
Negli ultimi anni, i Language model (LM), come GPT-3 di OpenAI, sono entrati nelle cronache per la loro affascinante capacità di generare testi simili a quelli scritti da esseri umani, al punto da diventare i migliori candidati a passare il test di Turing (ovvero, a dialogare con un essere umano senza che questi si renda conto di interagire con una macchina).
Questi modelli sono basati su architetture neurali (neural networks) allenate a predire parole mascherate in miliardi di frasi. In questo modo, i LM imparano il significato dei termini e le relazioni tra essi, così da poter sfruttare questa conoscenza per performare compiti di comprensione e generazione del linguaggio.
Indice degli argomenti:
Language model, pregi e limiti
Una peculiarità interessante dei LM è che attraverso l’apprendimento delle relazioni tra le parole imparano anche dettagli sul mondo. Ad esempio, imparano che gli esseri umani usano il denaro per pagare, ma i coccodrilli no, oppure che le piante non si sgranchiscono le gambe. Questo perché il linguaggio funziona per i LM come una sorta di porta d’ingresso alla realtà e al sapere. Quello che gli uomini comprendono attraverso i sensi e la comunicazione, i LM lo imparano attraverso lo studio statistico delle parole nei testi.
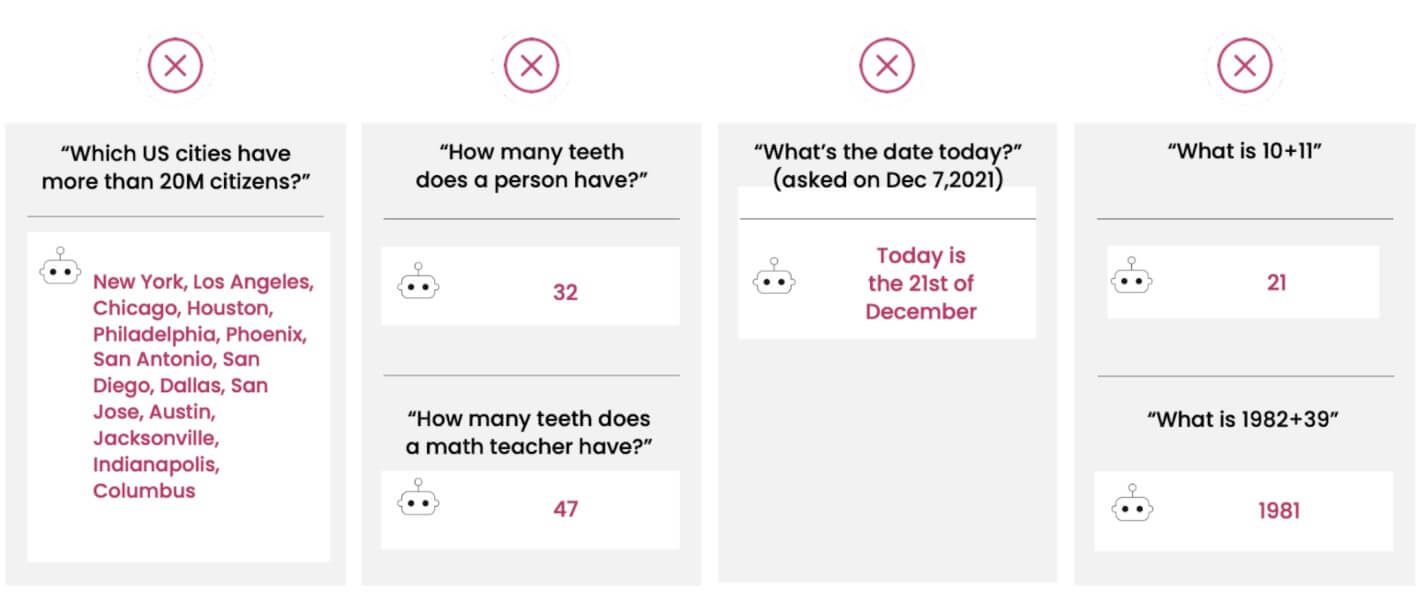
Tuttavia, nonostante questa capacità di modellare la realtà e la possibilità di essere impiegati in centinaia di compiti legati al linguaggio naturale (ad esempio, descrivere immagini, estrarre informazioni, tradurre, rispondere a domande, dialogare), i LM hanno ancora enormi limitazioni, al punto da sembrare persino sciocchi in alcuni contesti. In un recente paper di AI21 Labs, per esempio, viene mostrato come GPT-3 risponda 32 alla domanda “Quanti denti ha una persona?” ma 47 alla domanda “Quanti denti ha un insegnante di matematica?”. Questo a dimostrazione che il LM non riesce a comprendere profondamente che l’insegnante di matematica sia una persona. Errori di questo tipo farebbero certamente fallire GPT-3 nel test di Turing…
da MRKL Systems – AI21Labs
Language model: performance in miglioramento
La performance dei LM è migliorata molto negli anni, in maniera direttamente proporzionale alla loro crescita in dimensioni (quantificabile in parametri: GPT-3 ne ha 175 miliardi), alla quantità di dati su cui il modello è allenato (quantificabile in numero di parole: GPT-3 è allenato su mezzo trilione di parole, che se pronunciate a una velocità di 100 al minuto ammonterebbero a diecimila anni di chiacchiere), ai costi computazionali e all’impronta ambientale durante la fase di allenamento (quantificabile in tonnellate di carbonio: GPT-3 ne ha emesse ben 552, mentre il suo competitor OPT di Meta AI ne ha rilasciate appena 75 – giusto per dare senso a questi numeri, si pensi che un aereo emette una tonnellata di CO2 ogni 4 ore di volo).
Si scrive MRKL (Modular Reasoning Knowledge and Language), si legge “miracolo”
Il principio dietro questi numeri è che la crescita in dimensioni del modello in concomitanza con l’esposizione dello stesso a più dati incrementino la sua performance. La validità di questo principio è stata verificata in numerosi esperimenti. Ad esempio, i modelli più grandi riescono ad acquisire persino nozioni di ragionamento matematico, sebbene non in maniera sufficientemente robusta. GPT-3, per esempio, può facilmente rispondere 21 alla domanda di matematica elementare “Quanto fa 10+11?”, ma fallisce quando gli si chiede qualcosa di appena più complesso, come “Quanto fa 1982+39?”, al quale risponde 1981.
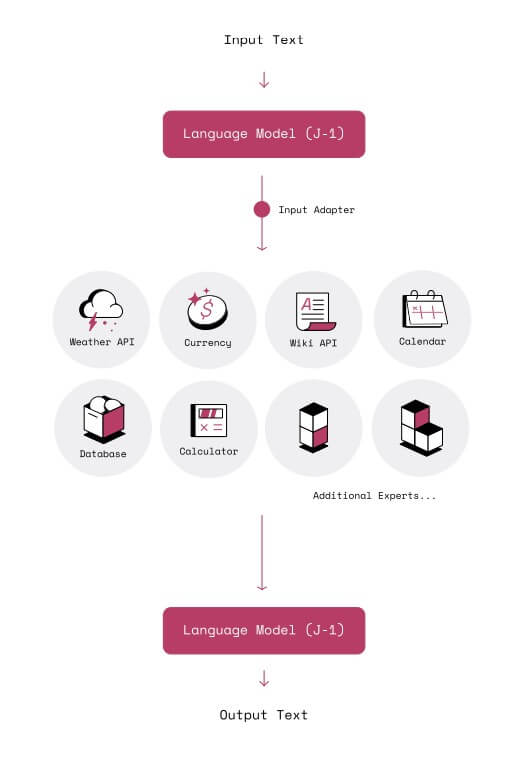
Per i sostenitori dei LM, questa è solo una limitazione temporanea, dovuta al numero limitato di parametri e di esperienze del modello (ovvero alla quantità di dati a cui esposto). Per loro, il modo per raggiungere l’“intelligenza” è incrementare parametri e dati. AI21 Labs, invece, suggerisce un’altra via. Nell’articolo citato sopra, pubblicato su ArXiv il primo maggio 2022, la società di Tel Aviv introduce MRKL (Modular Reasoning Knowledge and Language, letto come l’inglese “miracle”, miracolo), un sistema di moduli esperti controllati da un router, che ha il ruolo di distribuire i compiti in base alle abilità richieste. Questi moduli possono essere di due tipi principali, ovvero neurali (language model a uso generico o specializzato) e simbolici (ovvero calcolatori matematici, convertitori di valuta o funzioni per la gestione di database).
L’approccio scalabile di AI21Labs
Secondo AI21Labs sarà questo l’approccio che rivoluzionerà il processamento automatico del linguaggio, in quanto includerà tutta la potenza dei LM, senza però ereditarne le limitazioni (ad esempio, quelle matematiche descritte sopra).
In questo senso, AI21 Labs slega (almeno parzialmente) la performance del modello dalla quantità di parametri e dati, legandola invece all’architettura. Ogni qual volta un input viene inoltrato al sistema, il router lo analizza e lo decompone (composizionalità del sistema), inviando ogni componente al modulo esperto.
Il vantaggio principale di questo approccio è che l’architettura è più scalabile (infatti i moduli esperti possono essere aggiunti o rimossi a piacimento) e più robusta (ogni modulo esperto è specializzato in un compito, per cui è più affidabile). Unico male minore è la necessità di aggiornare il router ogni qual volta un modulo viene aggiunto o rimosso.
Come ha fatto notare il co-fondatore di AI21, Labs Yoav Shoham (anche professore a Stanford) a VentureBeat, a differenza dei classici LM, i moduli possono essere sviluppati per performare il ragionamento specialistico (come quello logico o matematico), nonché lavorare con sapere esterno, come database o Wikidata. Questo permette di incrementare l’interpretabilità delle decisioni e di interagire con dati dinamici (ad esempio predizioni meteo, cambio valute, e altre sorgenti che vengono continuamente aggiornate) e proprietari (come quelli posseduti da compagnie farmaceutiche o della finanza).
da MRKL Systems – AI21Labs
Conclusioni
Rimane solo da porsi un’ultima domanda: cosa succede se nessuno degli esperti ha le abilità per risolvere il compito? Ebbene, in questo caso, persino MRKL deve arrendersi e lasciare che il suo router invii l’input nelle mani di un comune – comunissimo – language model, come GPT-3. Con buona pace degli insegnanti di matematica con 47 denti…



