
È probabile che nell’ultima ora abbiate utilizzato un algoritmo Learning-to-Rank basato sull’intelligenza artificiale senza nemmeno esserne consapevoli. Google Search e la gran parte dei motori di ricerca più usati sono dotati di tecnologie LTR, che forniscono risultati accurati tra centinaia di miliardi di pagine web. Cos’è il Learning-to-Rank (LTR) e come può essere applicato agli asset finanziari, con l’obiettivo finale di costruire strategie di investimento quantitative?
Indice degli argomenti:
Cos’è il Learning-to-Rank
Il Learning-to-Rank (LTR) è una famiglia di modelli che applicano algoritmi di apprendimento supervisionato per risolvere problemi di ranking originati da un insieme di elementi e dalla loro rilevanza rispetto a una domanda specifica. Come accennato, gli algoritmi LTR sono comunemente applicati dai motori di ricerca, dove gli utenti effettuano domande attraverso una barra di ricerca e il sistema restituisce siti web classificati in base a quella che è la loro rilevanza stimata. Tuttavia, le applicazioni dei modelli LTR vanno ben oltre la ricerca sul web. Nella biologia computazionale questi algoritmi sono utilizzati per classificare le strutture 3D candidate delle proteine, o nei sistemi di raccomandazione per suggerire a un utente articoli, film o prodotti più rilevanti in base alle sue preferenze passate.
Il primo passo per l’addestramento dei modelli Learning-to-Rank consiste nel preparare un insieme di query con un elenco ordinato di risultati per ciascuna di esse (e, se lo si vuole, un punteggio di rilevanza per ogni risultato). Questo insieme di dati etichettati è chiamato “ground truth” dataset e può essere utilizzato per addestrare i nostri algoritmi e valutare le nostre previsioni. Una volta addestrato, un buon modello di Machine learning (ML) produrrà previsioni accurate sul ranking non solo per i dati “ground truth”, ma anche per nuove richieste non effettuate in precedenza.
Tipi di algoritmi LTR
A grandi linee, le tecniche LTR possono essere classificate in tre categorie:
- algoritmi di classificazione puntuale (pointwise),
- a coppie (pairwise)
- a lista (listwise), in base all’insieme di scelte di modellazione e alle ipotesi sottostanti.
Nella Tabella 1 è riportato un confronto sintetico dei vantaggi e degli svantaggi di questi metodi.
Pointwise LTR
L’approccio di modellazione più semplice per classificare le voci consiste nell’esaminarle una alla volta e produrre un punteggio di rilevanza stimato in base alla query inserita, per poi ordinare tutti gli elementi in base a queste stime. Possiamo addestrare un regressore per prevedere il punteggio vero, oppure quantificare la pertinenza vera e propria e utilizzare invece un classificatore. Un limite notevole di questo semplice approccio è che la previsione per un elemento è prodotta indipendentemente dagli altri: ogni elemento è considerato un “punto” per la classifica, indipendente da altri “punti” (da qui il nome).
Pairwise LTR
Gli algoritmi di questa classe esaminano due voci alla volta e decidono quale sia più rilevante rispetto a una determinata query. Questo può essere inquadrato come un problema di classificazione binaria o come un problema di regressione, prevedendo la differenza di rilevanza (se disponibile). Rispetto ai Pointwise LTR, questo approccio è più costoso dal punto di vista computazionale, poiché richiede la valutazione di tutte le possibili coppie di elementi.
Listwise LTR
Nel caso dei Listwise LTR, gli algoritmi ricevono l’intero elenco di voci e producono l’ordinamento ottimale rispetto alla query data. Ciò significa che il modello non viene addestrato per risolvere un compito surrogato (ad esempio, la regressione del punteggio di rilevanza di una singola voce o la classificazione binaria di coppie di voci), ma ottimizza l’intera classifica. Per questo motivo, sono necessari modelli ML specializzati.
| Pointwise LTR | Pairwise LTR | Listwise LTR | |
| PRO |
|
|
|
| CONS |
|
|
|
Tabella 1: Vantaggi e svantaggi delle tecniche LTR
Effettuare il ranking degli asset finanziari con il ML
Oltre alla ricerca sul web, alla biologia computazionale o ai sistemi di raccomandazione, l’LTR può essere applicato anche alla gestione degli investimenti. In particolare, possiamo considerare certo numero di attività finanziarie, come i 50 componenti dell’indice Euro Stoxx 50, e, chiederci come si comporteranno in termini di rendimento su un certo orizzonte temporale, per esempio di 4 settimane. Alcuni di questi asset potrebbero registrare un rendimento positivo, altri potrebbero finire in territorio negativo, e la loro media ponderata per la capitalizzazione di mercato darà come risultato il rendimento mensile dell’indice Euro Stoxx 50.
Se fossimo in grado di prevedere la classifica dei rendimenti di questi asset, potremmo costruire una strategia di investimento ottimizzata (ad esempio, acquistare quelli che si prevede renderanno meglio) e sovraperformare il rendimento dell’indice. È qui che entra in gioco LTR.
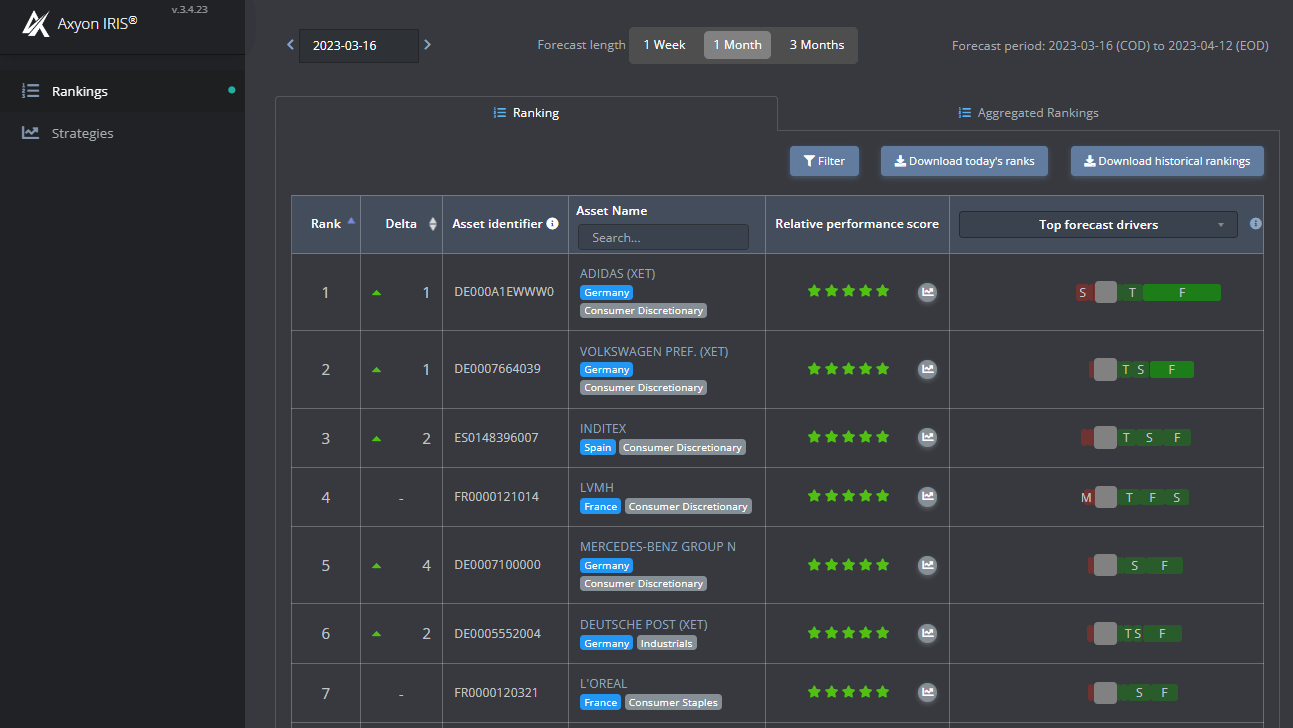
Figura 2: Un esempio di Learning-to-Rank applicato agli investimenti quantitativi. In questo caso, la nostra domanda può essere formulata come “quale dei componenti dell’Euro Stoxx 50 sovraperformerà l’indice nel prossimo mese?”, e Axyon IRIS ci restituisce un elenco di titoli classificati in base alla performance prevista.
Case study: una strategia d’investimento quantitativa sull’Euro Stoxx 50 basata sull’LTR
Ora che conosciamo gli algoritmi LTR, dobbiamo decidere se affrontare il problema utilizzando un modello pointwise, pairwise, o listwise in base alla nostra conoscenza del dominio, ai vantaggi e agli svantaggi di ciascun metodo e ai dati disponibili. Nelle figure 3, 4 e 5 confrontiamo graficamente i tre approcci, utilizzando come esempio tre titoli azionari: Volkswagen AG (VOW), Inditex (ITX) e Adidas (ADS).
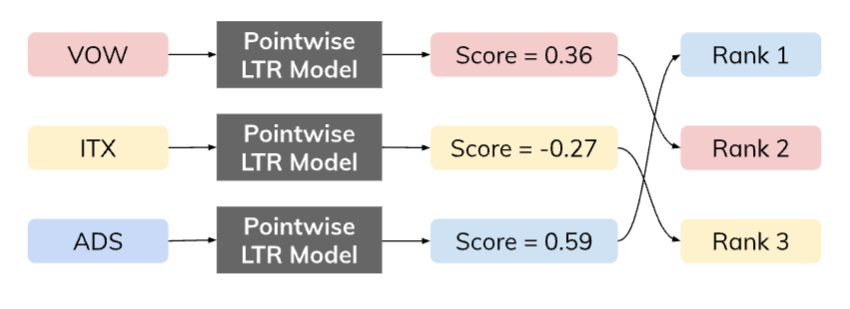
Figura 3: Nel caso di pointwise LTR, il nostro modello ML esamina un “punto” alla volta per produrre un punteggio di classificazione.
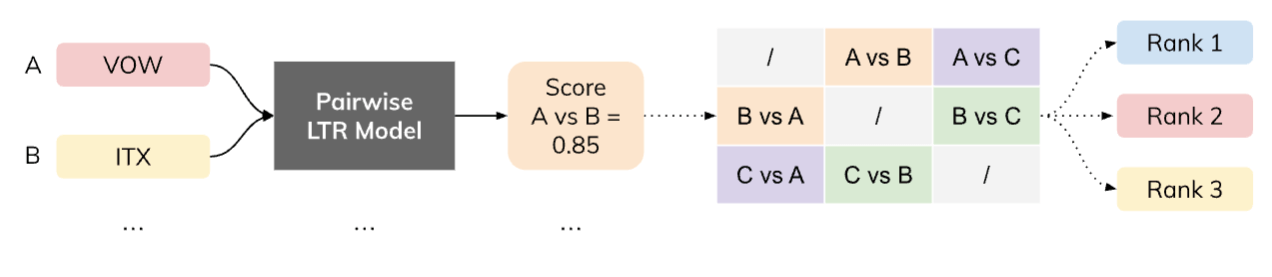
Figura 4: Nel caso di pairwise LTR, il nostro modello ML esamina una “coppia” alla volta e restituisce una previsione su di essa. Dalla matrice trasversale di tutte le previsioni per tutte le coppie, possiamo ottenere un ranking previsto
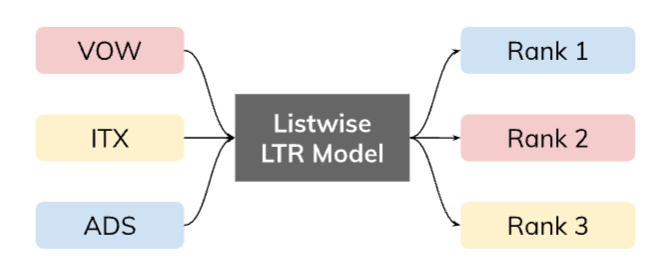
Figura 5: Nel caso di listwise LTR, il nostro modello ML esamina l’intera “lista” per produrre una previsione di ranking
In Axyon AI abbiamo sperimentato diversi approcci LTR, e dal febbraio 2021 gestiamo in modo continuativo un modello LTR pairwise sull’Euro Stoxx 50, alimentato da un insieme di reti neurali siamesi[1] addestrate su centinaia di variabili di input per prevedere la classifica mensile dei titoli target in base al rendimento. Un modo per utilizzare tale modello consiste nel costruire una semplicissima strategia Long-Only Equally Weighted che investe in una selezione dei dieci titoli migliori, come previsto dal modello, e aggiorna quotidianamente i suoi pesi. Come ha fatto una strategia così semplice a superare la prova del tempo? Se osserviamo la Figura 6, che confronta la strategia Axyon Euro Stoxx Top 10 con l’indice Euro Stoxx 50, possiamo notare che la prima ha nettamente superato la seconda in termini di rendimento annuo (CAGR del 23% contro il 12%), con una volatilità annua comparabile (circa il 19%).
Quindi, l’LTR pairwise è sempre la soluzione migliore? Come abbiamo visto, i diversi metodi hanno pro e contro diversi e, in ultima analisi, il nostro compito di esperti di AI è quello di collaborare con gli esperti del rispettivo settore, in questo caso asset manager e analisti quantitativi, e selezionare la tecnica migliore per il compito da svolgere, in base al problema aziendale da affrontare.
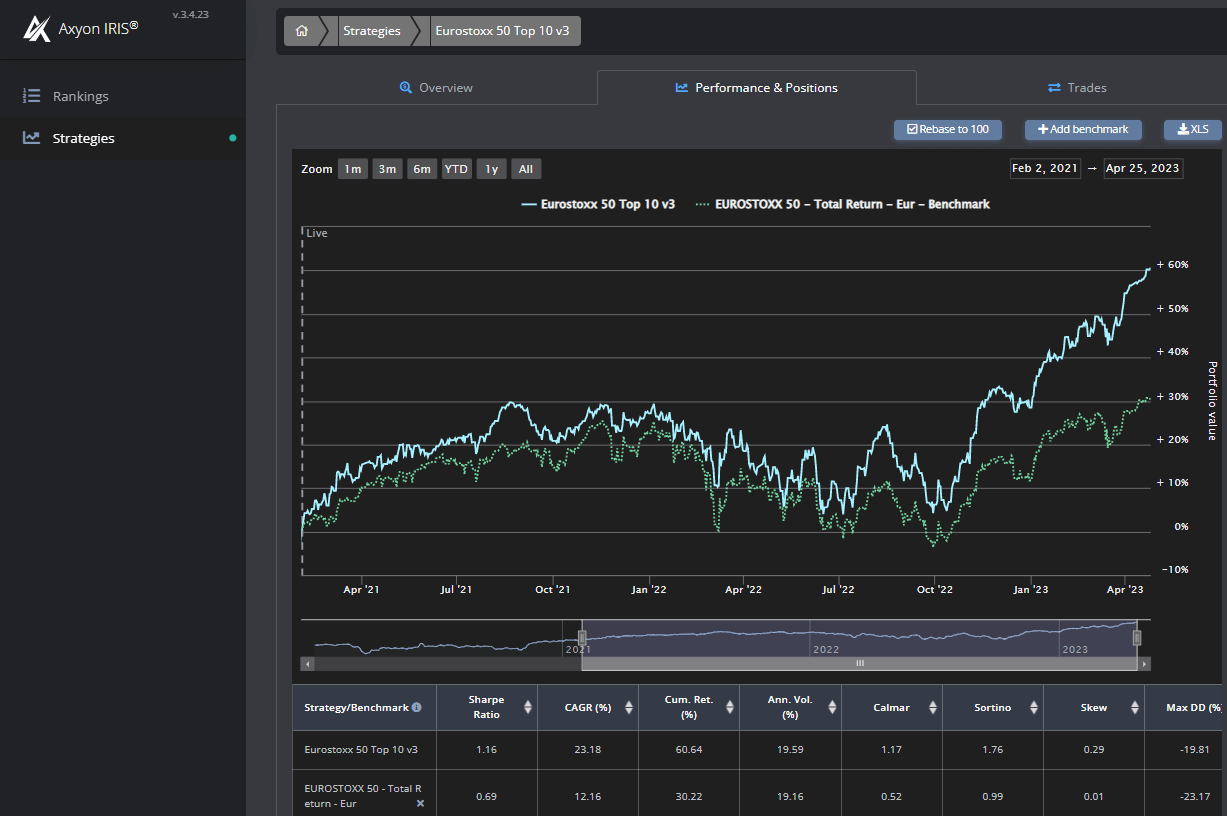
Figura 6: Una semplice strategia Long-Only Top 10 Equally Weighted sui costituenti dell’Euro Stoxx (linea blu) rispetto all’indice Euro Stoxx 50 (linea verde) da febbraio 2021 ad aprile 2023.
Note
- Taigman, Yaniv, et al. “Deepface: Closing the gap to human-level performance in face verification.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2014. ↑




