
Classificare e comprendere immagini complesse senza intervento umano è uno step fondamentale per consentire alle AI di comprendere meglio il mondo e, quindi, di aiutare le persone in task sempre più articolati. Gli scienziati del Computer Science and Artificial Intelligence Laboratory del MIT CSAIL, guidati da Mark Hamilton, hanno da poco pubblicato un paper e un software in grado di migliorare l’efficacia dei sistemi di apprendimento automatico per la computer vision. Gli scienziati del MIT, con il progetto STEGO (Self-supervised Transformer with Energy-based Graph Optimization), sono stati in grado di sviluppare una tecnica di segmentazione non supervisionata efficace, vale a dire un modello che non ha bisogno di apporto umano durante la fase di training. Il software è stato rilasciato con licenza MIT (Open Source) e i risultati ottenuti con uno dei dataset più usati per la ricerca sono molto promettenti, superando in accuratezza i precedenti modelli all’avanguardia.
Indice degli argomenti:
STEGO: cos’è e come funziona
Il progetto STEGO (Self-supervised Transformer with Energy-based Graph Optimization) consiste quindi in una tecnica di segmentazione non supervisionata efficace, che non ha bisogno di apporto umano durante la fase di training. La rete neurale di STEGO è in grado di assegnare un’etichetta a ogni pixel che compone un’immagine. In questo modo è possibile suddividere un’immagine nei suoi componenti principali, distinguendo oggetti, cose e persone rappresentate dallo sfondo. Questa fase di clustering è molto importante nelle applicazioni pratiche della computer vision, perché gli algoritmi di riconoscimento e manipolazione delle immagini tendono a funzionare molto meglio su cluster di pixel già identificati come appartenenti a un unico oggetto.
Alla base di STEGO c’è DINO, un algoritmo che utilizza un enorme dataset, composto da 14 milioni di immagini (ImageNet), per imparare a conoscere il mondo e gli oggetti che lo compongono. La nuova tecnica ingegnerizzata dai ricercatori del MIT è un perfezionamento concettuale di DINO, che migliora il processo che porta la rete neurale ad assegnare un significato specifico a ogni pixel. Questi miglioramenti consentono a STEGO di interpretare in maniera coerente il contesto, comprendendo come gli oggetti della scena e lo sfondo si relazionano tra loro. E tutto questo senza la necessità di un intervento umano per classificare le immagini usate per il training.
Evitare l’intervento umano non è solo un fattore che diminuisce i tempi e i costi dell’analisi: i risultati ottenuti da algoritmi non supervisionati sono meno soggetti ai bias presenti nei dataset con etichette. Inoltre, all’esperto umano potrebbero sfuggire informazioni e dettagli che invece STEGO sarebbe in grado di cogliere.
STEGO: come cambia la computer vision
La segmentazione di STEGO è stata testata con successo in ambiti applicativi molto differenti tra loro, e il sistema è stato in grado di rilevare e segmentare gli oggetti rappresentati nell’immagine. I test hanno previsto la segmentazione di immagini provenienti da sensori montati su auto a guida autonoma, fotografie aeree ad alta quota e anche fotografie di scenari appositamente creati per valutare la consistenza del risultato fornito dall’AI.
Per quanto riguarda l’applicazione nella guida autonoma, STEGO rappresenta un passo avanti considerevole nel differenziare persone, strade ed edifici con grande precisione. La risoluzione dei contorni ottenuti con questo algoritmo risulta molto più elevata rispetto a quanto visto fino ad ora. Questo miglioramento comporta dei passi avanti nella sicurezza degli occupanti del veicolo, così come nella sicurezza dei pedoni.
Anche l’analisi delle immagini aeree può avere risvolti pratici decisamente interessanti. Al momento, STEGO è uno dei sistemi più robusti per scomporre le immagini tracciando i bordi di strade, edifici e vegetazione. Utilizzando questa AI su immagini satellitari è possibile creare mappe accurate e statistiche aggiornate, senza nessun intervento umano. Hamilton e la sua squadra puntano a un processo scientifico e accurato per la scoperta e il raggruppamento di oggetti e delle loro istanze all’interno di un’immagine. Raggiungere questo obiettivo significherebbe avere un potente strumento autonomo da utilizzare in quelle situazioni dove non è possibile, per fattori pratici o tecnici, un lavoro di etichettatura effettuato da un esperto di settore. Applicazioni di questo tipo hanno il potenziale per rivoluzionare ambiti come l’astrofisica o la biologia.
Il futuro di questa tecnologia
Tanti risultati, ma anche diverse sfide da affrontare. Un primo problema è rappresentato dalla differenziazione di oggetti appartenenti a classi arbitrarie concettualmente molto vicine. In questo caso la capacità di distinzione del sistema non è ancora sufficiente. Inoltre, il sistema manca ancora di una flessibilità tale da diventare più resistente a “hack” della rete neurale, cioè a immagini anomale pensate per confondere il sistema di clustering.

Nei progetti dei ricercatori c’è una nuova versione di STEGO che sia più robusta e che consenta di assegnare etichette multiple in contemporanea allo stesso oggetto, per aggiungere un layer di astrazione al “modo di pensare” dell’intelligenza artificiale.
Un game-changer nella computer vision
“Decisamente STEGO ha tutti i requisiti per diventare un game-changer in applicazioni di computer vision. La fase di etichettatura dei dati per l’apprendimento di modelli per task visuali non solo, come già spiegato nell’articolo, ha costi non indifferenti, ma presenta delle difficoltà anche nel reperimento di personale specializzato in determinati contesti applicativi. Nonostante siano reperibili sul mercato diverse aziende che, oltre ad offrire piattaforme cloud-based per l’etichettatura di dati (incluse immagini), dispongono di personale dedicato per eseguire tale lavoro conto terzi, difficilmente queste possono offrire supporto in contesti quali manufacturing, diagnostica per immagini, biologia, che richiedono una preparazione (ed esperienza) che solo chi ci lavora quotidianamente ha. In teoria STEGO potrebbe essere una soluzione a questo problema: sarà però interessante vedere come e se questa architettura manterrà le promesse al momento dell’applicazione in casi reali in uno dei domini sopra citati (leggendo la ricerca sembra di intuire che i dataset utilizzati in fase di sperimentazione e implementazione fossero composti da immagini appartenenti a domini generali). Ovviamente, nonostante questo approccio sia di tipo non supervisionato, sarà importante non escludere dal processo di etichettatura l’intervento di esseri umani: STEGO dovrà essere usato con l’intento di ridurre drasticamente i tempi di etichettatura su grossi volumi di immagini e compensare la mancanza di forza lavoro specializzata e necessaria per tale attività (andando così a ridurne i costi), etichettare situazioni difficili da valutare per un essere umano o generare alert in caso di ambiguità, ma un processo di revisione da parte di operatori specializzati dovrà in ogni caso essere impostato a valle.”
Guglielmo Iozzia – Associate Director – ML/AI, Computer vision
AI per guardare il mondo
Ridurre al minimo gli errori commessi dai sistemi di visione artificiale è diventata una necessità sempre più impellente. Tante tecnologie in piena fase evolutiva come, ad esempio, le auto a guida autonoma o i modelli diagnostici AI-Powered che iniziano a essere applicati in ambito medico, richiedono algoritmi e tecniche di computer vision capaci di comprendere e contestualizzare le immagini ricevute dai sensori di visione. Anche i sistemi IoT più comuni, come le videocamere smart, iniziano ad agganciare allarmi e automatismi alla computer vision.
Addestrare le AI per la computer vision, però, non è un compito facile. Per ottenere un grado di accuratezza accettabile bisogna dare in pasto alle reti neurali una notevole quantità di dati etichettati, vale a dire immagini elaborate da una persona che ha già riconosciuto gli elementi contenuti e li ha contrassegnati. L’effort per generare questi dataset, in molti casi, ha un costo spropositato. Esistono persino eccezioni per le quali non è possibile creare dataset etichettati perché gli stessi esperti in materia non hanno parametri per riconoscere e assegnare un significato alle componenti dell’immagine.
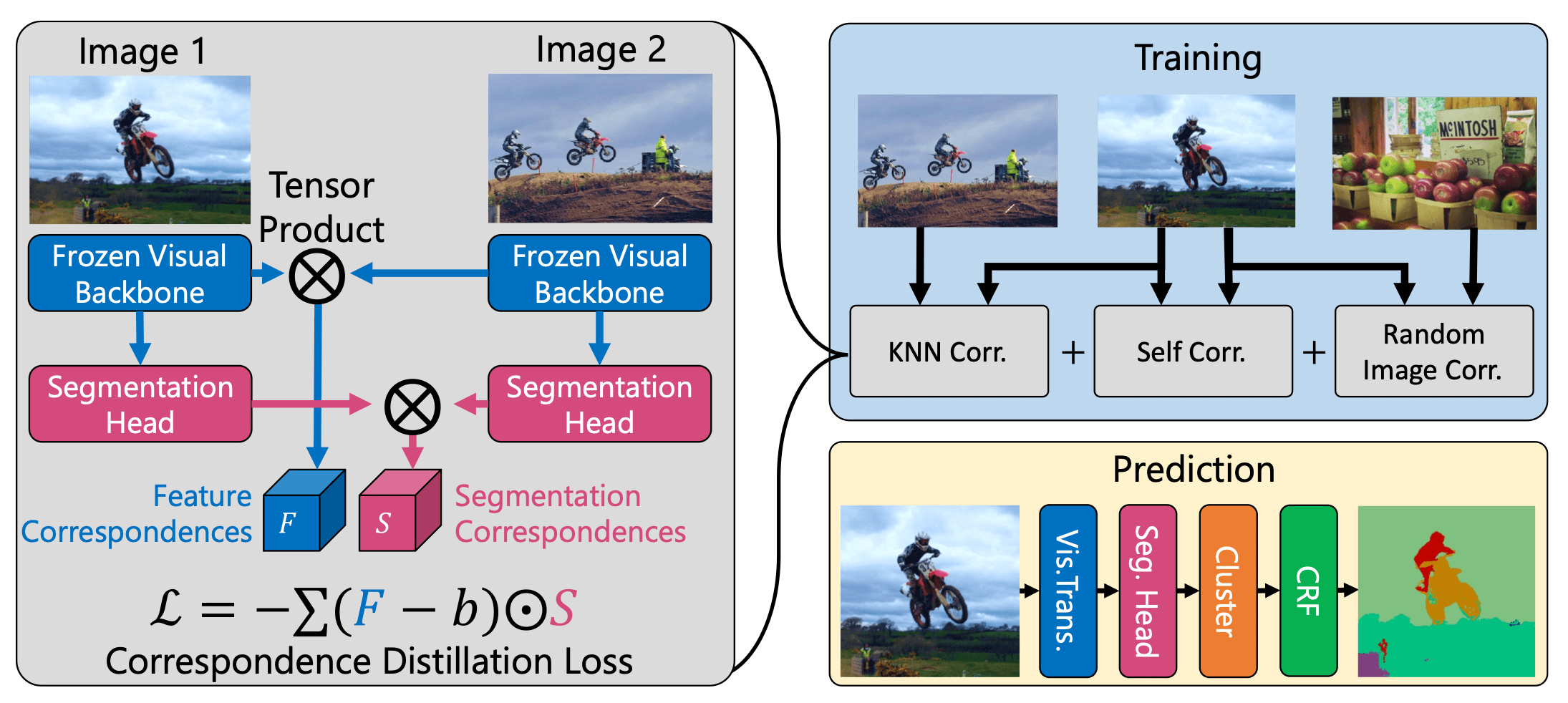
Image Segmentation, cos’è
L’Image Segmentation è una tecnica di Computer Vision che consente di partizionare un’immagine raggruppando pixel adiacenti in gruppi coerenti. Esistono tre differenti approcci all’Image Segmentation: la segmentazione semantica consente di rilevare “classi” di oggetti, separandoli dallo sfondo; l’instance segmentation, invece, riguarda la classificazione delle istanze di un oggetto presenti nell’immagine; la segmentazione panottica, infine, è una combinazione delle prime due, in grado di catalogare diverse classi e diverse istanze della stessa classe.



