
Sempre più frequentemente la raccolta dei dati di processo, oggi quasi scontata per macchinari industriali, consente di ricavare dagli ambienti produttivi informazioni sullo stato di salute dei componenti, sulle performance produttive, e più in generale approfondire la comprensione dei processi. Il dato, una volta raccolto può fornire la risposta a richieste di ottimizzazione, identificazione di criticità, e previsione di future tendenze. Tutto questo passa però da un’analisi che deve essere ben orientata alla domanda posta. Entrando in una moderna fabbrica dotata di macchine utensili, automazione e sistemi connessi, dovremmo una grande intelligenza artificiale a governo della produzione. Eviteremo volutamente di rispondere alla questione etica sull’ingresso di sistemi di intelligenza artificiale in sostituzione ai processi decisionali dell’uomo, ma affronteremo il tema di cosa siano e come funzionino gli algoritmi e le tecniche di machine learning utilizzate nella industria 4.0, cercando di fare chiarezza in un settore di non facile comprensione.
Indice degli argomenti:
I campi di applicazione del machine learning nell’industria 4.0
La definizione stessa di “Industria 4.0” è soggetta a diverse sfumature a seconda del contesto e del settore di riferimento [1-2], e in queste differenti declinazioni trova spazio il campo del machine learning, ovvero degli algoritmi di apprendimento automatico.
Sono queste delle metodologie di analisi dei dati in grado di fornire come risultato la visualizzazione, o l’identificazione di modelli, schemi, tendenze, facendo “imparare” a uno strumento software come risolvere o puntare alla risoluzione di uno specifico quesito.
Nel nostro quotidiano ritroviamo queste tecnologie nella proposizione di pubblicità mirate sulla base delle nostre abitudini, su pagine web, app, e social media [3-4]. Sono tecnologie di machine learning anche quelle famiglie di algoritmi che si occupano di decodificare il linguaggio scritto (NLP – Natural Language Processing) per identificare modelli di risposta, o autocompilare quello che stiamo scrivendo, per esempio nell’effettuare una ricerca su internet.
I campi di applicazione sono principalmente riassumibili in tre tipologie [5]:
- descrittivi;
- predittivi;
- prescrittivi.
Un’analisi descrittiva risponde a domande come “cosa è successo””, o “cosa sta succedendo?”, e trova applicazione tramite strumenti come dashboard di monitoraggio ed emissione di rapporti di funzionamento. Il risultato dell’analisi permette di comprendere a pieno l’entità di un fenomeno, sia esso il consumo di un componente, o una metrica di rendimento per un impianto, così come un’analisi di dati di vendita. Questo può essere usato quindi per fornire all’utilizzatore un maggior livello di comprensione di una condizione.
Le analisi predittive rispondono a domande sul comportamento futuro, come “cosa e perché accadrà?”, sfruttando strumenti di mining (letteralmente “estraendo”) da una base dati delle previsioni di comportamento del fenomeno studiato. Il risultato consente quindi di definire e proiettare nel tempo un modello di comportamento, per consegnare all’utilizzatore delle stime su stati e condizioni future.
Analisi prescrittive possono invece essere usate per supportare la presa di decisioni, rispondendo a domande come “Cosa dovrei fare?”, con lo scopo di massimizzare una funzione. Pensiamo in questo caso ad algoritmi di ottimizzazione, simulazione e previsione di scenari alternativi sulla base di una decisione.
Prima di porre la domanda, occorre quindi definire cosa ci aspettiamo dalla risposta. Viene facile pensare che dai dati possa essere estratto qualsiasi tipo di informazione per ottenere risposte ad ogni dubbio, ma la realtà è che gli algoritmi che verranno tra poco presentati non sono in grado di prevedere la nostra necessità in senso lato. Possono sì ottimizzare delle funzioni, lavorando per obiettivi ed identificando i set di variabili favorevoli per ottenere un risultato, ma prima di questo necessitano di un “attrezzaggio”, che consenta una puntuale identificazione dei risultati attesi sulla base dell’input fornito.

I vari tipi di machine learning
Alla base di questi metodi troviamo sempre una gran quantità di dati, che deve essere raccolta per poter fornire agli algoritmi una base su cui lavorare. Se nell’imparare nuove lingue necessitiamo di vocabolari e libri di grammatica, anche gli algoritmi – che mancano di immaginazione propria – necessitano solitamente di un set di condizioni per poter apprendere le regole del gioco. Possiamo quindi fare una prima suddivisione nelle tecniche di machine learning, identificando le principali categorie di apprendimento:
- supervisionato;
- non supervisionato;
- rinforzato.
I metodi di apprendimento supervisionato mirano alla definizione di una funzione in grado di associare a ogni input fornito il corretto output, previsto sulla base di un gruppo di coppie input-output fornite al sistema come “casi studio”. Occorre quindi determinare la serie di esempi che verranno forniti al sistema per poter dedurre il comportamento del fenomeno, saranno queste le “regole del gioco” che forniremo al sistema per costruire il modello di funzione richiesto. Questa prima fase potrebbe sembrare banale, ma qualora il dataset fornito mancasse di una variabile, o non fosse rappresentativo del sistema completo in studio, rischieremmo di trovare funzioni di correlazione, ma non di causalità. Correlazione non implica causalità, soprattutto nel caso in cui i dati forniti siano incompleti.
Per meglio argomentare questo primo e critico frangente, citiamo l’esempio della regola di Mierscheid, secondo cui “La quota di voto dell’SPD è uguale all’indice della produzione di acciaio grezzo negli stati federali occidentali – misurata in milioni di tonnellate – nell’anno delle elezioni federali”. Chiaramente siamo di fronte a due variabili non correlate da un vincolo di causalità, ma questa coincidenza ripetuta per un numero sufficiente di volte può essere confusa con una regola. Gli algoritmi di apprendimento automatico mancano della finezza di saper distinguere queste casualità, e potrebbero quindi modellare funzioni errate, qualora i dataset in ingresso fossero incompleti o “inquinati” da variabili non pertinenti.
Una volta determinato il dataset corretto, dobbiamo definire le “caratteristiche” del nostro input, ovvero gli elementi rappresentativi su cui iniziare l’allenamento dell’algoritmo.
Determinata la tecnica che si intenderà utilizzare, seguirà poi un ciclo di apprendimento e validazione, associando eventualmente variabili di controllo per supportare e raffinare la struttura della funzione sviluppata dall’algoritmo di machine learning. Immaginiamo di aggiungere dei coefficienti adimensionali, per poter dare più o meno peso ad elementi della funzione ricavata, e a cicli di training ripetitivi su dataset di allenamento crescenti, con lo scopo di ricavare una funzione sempre più precisa.
L’apprendimento non supervisionato affronta invece problemi di classificazione dei dati, senza attendere in input un dataset di allenamento in cui siano già definiti esempi di classificazione. Possiamo pensare ad esempio a funzioni di valutazione della prossimità di punti all’interno di un insieme, per poter determinare relazioni e suddivisioni negli elementi.
Si parla invece di apprendimento rinforzato quando il sistema ha lo scopo di creare regole di azione per ottimizzare una funzione obiettivo. Gli algoritmi di questa tipologia interagiscono con un ambiente, apportando cambiamenti tramite la successiva esecuzione di funzioni, le quali hanno come risultato la generazione di un “premio” che viene reimmesso nell’algoritmo a scopo di validazione dell’azione intrapresa. Si tratta, in estrema sintesi, di un approccio Pavloviano, in cui diamo un bonus tutte le volte che il risultato della funzione viene migliorato, e un malus negli altri casi.
Esistono poi anche altre tipologie di apprendimento, come l’anomaly detection per identificare condizioni o parametri sospetti all’interno di un dataset, e il representation learning per estrarre informazioni utili durante la creazione di classificatori o altri algoritmi di apprendimento (per facilitare la selezione del dataset in ingresso). [6]
Le varie tecniche di apprendimento automatico utilizzate nell’industria 4.0
Definita la domanda da porre al sistema, e la strategia con cui vogliamo che questo possa strutturare il proprio apprendimento, rimane da selezionare la tecnica attraverso cui effettuare l’apprendimento automatico. Alcuni metodi utilizzano algoritmi di machine learning e data mining per fornire una comprensione di base delle diverse tendenze dei dati, correlando attributi al rilevamento di anomalie. Tali metodi includono funzioni statistiche descrittive “classiche”, come media, mediana e varianza. Altri metodi, che forniscono risultati più coerenti e accurati, includono modelli di correlazione, clustering e generativi.
Tuttavia, questi metodi sono relativamente complicati e piuttosto costosi sia in termini di tempo, sia in termini di competenze necessarie per implementare questi strumenti. Essendo un argomento secondario nelle statistiche, i metodi di correlazione si applicano solitamente all’analisi delle variazioni degli attributi dei dati raccolti.
Tali metodi includono, ad esempio, Chi-square per i dati categorici e il coefficiente di correlazione di Pearson per i dati numerici.

Indice di correlazione di Pearson [Credits Denis Boigelot]
I metodi di correlazione sono tra i più comuni da utilizzare per le variabili numeriche, e nel caso dell’indice di Pearson, forse il modello più noto, si assegna un valore compreso tra – 1 e 1, dove 0 non è correlazione, 1 è la correlazione positiva totale e – 1 è la correlazione negativa totale. Questo viene interpretato come segue: un valore di correlazione di 0,7 tra due variabili indicherebbe che esiste una relazione significativa e positiva tra le due. Una correlazione positiva significa che se la variabile A sale, anche B salirà, mentre se il valore della correlazione è negativo, all’aumentare di A diminuirà B.
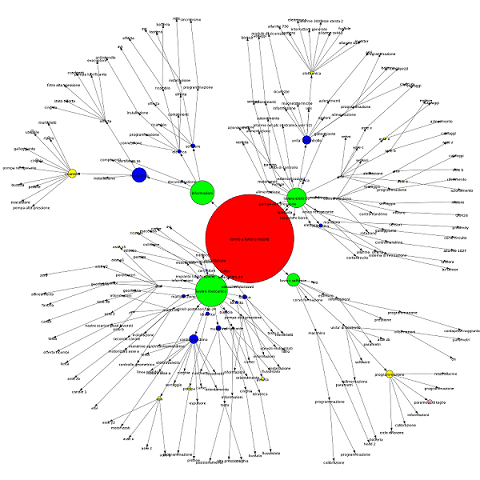
Clustering di richieste di assistenza tecnica
[Castello, F., Roveri, M., Sortino, F. (2020) Machine Learning for machine tool assistance: development and implementation of an industrial solution for a leading Italian corporate]
Mentre l’analisi di correlazione indaga le dipendenze degli attributi, i metodi di clustering si concentrano sulla categorizzazione in gruppi da dataset. Ambiti d’uso sono ad esempio l’ottimizzazione dei costi e l’efficienza complessiva in linee produttive. In questo caso gli algoritmi puntano alla creazione di aggregazioni, letteralmente grappoli, derivanti dalle associazioni dei dati attraverso le proprietà o le familiarità di questi. Possono inoltre essere utilizzati per evidenziare raggruppamenti non evidenti a una prima visualizzazione, o per trovare dipendenze, collegamenti e familiarità non evidenti.
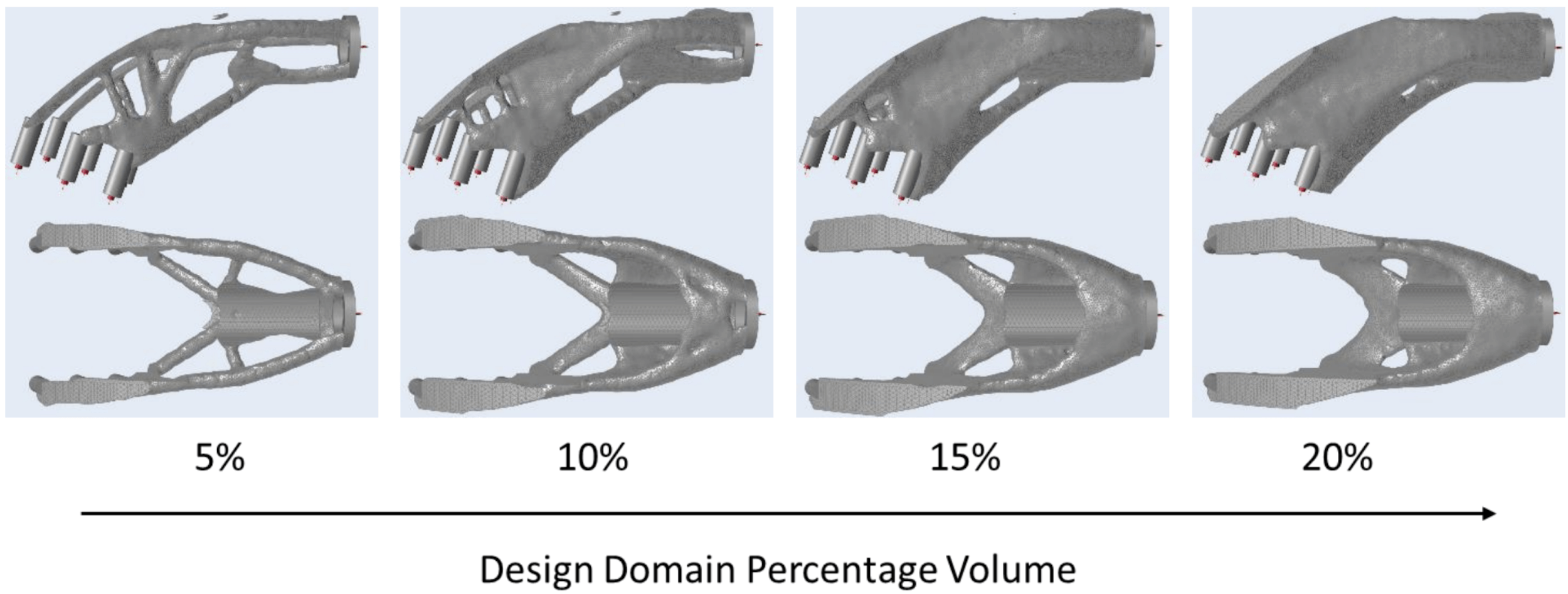
Ottimizzazione topologica di un componente meccanico tramite metodologia generativa
I metodi generativi si concentrano sulla generazione di dati attraverso un insieme di regole definite dall’utilizzatore e dall’ambiente in cui viene realizzata l’analisi. La ricerca attuale presenta diversi modelli per migliorare, ad esempio, lo sviluppo dinamico della progettazione. In questo caso il sistema richiede in input le condizioni al contorno dell’ambiente di sviluppo, come ad esempio le geometrie possibili, i carichi applicati, e le definizioni di materiali utilizzabili. Gli algoritmi creeranno differenti geometrie nelle condizioni al contorno definite, validando le condizioni di carico al variare di parametri come il riempimento assoluto del volume di progettazione, o la riduzione di volume da una geometria di partenza.
Mentre i metodi descrittivi forniscono analisi di eventi passati, i metodi predittivi si concentrano sull’utilizzo dei modelli passati per anticipare eventi futuri. Nell’introdurli occorre sottolineare che non esistono modelli predittivi “alla carta”, se non per situazioni e ambiti estremamente specialistici.
I metodi predittivi ad oggi industrializzabili sono numerosi ma possono essere classificati in quattro gruppi principali.
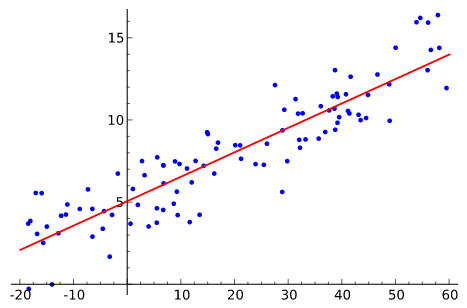
Regressione lineare
I metodi di regressione sono probabilmente i più utilizzati nella statistica, e possono essere utilizzati anche in statistiche descrittive. Il modello più noto è la regressione lineare, ovvero una derivazione lineare della relazione tra un valore di risposta e una o più variabili. Questo consente in casi semplici di estrapolare un modello di “comportamento” della funzione, che può quindi essere esteso nel dominio delle variabili usate, quindi eventualmente anticipando il comportamento di un sistema sulla base del comportamento precedentemente registrato.
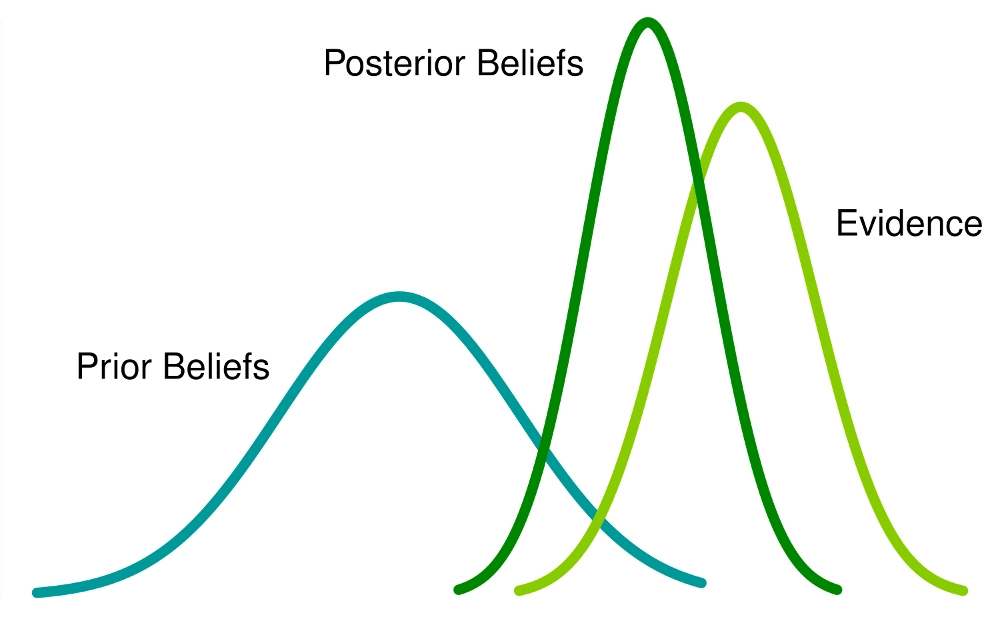
Modello di analisi Bayesiana [© Neeraj Singh Sarwan 2016]
Il teorema di Bayes consente invece di calcolare e aggiornare indici di probabilità a seguito dell’acquisizione di nuovi dati dai sistemi analizzati. Questi metodi possono ottenere prestazioni di previsione elevate purché l’assunzione di indipendenza tra le variabili misurate sia corretta.
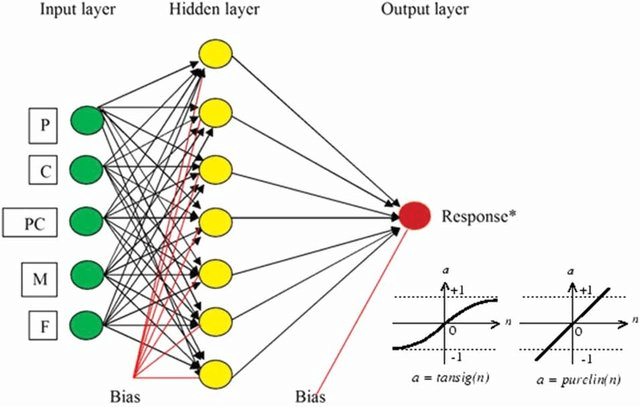
Esempio di rete neurale
[Mahanty, B., et al. (2013). DOI 10.1080/09593330.2013.819022.]
Le reti neurali, sempre più diffuse e conosciute, rappresentano costrutti di diverse reti di dati, organizzate in strati (layer) di analisi successive. Questi sono costituiti da diversi nodi interconnessi, inclusi nodi di input, nodi nascosti e nodi di output, a loro volta regolati da condizioni al contorno. Ogni rete neurale include una serie di regole di apprendimento che modificano i pesi dei nodi in base al modello di input presentato, basandosi sulla distanza tra il valore previsto e quello reale, la rete neurale può regolare i pesi di conseguenza per ottenere un modello “addestrato” più stabile e quindi veritiero nella previsione.

Video: Uso dell’intelligenza artificiale nell’industria per incrementare la produttività – Google Cloud (in inglese)
Riferimenti
[1] G. Culot, G. Nassimbeni, G. Orzes, M. Sartor. (2020) Behind the definition of Industry 4.0: Analysis and open questions, Int. J. Prod. Econ 107617. https://doi.org/10.1016/j.ijpe.2020.107617
[2] P.K. Muhuri, A.K. Shukla, A. Abraham. (2019) Industry 4.0: A bibliometric analysis and detailed overview, Eng. Appl. Artif. Intell. 78 p.218–235. https://doi.org/10.1016/j.engappai.2018.11.007
[3] Jin-A Choi, Kiho Lim. (2020) Identifying machine learning techniques for classification of target advertising, ICT Express, Volume 6, Issue 3, Pages 175-180, ISSN 2405-9595, https://doi.org/10.1016/j.icte.2020.04.012
[4] Geng Cui, Man Leung Wong, Hon-Kwong Lui. (2006) Machine Learning for Direct Marketing Response Models: Bayesian Networks with Evolutionary Programming. Management Science Vol. 52, No. 4.
https://doi.org/10.1287/mnsc.1060.0514
[5] Dursun Delen, Haluk Demirkan,Data, information and analytics as services,Decision Support Systems,Volume 55, Issue 1,2013,Pages 359-363,ISSN 0167-9236, https://doi.org/10.1016/j.dss.2012.05.044
[6] Y. Bengio; A. Courville; P. Vincent (2013). “Representation Learning: A Review and New Perspectives”. IEEE Transactions on Pattern Analysis and Machine Intelligence. 35 (8): 1798–1828. arXiv:1206.5538. doi:10.1109/tpami.2013.50



