
Negli ultimi anni si discute in Italia della possibilità di insegnare a programmare software già nelle scuole primarie. Se queste competenze per poter programmare possono essere acquisite dai bambini, allora sono in qualche modo presenti anche nei recenti algoritmi di intelligenza artificiale (AI) addestrati a generare codice eseguibile. Software che crea software, o – per dirla in altri termini – macchine in grado di programmare sé stesse. Non è fantascienza. Da sempre, gli Integrated Development Environnement (Idea) hanno sfruttato complessi sistemi di regole per supportare i programmatori nella scrittura del codice. Finora, però, il loro focus era la correzione di errori ortografici (come gli errori di battitura) e sintattici (come l’uso errato di operatori, indentazione o punteggiatura). Piccola eccezione sono i Semantic Engines (SE, ovvero motori semantici), che – suggerendo una parola alla volta – riuscivano in alcuni casi anche a coprire un po’ la semantica dell’algoritmo.
Indice degli argomenti:
Dalle regole al Machine Learning
Con l’avvento del Machine learning (ML) le cose sono fortemente progredite.
Negli ultimi anni si è assistito allo sviluppo di complessi sistemi di AI in grado di tradurre il linguaggio umano in algoritmi (e viceversa), nonché correggere errori logici e semantici complessi, dimostrando di possedere una comprensione profonda del codice.
La performance di questi algoritmi ha raggiunto livelli tali da permettere la commercializzazione di software per l’auto-completamento. Codex e PaLM, ad esempio, sono stati recentemente integrati in prodotti come Copilot di GitHub, il quale assiste i programmatori generando il codice di intere funzioni, o commentando automaticamente il codice esistente.
Secondo diversi report, la digitalizzazione ha accresciuto la domanda di programmatori ben oltre la disponibilità, facendo lievitare i costi del personale. La programmazione, inoltre, è un processo lungo e complesso, nel quale è semplice commettere errori che possono avere ripercussioni catastrofiche sugli utenti finali, come la perdita dei dati o la generazione di falle per la sicurezza. Secondo Deloitte, solo negli USA le aziende hanno perso 319 miliardi di dollari a causa di software di bassa qualità.
La programmazione assistita ha quindi lo scopo di aumentare non solo la produttività, ma anche la standardizzazione sintattica e semantica del codice, con conseguente semplificazione e miglioramento della leggibilità. Fattori cruciali per la riduzione dei bug e la manutenzione del software.
I modelli linguistici sono i protagonisti
E la tecnologia che rende questo avanzamento possibile, ancora una volta, è costituita dai modelli linguistici (language model) sviluppati in seno al Natural Language Processing (NLP), ovvero al ramo dell’AI che si occupa del processamento automatico del linguaggio.
Questi sistemi si basano generalmente su architetture auto-regressive, come i transformer, e sono addestrati per lo più a predire parole mascherate su miliardi di testi (ad esempio, su pagine di Wikipedia), per imparare la relazione tra le stesse. I transformer possono sfruttare il loro meccanismo di self-attention per comprendere il codice esistente e permetterne il completamento. Le linee di codice, infatti, sono trattate in maniera totalmente analoga al linguaggio umano. Il modello viene addestrato a considerare il codice intorno al cursore come input, e a predire quello successivo (generalmente mascherato nel dataset di addestramento) come potenziale output. Le predizioni sono generate tramite beam search, una tecnica che utilizza tutte le informazioni contestuali disponibili fino ad allora per comprendere quale sia la predizione più plausibile.
Nel caso specifico di Codex, che è alla base di Copilot, il modello linguistico di partenza è il Generative Pretrained Transformer 3 (GPT-3) di OpenAI. GPT-3, con i suoi 175 miliardi di parametri, è noto come uno dei più potenti generatori automatici di testi sul mercato. Gli autori di Codex hanno fatto il fine-tuning della versione originale di GPT-3 sul codice pubblicamente disponibile su GitHub, creando una relazione tra le docstring (ovvero i commenti che descrivono le funzioni) e il codice Python. Il risultato è impressionante: Codex risolve il 28.8% dei problemi, a vari livelli di complessità.

La programmazione assistita Google
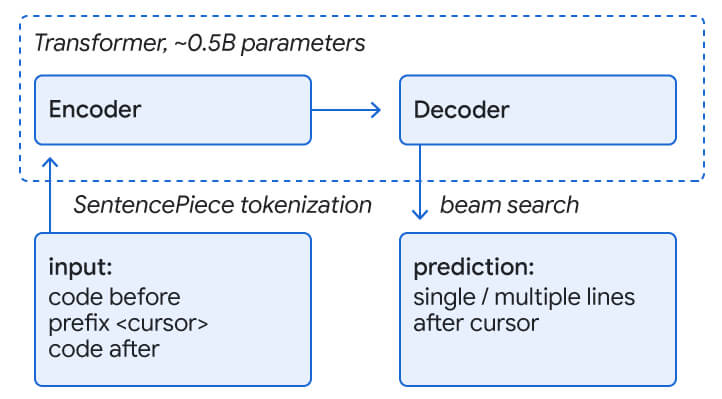
Gli ingegneri di Google hanno addestrato un transformer di 0,5 miliardi di parametri (ovvero piccolissimo, se comparato a GPT-3) a predire le parti finali di una linea o le linee successive (mascherate nel dataset di addestramento) in numerosi linguaggi, inclusi C++, Java, Python, Go, Typescript, Proto, Kotlin e Dart. Questo addestramento su più lingue ha portato a risultati simili o migliori rispetto ai modelli addestrati su un solo linguaggio.
Il loro sistema si affida, oltre che al contesto, anche alla predizione del motore semantico, che generalmente offre al massimo una parola.
Un’analisi della performance ha dimostrato che gli oltre 10 mila sviluppatori di Google accettano i suggerimenti nella singola linea il 25% delle volte, mentre accettano i suggerimenti su più linee fino al 34% delle volte, digitando oltre il 10% dei caratteri in meno rispetto agli sviluppatori che non usano l’assistenza.
I limiti dell’autoprogrammazione
Nonostante gli enormi progressi e i numerosi proclami, gli algoritmi descritti sopra sono ancora lontani dal sostituire i programmatori. Un’attenta valutazione dei modelli ha evidenziato numerose limitazioni, che diventano tanto più palesi quanto più le funzioni da generare sono complesse e innovative.
Gli autori di Codex hanno per esempio evidenziato come il loro sistema si perda nella comprensione di lunghe catene di operazioni o nella referenziazione delle giuste variabili, quando ve ne sono molte.
Il codice generato, inoltre, in alcuni casi produceva output plausibile, ma l’algoritmo sottostante non era allineato con gli intenti umani. Un’eccessiva fiducia nel codice prodotto avrebbe pertanto provocato rischi o danni ingenti.
Inoltre, essendo i modelli linguistici addestrati su dati storici, il codice prodotto rispecchia per lo più quanto imparato dal modello su quegli stessi dati, il che può includere bias o rappresentazioni erronee di categorie protette.
Conclusioni
Un capitolo a parte, infine, meritano la questione economica e quella della sicurezza. Sistemi come Codex potrebbero impattare il mondo del lavoro e trasformare il ruolo dei programmatori, i quali dovrebbero focalizzarsi più sul quality assurance. Dal punto di vista della sicurezza, la natura non-deterministica di sistemi come Codex può far sì che in alcuni casi si aprano delle falle che potrebbero essere sfruttate da virus e malware.




