di CV. In questo articolo si dettagliano i motivi per cui le CNN sono soggette a problematiche di cyber security, in particolare per la loro vulnerabilità ai cosiddetti Adversarial attacks. Cerchiamo di dare una risposta alle seguenti domande:
- si può parlare di adversarial samples anche per una rete neurale di tipo Transformer?
- in caso affermativo, questi preservano la loro robustezza anche in caso di cambiamenti nelle descrizioni testuali delle classi previste per uno specifico task di classificazione?
Indice degli argomenti:
Adversarial attacks e architettura CLIP
La maggior parte delle architetture Transformer o Transformer-like che sono state proposte finora da vari gruppi di ricerca in ambito accademico o misti (università + aziende big tech) non hanno ancora applicazioni pratiche in casi d’uso reali di CV. Nonostante i risultati di tali ricerche siano riproducibili, esiste anche tutta una serie di valutazioni da considerare per poter dimostrare l’effettiva convenienza nel rimpiazzare le CNN in casi d’uso reali con una fra le tante architetture di tipo Transformer già disponibili. Questo motivo non deve comunque essere una giustificazione per evitare considerazioni relative al loro livello di sicurezza, quali ad esempio identificare se esistano vulnerabilità ad Adversarial attacks e valutare il grado di robustezza di un modello verso questi.
Le diverse architetture proposte in ambito CV presentano significative differenze strutturali che richiedono valutazioni specifiche per ogni singola famiglia di Transformer. A titolo di esempio, focalizziamoci su CLIP, proposta da OpenAI, che è una fra le poche nuove architetture per cui iniziano a vedersi le prime applicazioni pratiche in CV (talvolta anche in combinazione con altre reti neurali).
CLIP è un’architettura di tipo Transformer il cui training è stato eseguito su un dataset composto da coppie immagine-testo. Essa può essere istruita tramite linguaggio naturale a predire le frasi di testo più rilevanti rispetto a una immagine passata in input, ma senza dover fare ricorso a una ottimizzazione specifica per questo compito, in maniera simile a quanto accade per i modelli GPT-2 e GPT-3, proposti sempre da OpenAI. La figura 1 mostra l’approccio usato per CLIP:
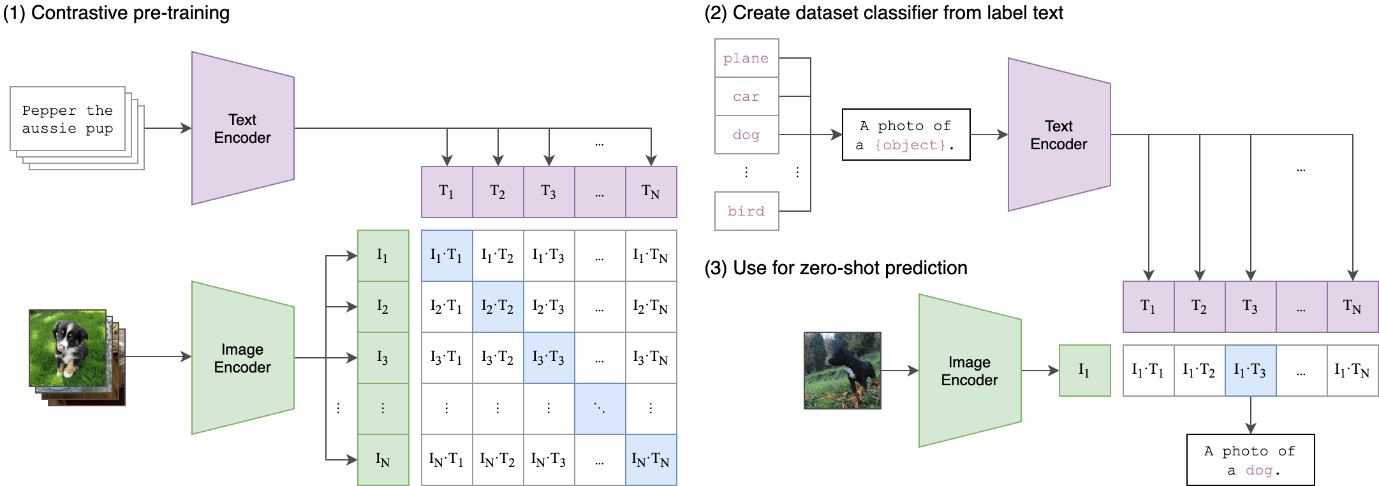
Figura 1
CLIP può essere utilizzata in casi di classificazione di immagini. A differenza delle CNN, con CLIP non è necessario preparare preliminarmente un corposo dataset di immagini già etichettate, in quanto l’approccio e di tipo one-shot classification, cioè senza alcuna necessità di training.
Adversarial Samples in CLIP
La prima cosa da fare per capire se anche per l’architettura CLIP esistono adversarial samples è definire il compito di classificazione per tale rete neurale. Partendo da un lavoro iniziale di Stanislav Fort, ho condotto dei test su due open dataset molto comuni in ambito accademico per ricerche in CV, CIFAR-10 e CIFAR-100. Per semplificare la spiegazione di questo argomento, in questo articolo farò riferimento al caso di test col dataset CIFAR-10. Questo è costituito da 60.000 immagini a colori aventi risoluzione 32×32 pixel suddivise in 10 classi (airplane, automobile, bird, cat, deer, dog, frog, horse, ship, truck). Per ciascuna classe sono disponibili 6.000 immagini, 5.000 per scopi di training di una rete neurale, 1.000 per scopi di test. Utilizzando le immagini di test di CIFAR-10 ho condotto inizialmente test e verifica delle performance di zero-shot classification con il modello di CLIP rilasciato come Open Source da OpenAI. L’accuratezza ottenuta è stata dell’88% circa.
Successivamente, generando alcuni adversarial samples semplicemente aggiungendo piccolissime perturbazioni tali da non modificarne le caratteristiche semantiche in modo che l’occhio umano riconosca ancora il soggetto originale (come spiegato nell’articolo citato precedentemente) a immagini del dataset CIFAR-10, è stato possibile dimostrare che le immagini contraffatte sono in grado di trarre in inganno il modello e fargli produrre un risultato (etichetta) diverso da quello che ci si aspettava per l’immagine in input.
Ecco un esempio (figura 2): a sinistra l’immagine originale di un aeroplano, al centro un adversarial sample generato a partire dall’immagine originaria. Come si evince dal grafico a barre sulla destra, il modello produce un risultato diverso (cat) dal soggetto visualizzato nell’immagine (airplane).

Figura 2
Stessi risultati utilizzando adversarial samples ricavati da altre immagini CIFAR-10 e con metodi di attacco iterativi diversi. Ma le brutte notizie non finiscono qui. Nei test eseguiti finora sono state prese in considerazione solo le 10 classi CIFAR-10. Provando ad arricchire il set di classi con nomi alternativi per esse, quali ad esempio jet, car, avian, kitty, moose, pup, toad, horsie, boat, lorry, e ripetendo lo stesso esercizio precedente, riotteniamo risultati simili. Nell’esempio in figura 3, a sinistra l’immagine originale di un’automobile e un adversarial sample generato a partire da essa, a destra due grafici a barre che mostrano come tale adversarial sample continui a essere robusto anche per le nuove etichette (classi) aggiunte.
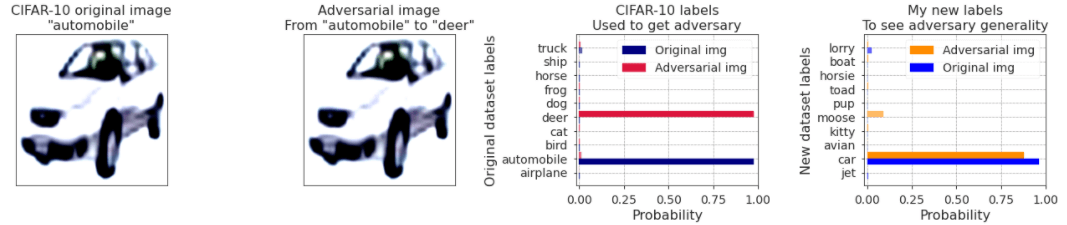
Figura 3
Le nuove etichette aggiunte per i test precedenti sono strettamente correlate a quelle originali CIFAR-10. Quindi i risultati ottenuti non dovrebbero meravigliare più di tanto, in quanto precedentemente abbiamo verificato come adversarial samples siano in grado di far fallire il modello nel caso delle 10 etichette originali. Purtroppo, passando da un set di etichette strettamente attinenti a quelle originali a uno di etichette più vagamente correlate e ripetendo lo stesso esperimento, i risultati non cambiano, anche se la robustezza degli adversarial samples in diversi casi subisce una degradazione.
Nell’esempio in figura 4 si può notare come un adversarial sample generato a partire dall’immagine di una nave (ship) ed erroneamente classificato dal modello come un aeroplano (airplane) nel caso iniziale delle etichette originali CIFAR-10, continui a essere classificato erroneamente come tale anche nel caso di etichette con descrizioni più vaghe:

Figura 4
Adversarial attacks: pixel-based contro text-based
Finora abbiamo considerato solo attacchi di tipo pixel-based. Tenendo a mente la natura di CLIP, un altro dubbio sorge spontaneo: cosa succede sovrapponendo a una immagine un pezzo di carta con del testo scritto a mano? Come intuitivamente ci si possa aspettare per questo modello, il testo sovrapposto all’immagine ha precedenza sul contenuto visuale. In figura 5 un esempio di una immagine di un aeroplano (airplane) correttamente classificata come tale da CLIP, ma successivamente classificata dallo stesso modello come rana (frog) dopo aver sovrapposto un pezzo di carta con la parola frog scritta a mano su di essa:
Figura 5
Ma cosa succederebbe se sovrapponessimo lo stesso testo a un adversarial sample invece che all’immagine originale? Chi avrebbe la precedenza tra i due attacchi, quello text-based o quello pixel-based? Per trovare la risposta a quest’ultima domanda è stato necessario ripetere lo stesso tipo di esperimenti eseguiti per il caso esaminato al paragrafo precedente. I risultati dei test mostrano che gli attacchi pixel-based per questo modello hanno quasi sempre la precedenza su quelli text-based.
Con riferimento al caso in esame in figura 5, figura 6 mostra come applicando la label frog su un adversarial sample generato a partire dall’immagine originale, l’attacco pixel-based prende il sopravvento:

Figura 6
Conclusioni
Qualsiasi modello di ML/AI che tratta dati strutturati, semi-strutturati o non strutturati di diversa natura è soggetto ad adversarial attacks. Rimanendo nello specifico di CV, qualsiasi architettura di rete neurale è potenzialmente soggetta a tali rischi e necessita di essere testata prima ancora di essere utilizzata in applicazioni reali, in particolar modo in quelle destinate a contesti sensibili e operanti in campo aperto. Le verifiche necessarie (ed eventuali strategie di mitigazione degli effetti) risultano più complesse per i Trasformer rispetto alle CNN, in quanto per i primi bisogna tenere conto di perturbazioni che possono essere aggiunte sia a contenuto visuale che testuale (o a entrambi).


