
Attualmente tutti i riflettori dei media in ambito AI sono puntati verso ChatGPT, il modello conversazionale avanzato implementato da OpenAI e in fase di adozione/acquisizione da parte di Microsoft e verso la corsa che tale evento ha scatenato e che sta costringendo Alphabet ad accelerare il rilascio del rivale Bard AI. Tutto questo clamore della stampa (specializzata e non) attorno a ChatGPT rischia di far passare in secondo piano altre applicazioni di AI per le quali, a differenza di quest’ultimo, sembrano già esserci dei casi di business più definiti e fattibili nel breve o medio termine. Tra questi, tanto per restare nello stesso tipo di applicazioni, rientra sicuramente BioGPT. Vediamo cos’è e in quale dominio specifico si può applicare.
Indice degli argomenti:
Modelli linguistici generativi in ambito biomedico
L’uso di tecniche come il text mining e l’estrazione di informazioni dalla letteratura biomedica si è dimostrato cruciale nello sviluppo di nuovi farmaci, terapie cliniche, ricerca patologica, etc. Un numero sempre crescente di pubblicazioni biomediche viene rilasciato quotidianamente per via dei continui progressi scientifici in tale campo: da qui la costante necessità di trarre informazioni significative da questo materiale abbondante. I ricercatori biomedici hanno manifestato molto interesse nei confronti dei modelli linguistici basati su deep learning/AI che sono risultati efficaci nel dominio generale del linguaggio naturale.
Tuttavia, le prestazioni di tali modelli, dopo primi tentativi di applicazione diretta nell’area biomedica, non sono state ritenute affidabili, in quanto essi eccellono in vari compiti basilari, ma la loro gamma di applicazioni alla fine risulta limitata perché ad essi manca la capacità di generalizzare. Da qui la necessità di addestrarli specificamente su testi biomedici, partendo dai due rami principali dei modelli linguistici pre-addestrati nel dominio linguistico generale: GPT e BERT (e le loro varianti ovviamente).
Bert
Dei due, BERT è quello che precedentemente ha ricevuto la massima attenzione in campo biomedico. Tra i modelli più noti, BioBERT[1] e PubMedBERT[2] sono quelli che hanno conseguito prestazioni superiori rispetto ad altri. Mentre i modelli BERT-based in generale sono più adatti a compiti di comprensione, i modelli GPT-based si sono dimostrati più adatti a task di generazione, ma le prestazioni di questi ultimi nell’area biomedica erano ancora tutte da dimostrare.
BioGPT, 15 milioni di abstract da PubMed
In risposta a questo problema, i ricercatori Microsoft hanno recentemente introdotto BioGPT, un modello di linguaggio generativo di tipo Transformer pre-addestrato su un’ampia letteratura biomedica. Il training set è costituito da un corpus di 15 milioni di abstract disponibili in PubMed[3], un portale web aperto a tutti che consente di eseguire ricerche principalmente sul database online MEDLINE, il quale contiene riferimenti e abstract relativi ad argomenti di ricerca in ambito biomedico. I ricercatori di BioGPT hanno incluso sei task, tra i quali la risposta a domande, la categorizzazione di documenti e l’estrazione di relazioni end-to-end. Secondo diverse valutazioni sperimentali, BioGPT è risultato essere significativamente superiore ai modelli di base alternativi nella maggior parte delle task per cui è stato addestrato.
BioGPT, la base è GPT-2
Per l’addestramento di un modello linguistico, disporre di un set di dati di alta qualità è estremamente cruciale: cosa che i ricercatori Microsoft hanno tenuto in considerazione per BioGPT, da cui la loro decisione di utilizzare i dati di testo nel dominio di PubMed. Il modello di base da cui sono partiti è stato GPT-2, essenzialmente un decoder Transformer.
Il paper di BioGPT è stato pubblicato a novembre 2022 e di recente (tra la fine di gennaio e l’inizio di febbraio 2023), anche il relativo codice sorgente e alcuni modelli pre-addestrati sono stati rilasciati da Microsoft.
Come accennato nel precedente paragrafo, i tre task più importanti per cui BioGTP è stato addestrato e in cui eccelle rispetto ad altre iniziative simili sono i seguenti:
- Relation Extraction – Predizione di attributi e relazioni fra le entità di un testo. Nei casi in esame per BioGPT, questo è un singolo task e non, come per altre tecniche di deep learning precedenti, una catena di sub-task. Questo task è il più importante fra tutti nell’ambito della ricerca biomedica.
- Question Answering – La capacità di rispondere a domande in un determinato contesto. Comprensione di testi quindi.
- Document Classification – La capacità di classificare un dato documento come appartenente a categorie predefinite (che possono essere identificate tramite una o più etichette).
I risultati del test
Da notare che per tutti e tre i task sopra indicati qui si parla di generazione e non di predizione, incluso il caso della classificazione di documenti. I risultati dei test del gruppo di ricerca sono stati particolarmente significativi per questo tipo di modelli in questo specifico dominio: parliamo di uno F1 score del 44,98%, 38,42% e 40,76% rispettivamente su tre diversi test set per quanto riguarda task di estrazione di relazioni end-to-end e di una accuratezza media del 78,2% con il modello “light” su dati PubMedQA per il task di domande e risposte (81% con il modello “large”):
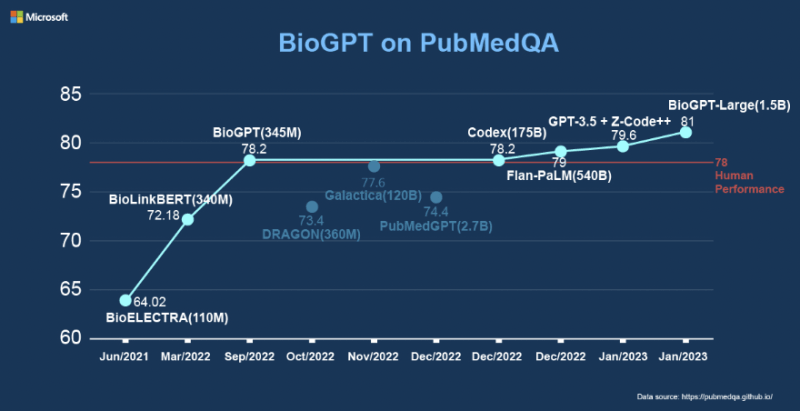
Come si può notare dal grafico in figura, BioGPT è il modello più performante nel task di domanda-risposta sul data set PubMedQA, ma non è stato l’unico tentativo di utilizzo di un modello linguistico nel dominio biomedico a partire dal 2021 ad oggi: ulteriore conferma della necessità reale di questo tipo di soluzioni.
Così come per la maggior parte dei modelli generativi che lavorano con testo o combinazioni di testo e immagini, anche per BioGPT il formato del prompt incide sulla qualità dei risultati. Di seguito alcuni esempi del modello in azione.
BioGPT, esempi
Generazione di testo a partire da un concetto biomedico (la parte in nero in figura è l’input per il modello, mentre quella in blu è la parte generata da BioGPT) tramite il modello “light” e limite di lunghezza testo generato impostato molto basso (testo da generare molto corto):

Stesso caso d’uso del precedente, fornendo lo stesso input, ma incrementando il limite massimo della lunghezza del testo generato dal modello (testo da generare di media lunghezza):

Question Answering con il modello “large” (l’input deve essere specificato nel formato question: context: answer: target: la risposta che ci si aspetta in base al contesto dato), che fornisce come risposta yes, no o maybe:
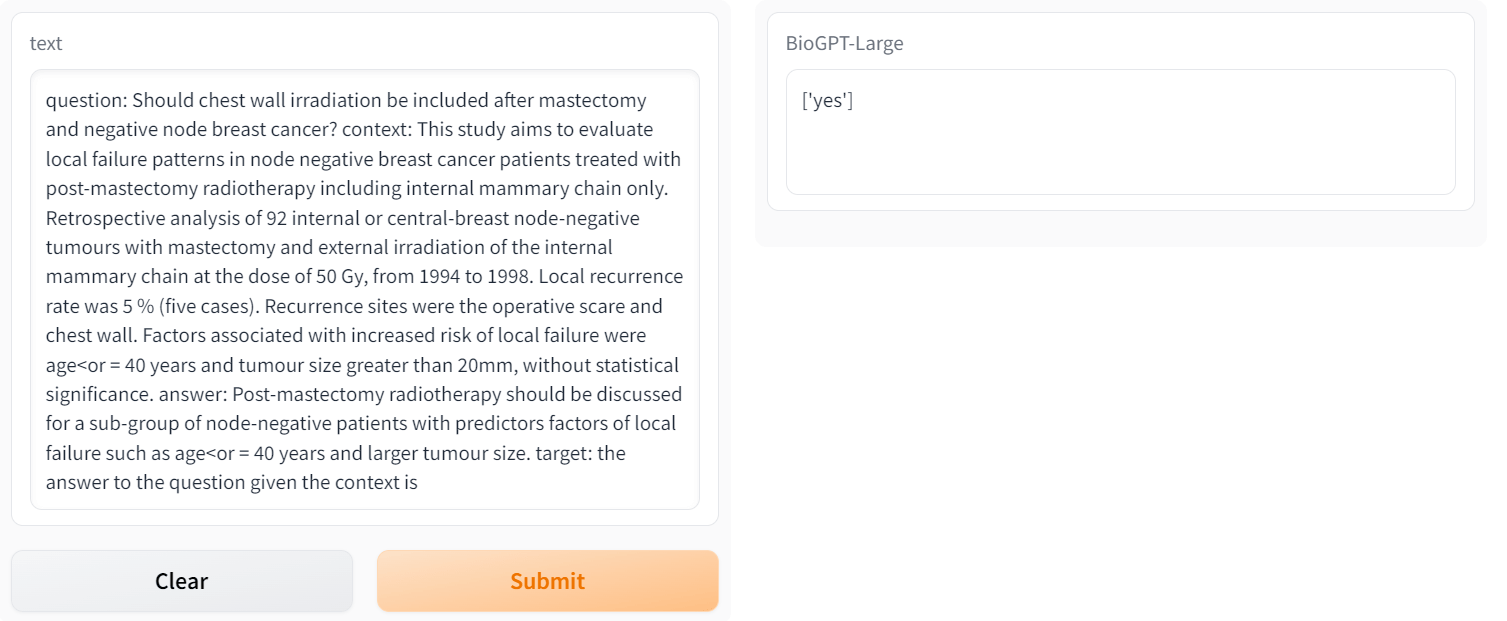
Altro esempio di Question Answering tramite modello “large” e utilizzando lo stesso formato di input dell’esempio precedente, ma senza suggerire alcuna risposta aspettata (la parte in nero in figura è l’input per il modello, mentre quella in blu è la risposta generata da BioGPT):

L’uso di BioGPT in maniera efficace richiede all’utente una preparazione biomedica, in quanto è stato pensato come uno strumento di ausilio per professionisti del settore per semplificare le loro attività di ricerca, senza richiedere alcuna conoscenza tecnica di DL/IA. Sconsiglio caldamente i non addetti ai lavori riguardo l’utilizzo di questo tool per terapie self-service o per la generazione di contenuti biomedici che potrebbero potenzialmente contribuire a creare disinformazione.
Conclusioni
Nonostante modelli generativi in ambito linguistico in grado di affrontare una conversazione con umani a livello generale potranno in futuro rendere più smart diversi task e creare nuove applicazioni pratiche/opportunità di business, la strada da percorrere è ancora molto lunga e piena di rischi. Inoltre, si corre il pericolo di trascurare nel frattempo altri casi d’uso più impellenti per i quali una soluzione simile, ma in un dominio specifico esiste già e si presta a poter essere raffinata con meno difficoltà e costi rispetto a una soluzione generalista.
Senza contare il fatto che essendo un modello pensato per un dominio specifico, le risorse computazionali richieste non saranno mai esose come nel caso di un modello generalista, rendendolo quindi non appannaggio esclusivo di corporazioni Big Tech. BioGPT ne è un esempio per il dominio biomedico (ma sono già disponibili anche modelli specifici in altri domini quali ad esempio la generazione di software in diversi linguaggi di programmazione, tanto per citarne uno).
Dalle prime valutazioni del modello, effettivamente esso sembra mantenere le promesse ed è possibile replicare i risultati del relativo paper. Importante anche il notevole livello di trasparenza di BioGPT: grazie alla indicazione (e disponibilità) dei dati con cui è stato eseguito l’addestramento e il rilascio dei codici sorgente, la verifica di diversi requisiti che ogni modello di AI dovrebbe avere, quali la presenza di eventuali bias, security checks e attività di explanability risultano facilitate.
Note
- https://arxiv.org/abs/1901.08746 ↑
- https://arxiv.org/pdf/2007.15779.pdf ↑
- https://pubmed.ncbi.nlm.nih.gov/ ↑




