DVB-T2: la data esatta non è ancora stata fissata, ma la televisione italiana sta per mutare in modo radicale, come è già successo negli anni 2008-2011 con lo switch off dell’analogico. A cambiare, stavolta, non sarà il sistema, che resta ovviamente digitale, ma lo standard di trasmissione e, di conseguenza, il codec video. Si passerà, infatti, al DVB-T2, successore dell’attuale DVB-T, mentre lo standard internazionale di codifica video H.265/High Efficiency Video Coding (HEVC) prenderà il posto dell’attuale Mpeg4. Ciò comporterà il completo rinnovamento non soltanto degli apparati di trasmissione delle emittenti, ma anche del parco televisori in dotazione alle famiglie italiane. Sebbene la sostituzione dei televisori non più idonei alla ricezione delle nuove trasmissioni (quelli venduti prima del 2017) potrà essere evitata, volendo, tramite l’abbinamento a un decoder esterno abilitato al nuovo standard. Ecco come machine learning e deep learning sono coinvolti nel processo di codifica del segnale trasmesso.
Indice degli argomenti:
H.265 HEVC, cos’è, perché è stato scelto
Lo standard di codifica video H.265 HEVC è stato scelto per avere una efficienza di codifica (ossia di compressione) superiore a quella degli standard precedenti. Uno dei fattori per una maggiore efficienza è la previsione intra picture che ha un gran numero di direzioni di previsione (35 modalità) rispetto agli standard precedenti. Questa elevata efficienza è resa possibile da un compromesso tra elevata complessità degli encoder. Lo svantaggio principale è la distorsione del tasso inclusivo (RD rate distortion). Il fatto rilevante è che il processo di codifica utilizza il Deep learning e le reti neurali convoluzionali (CNN) per prevedere la modalità migliore per avere la minore distorsione della velocità (RD), ottenendo l’ottimizzazione completa della distorsione della velocità (RDO rate distortion optimization) nel processo di codifica del segnale.

H.265 HEVC, come nasce e a cosa serve
La codifica video (compressione e decompressione) viene utilizzata per elaborare i segnali video in modo da ridurre la larghezza di banda e la memoria richiesta senza compromettere la qualità delle immagini. Basic Video Codec HEVC H.265, la recente tecnica di codifica video, è stata standardizzata dal Joint Collaborative Team on Video Coding (JCT-VC), ITU-Telecommunication (ITU-T), Video Coding Experts Group (VCEG) e ISO/IEC MPEG nel gennaio 2013.
Ha una vasta gamma di applicazioni nel settore dello streaming video per servizi come il caricamento e il download di video su Internet, canali di streaming live, applicazioni di videoconferenza e sistemi di trasmissione terrestre, video, videocamere, reti mobili, applicazioni di sicurezza. Lo standard di codifica video precedente il progetto HEVC era H.264/MPEG-4 AVC, standardizzato nel 2003 e ha mostrato un miglioramento significativo in diverse applicazioni cruciali dal 2003 al 2009. H.264 / AVC è stata una tecnologia di codifica video potenziante per il video digitale in tutti i possibili domini che l’H.262 / MPEG-2 non poteva conquistare.
L’obiettivo principale di HEVC/H.265 è aumentare gradualmente le prestazioni di compressione rispetto agli standard precedenti e ridurre il bit rate del 50% per la stessa qualità video percettiva. HEVC ha molte caratteristiche aggiuntive rispetto agli standard precedenti. Simile a H.264, H.265 si basa su un approccio di codifica ibrido che è una combinazione di previsione inter-immagine, previsione intra-immagine, filtri in-loop (Filtro di sblocco (DF) e Sample Adaptive Offset SDO), codifica di trasformazione. HEVC ha 35 modalità (la modalità DC:( modalità 1), 33 modalità angolari:(mode2-34) e la modalità planare:( modalità 0)) rispetto ad AVC che ha 9 modalità. A causa di questo elevato aumento delle modalità, l’ottimizzazione della distorsione della velocità (RDO) diventa la principale complessità. Per ovviare a questo, occorre aggirare la complessità di ottimizzazione RD per la decisione sulla modalità di previsione intra picture.
Le modalità intra prediction possono essere formulate come categorizzazione con diverse classi di modalità in cui il machine learning si propone come soluzione. Utilizzando il Deep learning in cui la rete neurale convoluzionale fornisce la soluzione nell’identificare la modalità migliore con meno distorsione del tasso che porta ad aumentare l’efficienza video riducendo il bit rate e mantenendo la stessa qualità video.
Ecco una panoramica dei codificatori video che distribuiscono tecniche deep learning, basati su classificatori di reti neurali convoluzionali nel processo di codifica. Per mezzo di questo processo di codifica CNN, si evita la complessità RDO.

Evoluzione dei coding video
MPEG-1
- Standardizzato nel 1993
- Supporta video progressivi
- Supporta la risoluzione YUV 4: 2: 0 352 * 288
MPEG-2
- Standardizzato nel 1995
- Supporta video su televisori a definizione standard
- Divide il segnale video in due o più bit codificati con risoluzioni diverse.
MPEG-4
- Standardizzato nel 1999
- Supporta applicazioni multimediali a basso bit rate in piattaforma mobile e internet
- Supporta la codifica di video e audio, compresa l’animazione
H.261
- Standardizzato nel 1988
- Sviluppato per conferenze su ISDN
- Utilizza la codifica ibrida basata su blocchi con compensazione del movimento dell’immagine
H.262
- Standardizzato come MPEG-2 part-2 nel 1995
- Gestisce entrambi i formati YUV 4:2:0 e 4:2:2
- Supporta immagini scansionate progressivamente e interlacciate
- Altre caratteristiche includono partizionamento dei dati, quantizzazione su linea
H.263
- Standardizzato nel 1996 e H.263+ è stato standardizzato nel 1998
- La qualità è migliorata rispetto all’H.261 a bit rate inferiore per abilitare la telefonia e il video
H.264 (AVC)
- Standardizzato nel 2003
- Supporta video su tv HD, dispositivi mobili, internet
- Migliore qualità dell’immagine a bit rate bassi
- DF in-loop per ridurre le discontinuità dei blocchi
H.265/HEVC
- Standardizzato nel 2013
- Supporta la qualità video fino a risoluzione 8k
- Ricca flessibilità nella previsione
- Riduzione del 50% in più di bit rate rispetto all’AVC
Come funziona il codec H.265 HEVC
H.265 HEVC è un approccio di codifica ibrido con previsione intra picture, previsione inter picture e trasformazione 2D nel livello di codifica video. L’algoritmo di codifica procede come segue: ogni immagine è divisa in regioni a forma di blocco chiamate Coding Tree Units (CTU). I CTU, unità di base della codifica, sono simili ai blocchi macro utilizzati nei precedenti standard di codifica video (AVC / H.264). L’algoritmo è ulteriormente suddiviso in regioni chiamate Coding Units (CU). HEVC supporta due tipi di previsioni
• Intra: dove ogni unità viene stimata dai dati dell’immagine adiacente all’interno dell’immagine corrente.
• Inter: utilizza i dati delle immagini di altre immagini di riferimento. Il primo fotogramma nella sequenza video viene utilizzato con la previsione intra-immagine in quanto non ci sono altri fotogrammi da confrontare (fotogrammi di riferimento), le altre immagini di una sequenza o tra punti casuali sono previste utilizzando modalità di codifica predittiva tra immagini. Il processo di codifica per la previsione tra immagini consiste nella scelta dei dati di movimento che comprendono l’immagine di riferimento selezionata e il vettore di movimento (MV) da applicare per prevedere i campioni di ciascun blocco. All’encoder viene assegnata una sequenza di fotogrammi come input in cui ogni fotogramma è segmentato come struttura Quad-tree e ogni segmento viene alimentato all’encoder uno per uno per decidere se il blocco è compresso come P-frame o I-frame. Utilizzando la decisione di modalità e il vettore di movimento, la previsione dell’immagine identica viene generata dal codificatore e dal decodificatore che applica MC.
In H.265, il frame dell’immagine a blocchi originale viene sottratto dal frame dell’immagine del blocco di previsione o dal frame di riferimento per ottenere la differenza tra i fotogrammi. Questo blocco risultante è chiamato blocco immagine di errore o blocco immagine residua. Questo blocco residuo di intra/inter viene trasformato dalla trasformazione spaziale. Questi coefficienti di trasformazione residua passano attraverso il ridimensionamento, la quantizzazione e vengono inviati insieme alle informazioni di previsione. Il codificatore replica il ciclo di elaborazione del decodificatore in modo tale che entrambi generino previsioni identiche per i dati imminenti. Successivamente, i coefficienti di trasformazione quantizzati vengono ricostruiti mediante ridimensionamento e trasformazione inversa per duplicare l’approssimazione decodificata del segnale decodificato. Viene aggiunto sia il blocco dell’immagine di errore che il blocco previsto e questo viene alimentato ai filtri in-loop per rimuovere gli artefatti ottenuti a causa della quantizzazione. Il buffer di immagine decodificata memorizzerà l’immagine finale che aiuta per la previsione tra immagini a confrontare il blocco previsto con le immagini di riferimento.
Come il machine learning può trovare falle nella previsione intra picture
La previsione intra è uno strumento molto complesso. L’aumento del numero di modalità aumenta il sovraccarico di segnalazione nel flusso di bit. Selezionare la modalità migliore con meno RD utilizzando tecniche manuali è un compito difficile e richiede tempo e questo può essere superato utilizzando tecniche di apprendimento automatico.
L’encoder HEVC dovrebbe selezionare le migliori modalità di previsione intra picture utilizzando la previsione UDI che supporta 35 modalità, tra cui due modalità non direzionali e 33 modalità angolari (direzionali). La modalità eminent viene selezionata scegliendo la modalità minima risultante dal processo RDO. Al fine di ridurre al minimo il tempo computazionale dell’encoder, utilizziamo l’algoritmo di previsione intra-immagine accelerata basato su machine learning.
H.265 HEVC: approcci machine learning
Algoritmo di clustering K-medoide
Utilizza un criterio di liquidazione anticipata basato sulle statistiche dei costi di Hadamard. Raggruppiamo le modalità di previsione intra-immagine in K-cluster utilizzando questo algoritmo di apprendimento automatico K-medoid. Il centro dei cluster è preso come candidato per il processo di ottimizzazione della distorsione della velocità (RDO). Questo algoritmo K-medoid utilizza il metodo di previsione dell’intervallo di profondità per trovare tutte le correlazioni tra le unità di codifica vicine (CU). Per scoprire se la codifica è divisa facciamo uso di HSAD e dei costi RD delle unità di codifica codificate. Nella fase finale, questo algoritmo K-medoid seleziona la modalità di previsione intra (IPM) che ha una precisione inferiore in RMD e in base alla correlazione tra unità di codifica vicine (CU), RDO è ridotto per gli IPM. Un algoritmo di gradiente in HEVC viene utilizzato per ridurre la complessità computazionale mantenendo la stessa qualità video.
Algoritmo Random Forest
Come sappiamo l’HEVC ha 35 modalità di previsione intra e quindi aumenta il tempo computazionale di codifica. Questa complessità di codifica può essere ridotta al minimo se le parti del decodificatore possono prevedere automaticamente dal codificatore del video HD originale. Vediamo la previsione delle CCU in CU addestrando i recenti 10 frame di nuovi visualizzati utilizzando questo algoritmo. Questo algoritmo di foresta casuale crea un classificatore da N “trees” decisionali. Ogni albero ha sottoinsiemi per ogni funzionalità di input. Per identificare l’etichetta di output del nuovo campione fornito come input, la probabilità di scissione dei campioni viene restituita da ciascun albero nella foresta. Viene considerata la media delle probabilità e se la media è superiore al 50% CU viene suddivisa
Algoritmo K-NN
Questo algoritmo utilizza una strategia di ricerca che mostra un forte impatto sulla qualità del predittore. Questo viene utilizzato come rappresentazione di ricerca del modello come combinazione sequenziale di modelli K-NN (modelli K) presi da SW. K il vicino più vicino viene trovato calcolando la distanza tra il blocco candidato nei fotogrammi di riferimento e il modello del blocco corrente. Diversi approcci si basano su K-NN, poiché è esplorato su inter frame e intra frame come la fattorizzazione della matrice non negativa o la rappresentazione sparsa. Questo viene utilizzato principalmente per le unità di previsione, in particolare le unità di grandi dimensioni, in modo da fornisce una migliore ottimizzazione RD. Questo metodo è anche altamente parallelizzabile e può ridurre il tempo computazionale.
H.265 HEVC e Deep Learning
Il deep learning, una nuova tecnica nell’ambito dell’apprendimento automatico, aiuta a ridurre la complessità in H.265 HEVC. Le funzionalità di partizionamento CU possono essere automaticamente previste o estratte dal deep learning piuttosto che utilizzando tecniche manuali. Il vantaggio di utilizzare l’approccio di deep learning in HEVC per ridurre la complessità è che può prendere dati su larga scala come vantaggio per estrarre automaticamente un ampio partizionamento correlato a CU. Considerando la selezione della modalità nell’HEVC come un problema di classificazione, questo approccio può fornire una soluzione efficace nel decidere la modalità migliore con meno RD. Per risultati superiori nei problemi di classificazione viene utilizzata una rete neurale convoluzionale profonda.
H.265 HEVC e rete neurale convoluzionale (CNN)
Il vantaggio della CNN è che durante la back-propagation la rete deve regolare un numero di parametri pari a una singola istanza del kernel che riduce le connessioni dalle tipiche reti neurali. Al fine di affrontare il problema del blocco degli artefatti risultanti dalla previsione inter o intra picture wise block, dal ridimensionamento e dalla quantizzazione delle trasformazioni, viene utilizzata una rete neurale convoluzionale profonda che si avvicina alla funzione inversa della codifica video. CNN è calcolabile indipendentemente da qualsiasi decisione dell’encoder precedente e dai valori del campione ricostruiti. Rimuovendo l’accoppiamento comune indesiderato tra le decisioni del codificatore dal processo di codifica effettivo, tutte le decisioni vengono eseguite contemporaneamente per tutti i blocchi e quindi non è richiesta alcuna latenza aggiuntiva.
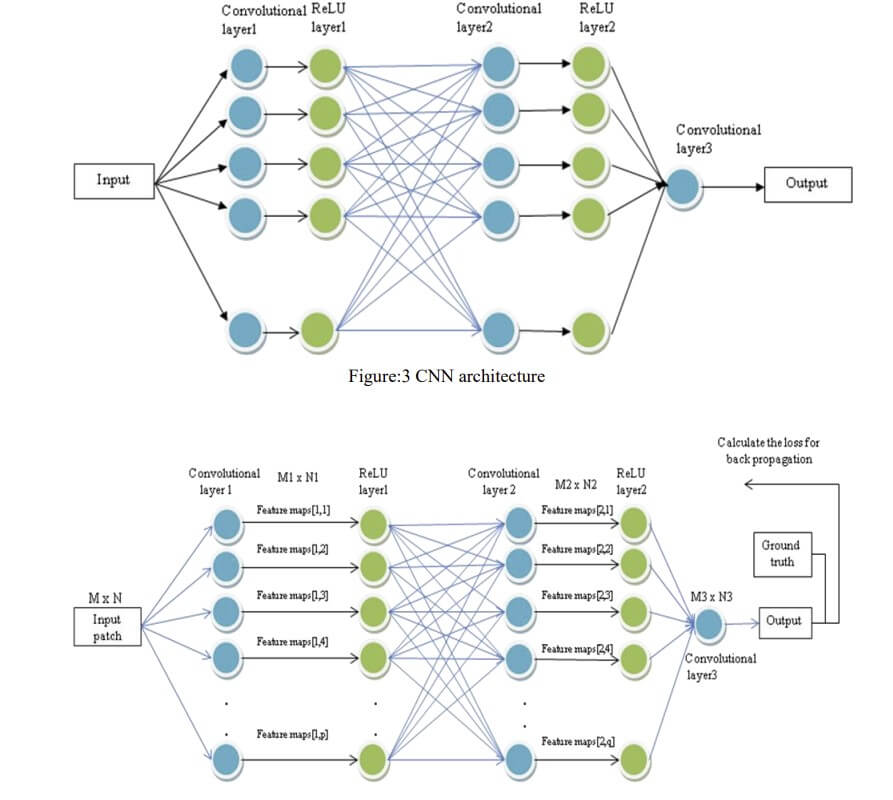
In un primo momento, la CNN del classificatore viene alimentata con campioni di ingresso originali, consentendo così di essere indipendente dalla decisione degli encoder o dai campioni ricostruiti dell’encoder. Ciò evita anche ritardi nell’elaborazione. Su un luma e due componenti chroma di ciascun CTU, i componenti luma contengono informazioni importanti rispetto ai componenti chroma, solo i componenti luma vengono utilizzati per l’elaborazione.
Come accennato in precedenza, il motivo principale dell’introduzione della CNN qui è quello di risolvere il problema della classificazione considerando ciascuna delle 35 diverse modalità di previsione intra predictions come classi diverse. Ogni campione di input verrà fatto passare attraverso tre livelli tra cui un pooling massimo e due livelli convoluzionali che aiutano a filtrare i dati. L’unità lineare rettifica è usata per attivare i neuroni. Alla fine, i dati passano attraverso i due livelli completamente connessi e l’output viene recuperato.
Riferimenti
- Deep Learning Techniques in HEVC, Besiahgari Dinesh, Kavya B, Dr. Mohammed Riyaz Ahmed – International Journal of Advance Research in Science and Engineering.




