
I problemi di Reinforcement learning (apprendimento con rinforzo) sono caratterizzati da due elementi fondamentali: un ambiente e un agente. L’agente si trova in uno stato tra quelli presenti nell’ambiente e a ogni istante temporale compie un’azione. L’ambiente risponde fornendo un nuovo stato e una ricompensa (positiva o negativa). L’azione viene decisa da un algoritmo che ha lo scopo di trovare il comportamento ottimo, (o politica ottima) ovvero le azioni da eseguire su ogni stato per ottenere la massima ricompensa. La sequenza di coppie stato-azione descritta dall’agente che interagisce con l’ambiente si chiama traiettoria. Dato uno stato e un’azione la ricompensa legata a questi non sarà necessariamente sempre la stessa (in termini tecnici, si dice che la ricompensa – o reward – è stocastica). Alcune coppie stato-azione potrebbero ad esempio avere una ricompensa bassa ma sempre molto vicina a un certo valore, mentre altre coppie potrebbero avere ricompense più alte ma più variabili che alcune volte potrebbero essere anche molto basse. Questo concetto sarà molto utile quando parleremo del concetto di rischio. È possibile adattare il framework di RL a un semplice contesto di trading.
Per comprendere a pieno questo articolo è necessario conoscere alcuni aspetti fondamentali del RL, aspetti che chiariremo di seguito. Tuttavia, consigliamo a chi per la prima volta si imbatte nel termine Reinforcement Learning la lettura del seguente articolo introduttivo https://www.ai4business.it/intelligenza-artificiale/reinforcement-learning-cose-significato-ed-esempi/.
Indice degli argomenti:
Il RL nel trading
Abbiamo già detto che è possibile adattare il framework di RL a un contesto di trading. Come esempio, è sufficiente pensare a uno scambio tra un bene liquido (denaro) e un bene non liquido (ad esempio un’azione). Lo stato dell’ambiente è rappresentato da cosa è presente nel portafoglio in quell’istante di tempo (quantità di denaro e del bene), il valore del bene all’istante presente e nei 60 istanti (minuti) precedenti. Al contempo, Le possibili azioni consistono nel comprare e vendere diverse quantità di bene. Infine, la ricompensa è pari a quanto viene guadagnato o perso in termini di valore del portafoglio tra un istante di tempo e l’altro. In questo modo, nella fase di addestramento (training), l’agente potrà apprendere come il prezzo si sposterà nel futuro, basandosi sui 60 minuti precedenti. L’agente proverà ad apprendere una politica che decida quando comprare e quando vendere in modo da massimizzare i profitti ottenuti durante il trading.

La scelta dello stato
Nell’applicare RL al trading finanziario la scelta dello stato influenza grandemente quelle che saranno le prestazioni dell’agente. Si può, ad esempio, decidere di includere valori come medie mobili o altri indici utili. Nell’esempio riportato, viene usato il prezzo istantaneo (o di chiusura) degli ultimi 60 minuti; tuttavia, è possibile utilizzare altri dati per lo stato. Ad esempio, possiamo diminuire o aumentare gli istanti di tempo. Avere meno istanti di tempo nello stato significa dare meno informazioni sul passato all’agente, ma significa anche avere uno spazio degli stati più ridotto che può significativamente aiutare nel processo di apprendimento in quanto il problema sarà, di conseguenza, più semplice. Inoltre, possiamo arricchire i dati aggiungendo, oltre al prezzo di chiusura, anche il prezzo massimo e minimo durante l’ultimo minuto trascorso. Si possono persino includere informazioni provenienti da articoli e analisi di mercato che possono influenzare il prezzo delle azioni. In questo problema, come in molti altri, la scelta dello stato è cruciale, e a seconda della scelta gli algoritmi che potremo scegliere varieranno.
Il Deep RL
In un problema di trading finanziario, spesso capita di avere numerosi stati che possono essere rilevanti al fine di apprendere una politica che porti a buoni guadagni. Come abbiamo appena visto lo stato dell’ambiente raggiunge facilmente da varie decine ad anche alcune centinaia di valori, il che può mettere in difficoltà gli algoritmi tradizionali. In questi casi, alcuni degli algoritmi più adatti utilizzano reti neurali profonde (deep) da cui il nome Deep RL.
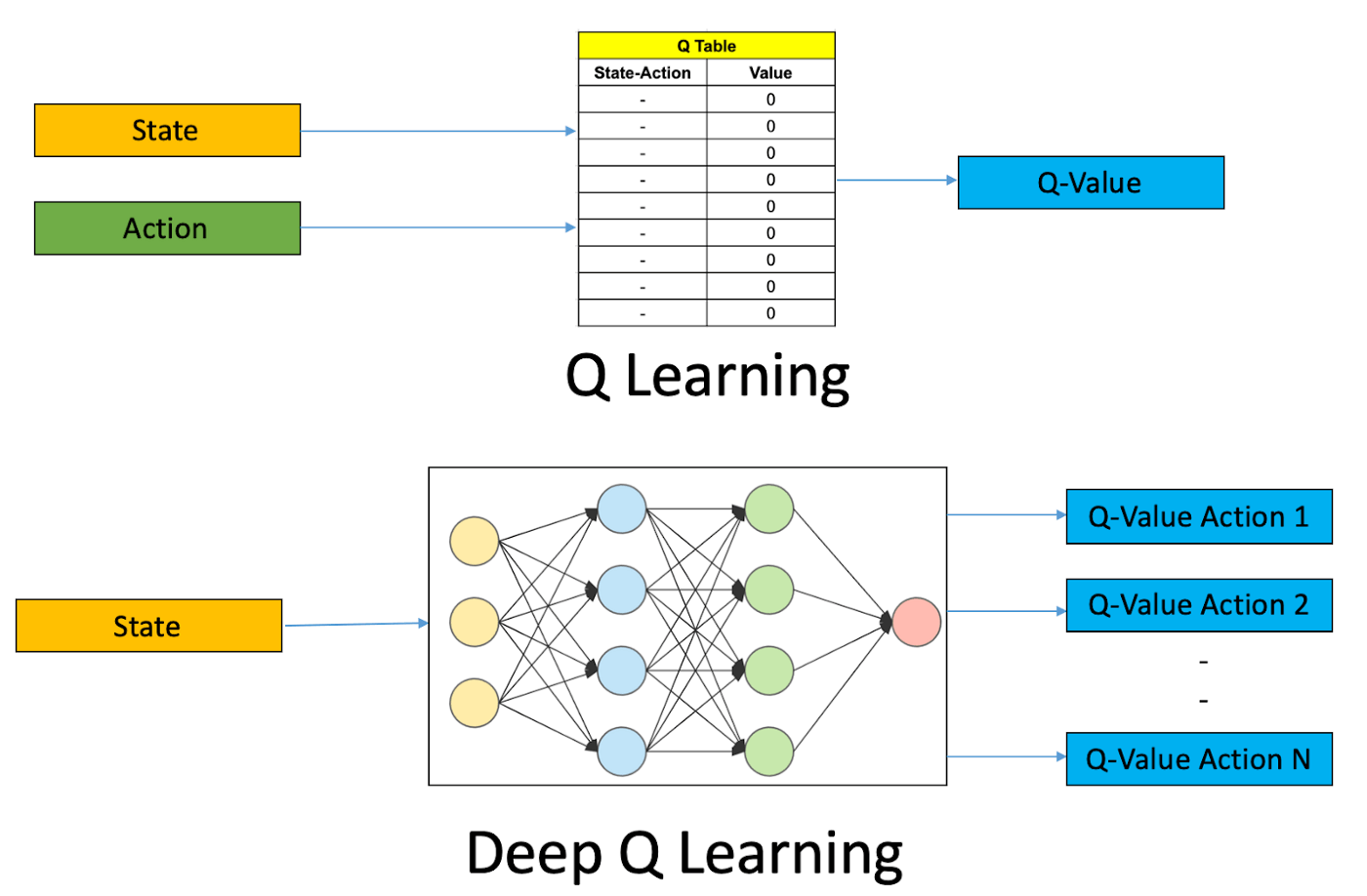
Uno degli approcci usato da alcuni algoritmi di RL classico si basa sull’utilizzo di una tabella che salva, per ogni coppia di stato azione, un possibile valore (denominato Q-Value) che indica la qualità di quell’azione in quello specifico stato, ovvero una stima della ricompensa che si otterrà se si sceglie quell’azione e poi si continua con una certa politica. Quando gli stati e le azioni sono troppo numerosi, l’utilizzo di una tabella è proibitivo in quanto sarebbe troppo grande per essere salvata e diventerebbe impossibile avere abbastanza dati per avere stime ragionevoli per ogni coppia stato-azione. Il Deep RL propone come soluzione l’utilizzo di reti neurali per sostituire la tabella di stime. Le reti neurali sono infatti stimatori: l’idea è quella di addestrarle sui dati limitati che abbiamo, e lasciare che esse generalizzino (diano risposte ragionevoli) anche quando chiederemo stime per coppie stato-azione sulle quali non sono state addestrate.
RL avverso al rischio nel trading
Un’altra criticità nell’applicare RL al trading è che l’agente cercherà di massimizzare la somma delle ricompense lungo le traiettorie, ovvero il guadagno, senza preoccuparsi dell’incertezza legata alle azioni ottime che vengono apprese. Nel contesto del trading finanziario è spesso auspicabile avere un algoritmo che garantisca una certa stabilità dell’investimento, senza rischiare di perdere grandi quantità di denaro nel tentativo di massimizzare i guadagni a tutti i costi. Risk Averse RL è una branca della letteratura scientifica avente come scopo quello di creare algoritmi che consentano l’apprendimento di politiche in grado non solo di massimizzare la somma delle ricompense, ma che evitino di scegliere azioni o sequenze di azioni che potrebbero portare a gravi perdite. In altre parole, una politica avversa al rischio sacrificherà parte della ricompensa per scegliere azioni che diano una ricompensa più bassa ma più certa, ovvero con varianza più bassa.
Dato un insieme di numeri, la varianza è un valore che indica quanto questi siano in media lontani dalla loro media. Esempio: {20; 30; 40} hanno la stessa media (30) di {29; 30; 31}, ma quest’ultimo insieme ha varianza molto più bassa, in quanto i valori sono molto più vicini alla media. Nel caso del trading, avere bassa varianza si traduce nel fatto che, ripetendo lo stesso investimento numerose volte nella stessa situazione, ciascuna volta si ottenga un guadagno che non si discosta di molto dal guadagno medio. In questo senso, possiamo dire che la varianza è in un certo senso una misura del rischio dell’investimento.
Un possibile modo per approcciare questo problema è quello di modificare l’obbiettivo dell’agente in modo tale che questo non includa soltanto la somma delle ricompense ma anche la varianza di esse. Ovvero, penalizzare l’agente quando la varianza delle ricompense è alta. In questo modo la politica che verrà appresa sarà restia a prendere decisioni molto rischiose. Un approccio alternativo è quello di scegliere tra i dati utilizzati per l’addestramento degli agenti quelli legati ad andamenti particolarmente negativi e dare più priorità ad essi. In questo modo spostiamo l’obbiettivo della politica verso il garantire che anche in situazioni anomale del mercato, ad esempio gli shock recenti legati alla pandemia o le prestazioni dell’agente siano non troppo scadenti.
Conclusioni
Abbiamo visto come il framework di RL può essere applicato al trading finanziario analizzando alcune delle criticità che emergono e spiegando alcune delle soluzioni possibili. Capire come gli algoritmi di AI possano risolvere problemi sempre più complessi, può aiutare a comprendere quali altri problemi l’intelligenza artificiale è prossima a risolvere o affrontare e quali invece rimangono distanti.



