
Il web semantico ha rappresentato la vera evoluzione per Internet e ha consentito a tutti gli utenti di usufruire dei contenuti online in modo molto più diretto, connesso e immediato. L’idea, nata nel 2001, rappresenta ancora oggi una grande sfida. Ecco una disamina della storia del web semantico e della sua struttura.
Indice degli argomenti:
Cos’è il web semantico o semantic web
Con il termine web semantico si indica l’insieme di tutti i servizi e delle strutture digitali che consentono di interpretare e rendere interrogabili, mediante l’utilizzo di motori di ricerca e di sistemi di elaborazione automatica, i contenuti presenti nel web.
In poche parole, si tratta della trasformazione che ha consentito al World Wide Web di diventare l’ambiente che oggi conosciamo, nel quale muoversi mediante l’analisi dei contenuti, che risultano collegati da una serie di parole chiave o di indicazioni che consentono la maggiore reperibilità del contenuto.
Prima del web semantico, infatti, non era possibile per i sistemi informatici interpretare i contenuti delle pagine visitate: Internet si presentava ai propri utenti come un ambiente nel quale i diversi testi erano collegati tra loro da link.
Grazie a un’idea di Tim Berners Lee, avanzata nel 2001, è invece stato possibile rendere quello stesso sistema un ambiente vivo, maggiormente navigabile e interpretabile, mediante la creazione di una serie di sistemi standardizzati che consentono di fare delle correlazioni dirette fra i contenuti e di guidare l’utente nella navigazione, mostrando le informazioni cercate e contenuti coerenti con le stesse, e di svolgere compiti per conto dello stesso. I documenti pubblicati, infatti, vengono associati a una serie di informazioni e di dati (metadati) che ne specificano il contesto semantico in un formato adatto all’interrogazione e all’interpretazione, permettendo ricerche molto più evolute, differenti dal semplice collegamento ipertestuale, fondate sulla presenza, all’interno del documento, di parole chiave o di altri elementi di connessione.
La creazione del web semantico ha costituito la risposta alla necessità di adattare la crescita esponenziale dei contenuti e di informazioni presenti sul web, estremamente eterogenee fra loro, al bisogno dell’utente di ricercare contenuti che siano coerenti con i propri interessi, evitando di disperderne le energie.
Come nasce la semantica del web?

Come anticipato, il web semantico nasce da un’idea di Tim Berners Lee, il fondatore dello stesso World Wide Web, che aveva quale obiettivo quello di migliorare il rapporto tra l’utente e le macchine, favorendo la fruizione dei contenuti presenti sul web.
Alla base vi era un problema: uniformare il linguaggio con il quale le interrogazioni degli utenti e le risposte della macchina venivano svolte. A tal scopo sono stati creati i primi standard di linguaggio, come RDF (Resource Description Framework), che creavano delle relazioni tra le informazioni ispirandosi alla logica dei predicati. In poche parole, le informazioni venivano espresse mediante c.d. asserzioni (o statement) costituite tra tre elementi: soggetto, predicato e valore. Questi tre elementi venivano identificati univocamente dalla macchina, portando a una ricerca molto più selettiva dei contenuti, che non poneva in risalto quei siti che non contenevano almeno uno di questi tre elementi.
Al linguaggio RDF si associa, poi, N3 (Notation 3), che permette di collocare ogni asserzione anche su un’unica linea, contrassegnando ognuna delle stesse con un punto. I sistemi basati sulla logica predicativa, tuttavia, erano viziati da una serie di problematiche: non solo erano particolarmente complessi, ma non erano computabili, potendo esprimere solo una porzione molto ristretta di asserzioni.
A questi primi strumenti di linguaggio, fa seguito il c.d. metodo sintetico o delle ontologie, basato su logiche di tipo descrittivo, che consentivano di includere molte più informazioni. Il cambiamento è stato necessario per permettere agli utenti di effettuare ricerche più complesse e intelligenti rispetto a quanto fatto sino ad allora. Grazie a questi standard, è possibile creare nuovi costrutti e relazioni, tra cui:
- l’equivalenza tra risorse, che permette a due URI (sequenze di caratteri che identificano universalmente e univocamente una risorsa) di rappresentare un medesimo elemento;
- la relazione inversa, che permette di associare a una serie di asserzioni altre asserzioni opposte a queste: se è vero (soggetto, predicato, oggetto), allora è anche vero (oggetto, predicato inverso, soggetto).
Come funziona il web semantico
Sulla scorta di quanto sinora esposto, è possibile stabilire che il web semantico funziona mediante la creazione di connessioni, di relazioni tra le parole e gli elementi identificativi dei contenuti presenti sul web.
Più nel dettaglio, il web semantico consente di codificare le informazioni presenti in uno specifico dominio di conoscenza mediante delle ontologie, articolando per classi una serie di concetti, relazioni e regole, di modo tale che la macchina che interagisce con i contenuti sia in grado di interpretare le informazioni che vede e di restituirle correttamente all’utente, coerentemente agli input inseriti dallo stesso.
Senza le ontologie, e gli standard di interpretazione dei contenuti, sarebbe per l’utente molto più complesso, se non impossibile (dato l’ormai elevatissimo numero di contenuti presenti sul web) riuscire a individuare dei contenuti che risultano effettivamente utili.
Come indicato da Massimo Marchiori, dell’Università “Ca’ Foscari” di Venezia, “da un lato, ci siamo noi umani, che mettiamo informazione sul Web. Per farlo, usiamo essenzialmente la lingua che ci è più congeniale. Morale: per noi è facilissimo mettere informazione sul Web (e questo spiega l’enorme diffusione che il Web ha avuto in così poco tempo). Dall’altro lato, ci sono le macchine, che a differenza nostra, non capiscono quasi nulla di quello che noi scriviamo. Morale: cercano di districarsi come possono, con i risultati mediocri che abbiamo sotto gli occhi. Il Web Semantico cerca di ribaltare questa incomprensione di fondo”.
Ne consegue che gli algoritmi di ricerca, al fine di poter essere efficaci, devono essere caratterizzati da almeno tre elementi fondamentali:
- organizzazione della conoscenza: permette di identificare e mettere in relazione fra loro i diversi elementi che possono essere utili alla ricerca;
- rappresentazione della conoscenza: permette di descrivere i diversi dati identificati;
- strumentazione per accedere alla conoscenza: permette, mediante una serie di programmi, di comprendere, leggere e operare sulle rappresentazioni reperite in rete.
Ad oggi, l’elemento su cui si lavora maggiormente è proprio l’accesso alla conoscenza: il perfezionamento della strumentazione utilizzata dall’utente per interagire con il web e i suoi contenuti consentirà, infatti, una precisione sempre maggiore nell’esecuzione delle richieste degli utenti. Tale risultato sarà probabilmente raggiunto mediante l’ausilio di strumenti di intelligenza artificiale, atti a individuare anche le necessità alla base di una determinata ricerca.
La struttura del semantic web
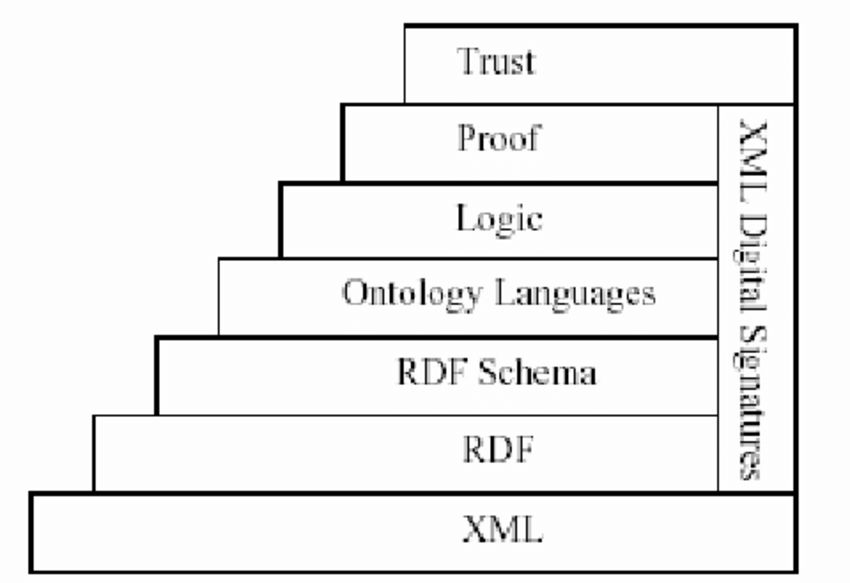
La struttura del semantic web può essere riassunta mediante uno schema piramidale, denominato Semantic Web Tower e disegnato proprio da Tim Berners Lee.
La piramide consente di comprendere la complessità dei vari linguaggi del web, partendo da concetti base come l’URI fino ad arrivare alle ontologie e alla logica.
Alla base, infatti, si collocano linguaggi come l’HTML, in grado di descrivere ogni elemento del documento preso in esame, di riconoscere un titolo o un attributo, mediante dei tag, ma non di capire, ad esempio, qual è il nome di un oggetto, collegandolo al prezzo al quale lo stesso viene venduto.
Più in alto nella piramide vengono linguaggi più complessi, come RDF, OWL e XML, che sono nati per servire gli scopi del web semantico e riescono, quindi, a descrivere le varie relazioni che corrono tra le diverse informazioni presenti in rete (ad esempio, se il sig. Mario Rossi viene citato in un documento, questi linguaggi saranno in grado di capire se quello specifico Mario Rossi è lo stesso soggetto che svolge un determinato lavoro e che viene citato in un altro documento online).
Semantic Web Tower
Il web semantico si pone, dunque, come una struttura composta da diverse stratificazioni e particolarmente complessa, suddivisa in tre raggruppamenti principali, a loro volta composti da più strati, che possono variare in base alle diverse necessità che si intende raggiungere:
- strato di base (URI/IRI): costituisce l’insieme degli elementi di base, come l’URL, che permettono di identificate un sito web;
- core semantico (XML(S), Namespace, RDF(S), OWL, SPARQL, RIF): costituisce la parte centrale della struttura del web semantico, e quella maggiormente soggetta a mutamenti, aggiornamenti e variazioni. Più nel dettaglio, il core costituisce l’insieme dei linguaggi che consentono di descrivere delle informazioni, oltre che di strutturare dei metadati che ne consentano l’identificazione. Il linguaggio XML, in particolare, consente di creare dei modelli di dati e di attribuire agli stessi specifici significati, dando vita alla semantica, sviluppata nei linguaggi derivati come RDF (Resource Description Framework) o OWL (Ontology Web Language);
- strato finale: si tratta di strutture in via di sviluppo, definite Unifying Logic, Proof e Trust. Questi tre elementi, in particolare, costituiscono il raggruppamento principale e più importante del web semantico, la base sulla quale potranno essere sviluppate delle intelligenze artificiali che consentano di perfezionare la ricerca dei contenuti del web anche sulla base del contesto nel quale li si sta cercando. In particolare, al livello Trust si affida il compito di suddividere le informazioni rilevate dalla macchina in base all’affidabilità delle stesse, ovvero in base alla reale corrispondenza tra quanto digitato dall’utente e quanto trovato dalla macchina; il livello Proof effettua delle prove per confermare l’affidabilità dei dati, sulla scorta di una serie di deduzioni logiche fornite dal livello Unifying Logic.
È evidente, dunque, come lo strato finale possa essere raggiunto esclusivamente mediante l’implementazione di intelligenze artificiali che interpretino i contenuti presenti sul web in modo “smart”, creando dei collegamenti di contesto che superano l’attuale sistema di ricerca cui siamo abituati, arrivando a generare dei risultati sempre più precisi e coerenti con le nostre necessità.
Le ontologie del web semantico
Le ontologie costituiscono la vera svolta del web semantico, rappresentando delle strutture di metadati costituite da specifici concetti e dalle relazioni tra gli stessi; in poche parole, si tratta di descrizioni create mediante le relazioni tra i diversi significati delle asserzioni utilizzate per descrivere i dati.
Le ontologie (termine mutuato dalla filosofia) sono costruite a partire da categorizzazioni del mondo reale, allo scopo di formalizzare e modellare le caratteristiche semantiche essenziali di un dominio di conoscenza. Le ontologie possono essere molto utili per strutturare e definire il significato dei metadati e dei termini usati: uno stesso significato, tuttavia, può essere utilizzato in contesti differenti, creando delle sovrapposizioni.
Possono essere usate anche per fornire delle annotazioni di tipo semantico su elementi non testuali come immagini, audio, video e altro. Questo tipo di elementi possono essere indicizzati mediante ontologie multimediali che associano una determinata informazione aggiuntiva al dominio, migliorandone il recupero.
Per creare il modello di un dominio occorre avere tre elementi:
- Information feeds: che tipo di contenuti esistono o saranno resi disponibili, e che tipo di informazione, formato e altre caratteristiche hanno i contenuti;
- User needs: le motivazioni per cui gli utenti vogliono il contenuto e quali caratteristiche dello stesso sono rilevanti;
- Intended use: quali caratteristiche sono necessarie nella produzione, nel recupero e nell’uso dei contenuti.
In base alla tipologia di contenuto reso, potrebbe essere necessario aggiornare le ontologie: i siti che pubblicano news, ad esempio, sono soggetti a maggior dinamismo, mentre i domini maggiormente scientifici, con elementi definiti, sono maggiormente statici, con minor mutamento delle ontologie.
Grazie alle ontologie, è possibile migliorare e perfezionare le applicazioni web, come i portali, siti che consentono di interagire ad alti livelli con il contenuto informativo, di ricevere news, costruire comunità, reperire dei link ad altre risorse di interesse comune.
I collegamenti tra i concetti, infatti, creati mediante la strutturazione di ontologie, vanno a costituire la vera e propria rete semantica, consentendo a siti differenti di avere un medesimo obiettivo, senza che la definizione associata a un determinato elemento sia resa in maniera statica. Un esempio classico di come funzionano le ontologie e la rete semantica è la possibilità di unire differenti informazioni provenienti da fonti diverse come elenchi telefonici, calendari, home page, ecc.
Web semantico: esempi
L’esempio più classico del web semantico sono gli OPAC, applicativi che consentono di navigare all’interno del catalogo dei sistemi bibliotecari, fra loro interoperabili. I sistemi OPAC consentono all’utente di accedere ai cataloghi e di confrontarli fra loro mediante il circuito delle Biblioteche Nazionali.
Un esempio è anche Tal to Books, una funzione di ricerca di Google che, mediante l’intelligenza artificiale applicata al web semantico permette di rispondere alle domande dell’utente restituendo citazioni letterarie estratte da un catalogo di oltre centomila libri diversi. In questo caso, la comprensione del linguaggio umano si associa alla restituzione di risultati “intelligenti”, come se si fosse in una vera conversazione.
Gianroberto Casaleggio spiega il web semantico
Il futuro del web semantico
Come detto, sono stati fatti molti passi avanti nella creazione di un web di tipo semantico, basato sulla definizione di schemi (o ontologie) e standard. A quanto fatto sinora, in futuro, allo scopo di raggiungere lo strato finale dello schema piramidale semantico, non potrà che aggiungersi un sistema di intelligenza artificiale, che consenta a una macchina non soltanto di acquisire le informazioni e di ricercare risultati coerenti, ma anche di correlare i risultati al contesto in cui opera (context-aware).
In tal modo, l’interazione fra l’uomo e la macchina sarà maggiore, e sarà altresì possibile definire delle regole logiche di estrazione della conoscenza, in modo differente rispetto a quanto fatto sinora.



