
- La realtà aumentata trova applicazioni in vari settori come gaming, marketing, design, edilizia, manutenzione predittiva e medicina. Il suo punto di forza è la capacità di arricchire la percezione del mondo fisico con informazioni digitali, offrendo un’interazione più consapevole con l’ambiente rispetto alla realtà virtuale (VR).
- L’AR sovrappone elementi digitali (immagini, testi, suoni, video) agli ambienti reali. Per usufruire di questa tecnologia, sono necessari dispositivi come smartphone, tablet o visori AR.
- Per rispondere alle crescenti esigenze di accuratezza e velocità, l’intelligenza artificiale (AI) assume un ruolo sempre più importante, migliorando le prestazioni in condizioni ambientali non ottimali e rendendo possibile l’uso su dispositivi a basso consumo energetico. L’AI supporta anche funzionalità avanzate come Facial Landmarks Extraction, Segmentazione delle immagini, Pose Estimation, Hand Tracking, Text Detection, Translation e Depth Estimation.
Le applicazioni pratiche della realtà aumentata (AR) sono molteplici e vanno dal mondo del gaming, il marketing, il design, l’edilizia, la manutenzione predittiva fino all’ambito medico. L’elemento chiave che fa della realtà aumentata un approccio vincente è proprio la capacità di collegare il virtuale con il reale: a differenza della realtà virtuale (VR) dove tutto ciò che l’utente vede non esiste, l’AR permette di arricchire la percezione del mondo fisico con informazioni digitali e di interagire con esso in maniera più consapevole.
Indice degli argomenti:
In cosa consiste la realtà aumentata
L’AR consiste in un insieme di tecniche che sovrappongono elementi digitali come immagini, testi, suoni e video in ambienti reali. L’utente che ne fa uso, percepisce sé stesso in una realtà ibrida tra quella reale e quella virtuale, dove gli oggetti digitali coesistono nello stesso ambiente insieme a quelli fisici. Per poter usufruire di questa tecnologia, accanto all’implementazione di specifici algoritmi, è richiesto l’utilizzo di un dispositivo abilitante: solitamente si fa riferimento ad app per smartphone e tablet in grado di accedere alla fotocamera o visori di realtà aumentata, costituiti da particolari occhiali che fungono da display trasparenti consentendo di osservare contemporaneamente il mondo circostante.
Alcuni esempi di visori AR più conosciuti sono i Microsoft Hololens 2 e i Google Glass 2, ma vi sono anche visori di realtà virtuale (VR) come Oculus Quest 2, che attraverso la modalità “pass-through” permettono di accedere alle immagini delle fotocamere di controllo, ricostruendo la visuale della stanza in cui l’utente si trova. I visori possono essere monoculari o binoculari a seconda che le informazioni digitali siano proiettate su entrambe le lenti (dando la percezione di tridimensionalità) o vengano messe a disposizione dell’utente in un solo occhio o in una specifica regione del campo visivo.

Figura 1 : Alcuni visori AR: MIcrosoft Hololens 2, Google Glass 2, Oculus Quest 2 (modalità pass-through)
Tecnicamente, per poter sovrapporre informazioni digitali su contesti reali, uno dei requisiti fondamentali è la conoscenza e la mappatura dell’ambiente fisico circostante. Per tale motivo la Computer vision è da sempre stata una delle colonne portanti del mondo AR: tramite l’utilizzo di specifici algoritmi essa è in grado di tracciare texture, oggetti, persone e punti di interesse all’interno delle immagini provenienti dalle fotocamere. Queste rilevazioni fungono poi da keypoint su cui andare ad ancorare i contenuti virtuali dando l’impressione che essi siano realmente presenti nella scena, anche muovendosi liberamente intorno ad essi.
Le forme più basiche di AR si basano su algoritmi di Feature Detection, Feature Tracking e Template Maching. Per Feature si intende un generico punto di interesse dell’immagine, caratterizzato per esempio da bordi regolari, angoli o specifici colori, molto spesso caratteristico quindi di un determinato oggetto fisico. Alcuni algoritmi di Feature Detection come il SURF (Speeded Up Robust Features) estraggono questi punti dell’immagine memorizzandone le coordinate. Altri algoritmi di Feature Tracking come il KLT Pyramid (Kanade-Lucas-Tomasi) tracciano gli spostamenti di questi punti nel tempo, immagine per immagine, durante il movimento della fotocamera. Questo permette di ottenere un sistema di riferimento solidale all’ambiente fisico su cui individuare piani e superfici di appoggio per gli elementi virtuali. Gli algoritmi di Template Matching come il SIFT (Scale Invariant Feature Transform), invece, prevedono l’utilizzo di un determinato template (può essere un’immagine o un QRCode) che viene continuamente ricercato all’interno dei frame provenienti dalla fotocamera.
Una volta trovato, conoscendo le proporzioni originali del template, è possibile calcolare con estrema precisione sia l’inclinazione che la distanza relativa tra esso e l’osservatore, in modo tale da collocare sulla scena un oggetto virtuale con scala e angolazioni corrette.

Figura 2: Algoritmi base di Computer Vision: estrazione dei contorni (Sobel) e delle linee (Hough Line Transform). Il primo costituisce una prima forma di segmentazione dell’immagine, il secondo è utile a fini prospettici. (Autore: Giovanni Nardini)

Figura 3: Algoritmo di Template Matching. A sinistra: rendering di un cubo in realtà aumentata, ancorato al template. (Autore: Giovanni Nardini)

Figura 4: Algoritmi di Computer Vision: a sinistra FAST Feature Detection, a destra tracking delle Feature durante il movimento ad opera dell’algoritmo KLT Pyramid. Il secondo permette di costruire il sistema di riferimento fisico per gli oggetti virtuali. (Autore: Giovanni Nardini)
Un esempio pratico: l’app Pokemon Go
Un esempio pratico di utilizzo di questi algoritmi viene dal mondo dell’intrattenimento, con l’app Pokémon Go, una delle prime applicazioni che ha fatto conoscere l’AR nel mondo. Basata sul celebre anime, i giocatori possono scovare nuovi Pokémon in giro per la città o farli allenare in specifiche palestre virtuali, collocate in punti strategici. Durante le sfide o i momenti di cattura, l’utente può vedere le creature attraverso la fotocamera del proprio smartphone. Il sistema si basa quindi sulla localizzazione GPS, sulla Computer vision e anche sull’elaborazione dei dati provenienti da giroscopio, magnetometro ed accelerometro. Questi ultimi sensori infatti, permettono di migliorare le prestazioni di mappatura dell’ambiente fisico, diminuendo i margini di errore che si accumulano con un approccio puramente visivo.
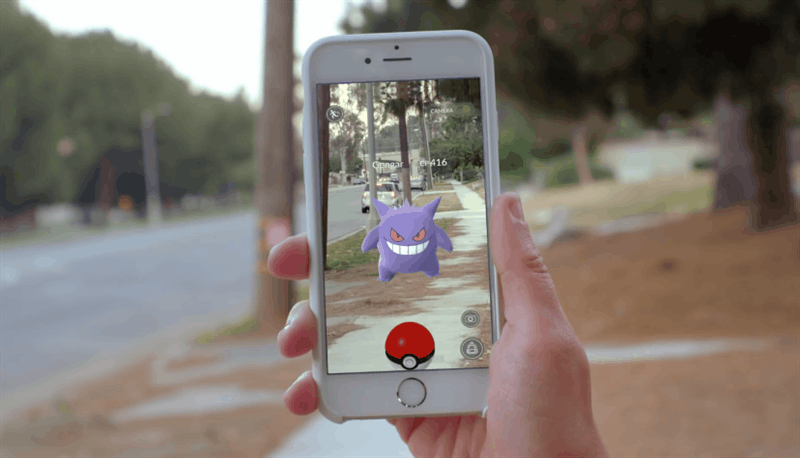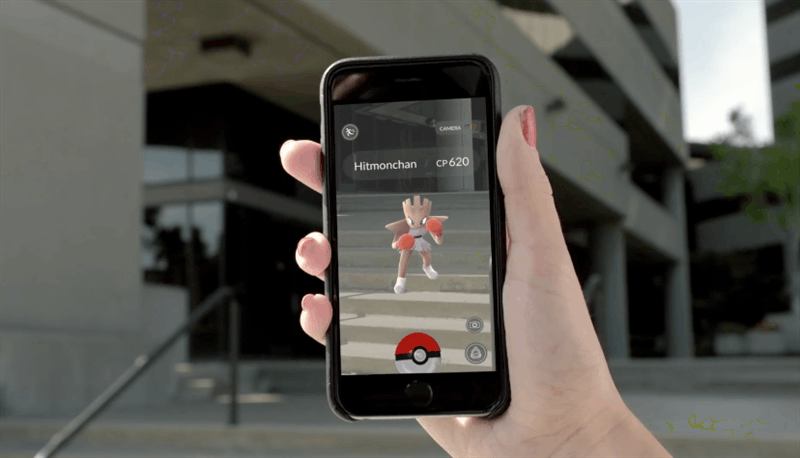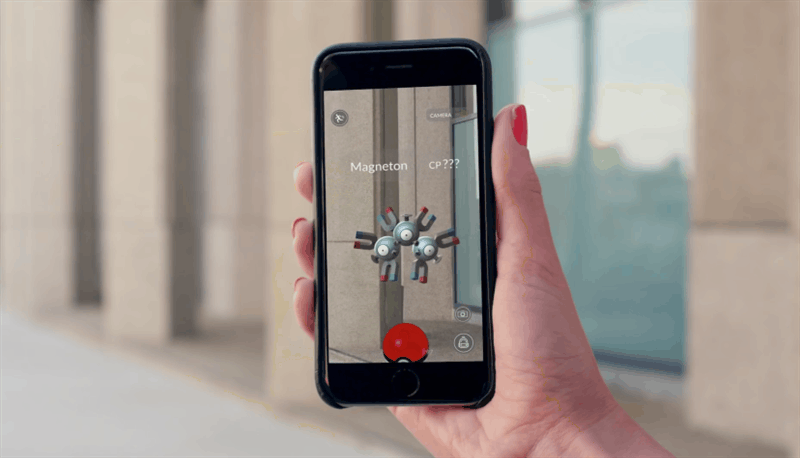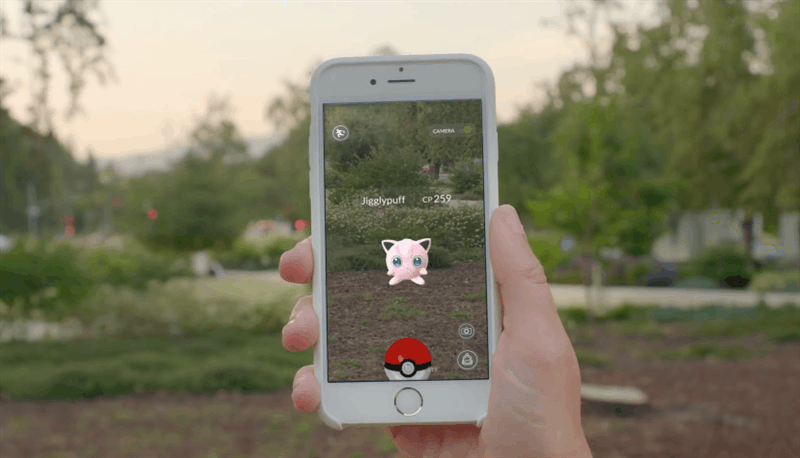
Figura 5: l’app di PokémonGo
Tuttavia, i classici algoritmi di Computer vision da soli non bastano per sopperire ai crescenti requisiti di accuratezza, velocità ed affidabilità che le moderne applicazioni AR richiedono. Lo sviluppo di modelli di intelligenza artificiale sempre più sofisticati ha aperto nuove possibilità anche per la realtà aumentata. Ma perché l’AI è così vantaggiosa? In primo luogo, essa permette di sostituire lunghe e complesse catene di algoritmi classici in serie con un unico modello end-to-end. In secondo luogo, i modelli AI tendono ad avere un comportamento nettamente migliore in condizioni ambientali non ottimali: offrono una soluzione robusta anche in casi di scarsa luminosità, scene controluce, mancanza di sufficiente parallasse. Infine, non necessitano di una fase di calibrazione dei parametri ed offrono architetture sempre più leggere e in grado di essere eseguite su dispositivi a basso consumo energetico e ridotte risorse di calcolo, ottimizzate per l’elaborazione parallela (GPU e TPU).
I modelli di realtà aumentata più utilizzati
Facial Landmarks Extraction
Per le applicazioni che si basano sul volto, si ricorre spesso a modelli di Facial Landmarks Extraction: essi sono in grado di individuare un volto e localizzarne i punti principali quali: pupille, contorno occhi, naso, contorno delle labbra, orecchie, fronte e mento. A differenza della semplice detection dei volti, la conoscenza di questi punti è indispensabile per poter determinare l’orientamento della testa, le proporzioni fisionomiche, la distanza tra fotocamera e utente ed eventuali espressioni facciali. A partire da questi punti, è possibile costruire una mesh virtuale sulla quale poi andare ad applicare maschere, occhiali, cappelli, filtri bellezza e altri artefatti digitali che si muovono in perfetta sincronia con il viso dell’utente. Questa tecnologia viene molto utilizzata nel mondo social: una delle prime app ad introdurla è stata Snapchat.

Figura 6: Modelli AI di Facial Landmarks Extraction. A sinistra output del modello (MLKit-Vision), a destra rendering AR su mesh (Snapchat)
Segmentazione delle immagini
Un’altra tipologia di modelli che ha avuto un grande impatto nell’AR sono i modelli di segmentazione delle immagini. Questi modelli sono in grado non solo di riconoscere e localizzare determinati oggetti all’interno delle immagini, ma anche di delinearne i contorni. Associati ad altre tecniche, permettono di stimarne l’orientamento e la distanza rispetto all’osservatore. Un esempio di utilizzo è quello nel settore della manutenzione: molte case automobilistiche stanno iniziando a proporre servizi di manutenzione guidata da remoto, dove il cliente attraverso specifiche app con accesso alla fotocamera, può vedere evidenziati in tempo reale alcuni componenti della propria auto, arricchiti con utili indicazioni testuali e frecce a supporto di una corretta procedura.
L’utente può quindi fare in autonomia operazioni di comune ordinaria manutenzione anche senza una spiccata conoscenza dei componenti di un’automobile. Nel mondo social e della fotografia, molte app utilizzano modelli di segmentazione per individuare la pelle, i capelli, il background e altre Feature di interesse, al fine di: eliminare lo sfondo o sostituirlo (Selfie Segmentation), dare volume al volto o cambiare ad esempio il colore dei capelli.

Figura 7: Modelli AI di segmentazione con varie classi. (Fonte: Lens Studio)
Pose Estimation
Sono di grande aiuto anche i modelli di Pose Estimation. In generale, questa classe di modelli AI viene addestrata in modo da localizzare il corpo di una persona e tracciarne i movimenti attraverso un numero variabile di landmark in corrispondenza solitamente dei giunti articolari. Sono disponibili sia in versione 2D che 3D, a seconda che ciascun landmark sia costituito da due (x,y) o tre coordinate (x,y,z) spaziali. In questo modo è possibile ricostruire una sorta di scheletro del soggetto ripreso, che può essere successivamente elaborato per fini di realtà aumentata. Un esempio è l’utilizzo di questi modelli per la Motion Capture, una tecnica che permette di registrare i movimenti e trasmetterli ad un personaggio virtuale.

Figura 8: Modelli AI di Pose Estimation. Vengono tracciati nel tempo tutti i movimenti del soggetto ripreso
Hand Tracking
Nella realtà aumentata, particolare attenzione viene data alla modalità di interazione dell’utente con gli oggetti virtuali. Solitamente, la maggior parte delle applicazioni fa uso di controller, comandi vocali o, quando si tratta di smartphone, bottoni e swipe actions. Tuttavia, emerge la necessità di rendere l’esperienza il più reale possibile. Non sarebbe meglio ad esempio, che per spostare gli oggetti si potessero utilizzare le mani anziché delegare a dei comandi? È in questo contesto che si sviluppano i modelli di Hand Tracking. Questi modelli si comportano esattamente come quelli di Pose Estimation, fornendo l’esatta collocazione nello spazio di tutte le articolazioni della mano. La differenza risiede nella notevole complessità dei movimenti che una mano può compiere, nella maggior probabilità di occlusione e nella necessità di un’accuratezza superiore. Si immagini di dover utilizzare una tastiera virtuale per scrivere dei testi: nella maggioranza dei casi le dita che toccano la tastiera non si vedranno nemmeno, i tasti sono piccoli e la velocità di battitura può essere piuttosto elevata. Questo spiega le difficoltà che tali modelli incontrano per poter affinarsi sempre di più ed essere pronti all’uso.
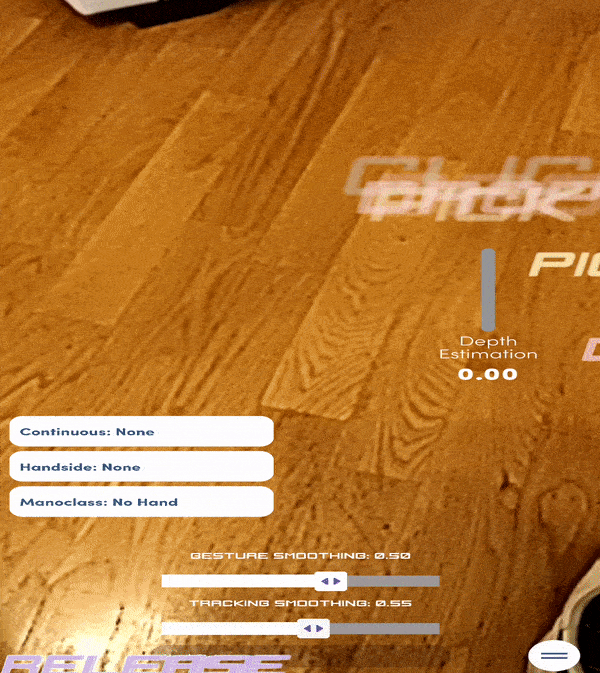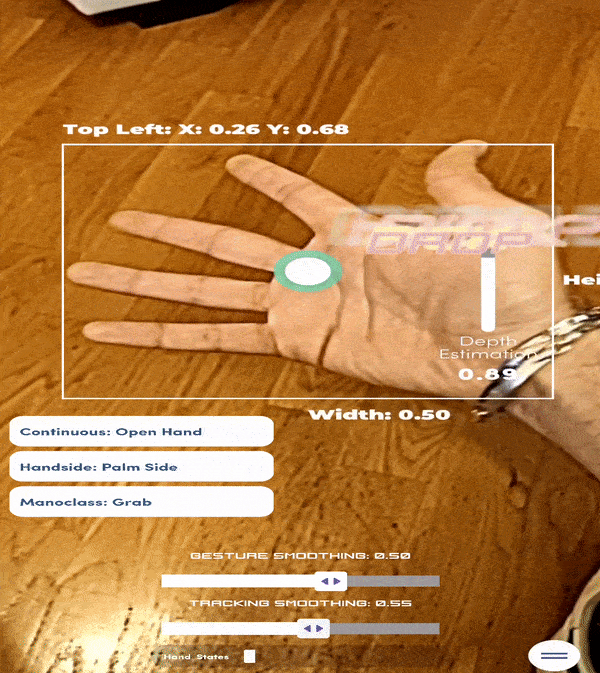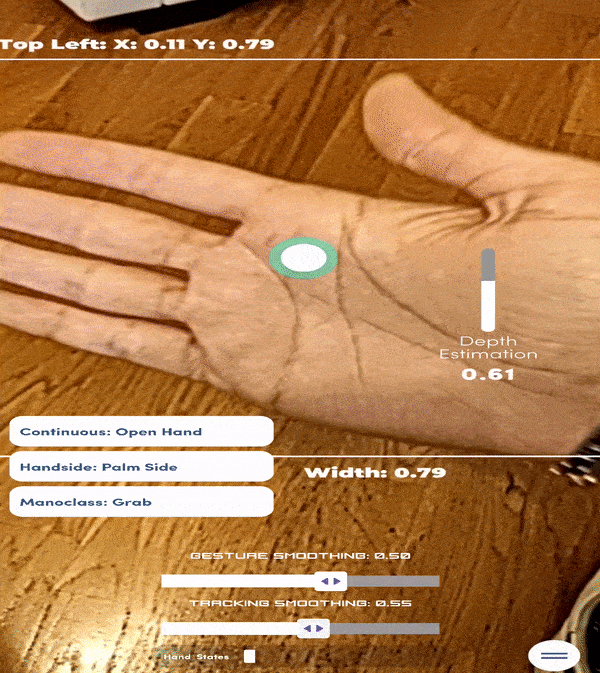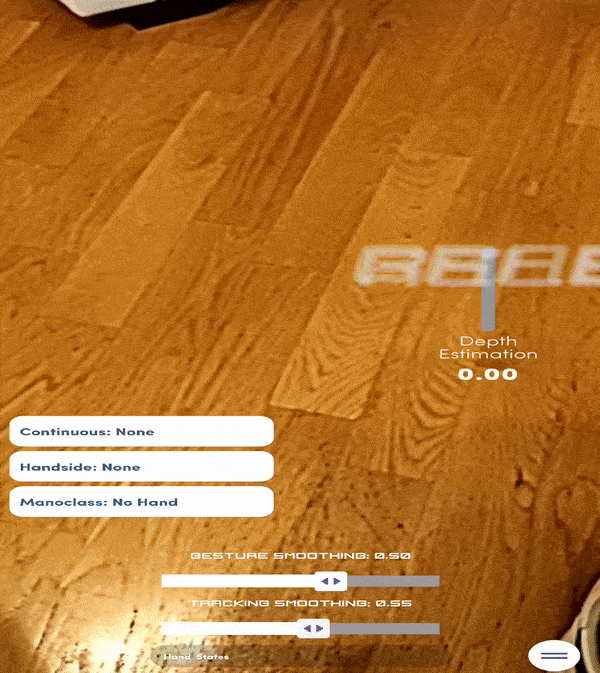
Figura 9: Esempio di modelli AI per il tracciamento delle gesture della mano (app ManoMotion). (Autore: Giovanni Nardini)
Text Detection e Translation
Infine, un’altra tipologia di modelli AI a sostegno della realtà aumentata sono quelli di Text Detection e Translation. Un esempio pratico è l’applicazione Google Lens nella quale, oltre a poter effettuare ricerche per immagine, è possibile usufruire del servizio di traduzione in AR: l’utente inquadra un elemento testuale qualsiasi presente nel mondo fisico (ad es. una copertina di un libro) e l’app individua il testo, lo traduce e lo renderizza sull’oggetto fisico. In questo caso i modelli di Text Detection si occupano della localizzazione del testo all’interno dell’immagine e dell’estrazione delle lettere. Successivamente il dato viene inviato a servizi di NLP adibiti al rilevamento della lingua e alla traduzione. Il resto viene effettuato dal motore grafico AR.
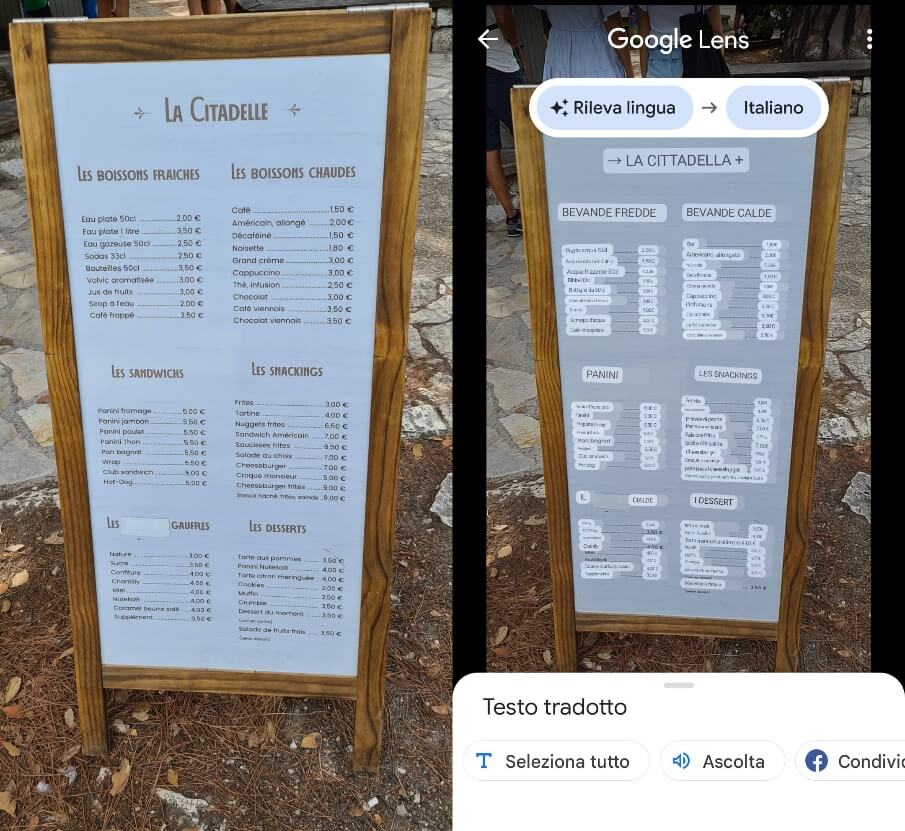
Figura 10: servizio di traduzione in realtà aumentata di Google Lens
Depth Estimation
La mappatura dell’ambiente fisico con le tecniche di Computer Vision classica, tuttavia, non risolve i problemi derivanti dall’occlusione. Se per esempio al centro della scena è presente una colonna e l’applicazione prevede un oggetto in movimento sul pavimento, quest’ultimo sembrerà sempre davanti a qualsiasi oggetto fisico catturato dalla fotocamera, compresa la colonna, anche quando in teoria la sua traiettoria dovrebbe porlo dietro. È qui che entrano in gioco i modelli di Depth Estimation. Tali modelli AI hanno come scopo quello di determinare con una certa accuratezza, la distanza Z tra tutti i punti fisici associati ai pixel dell’immagine e l’obiettivo della fotocamera. In sostanza ciò che viene ottenuta è una mappa di profondità (Depthmap) dove ciascun pixel ha un valore in metri.
Le architetture variano molto e si differenziano principalmente dalla tipologia di Input del modello: alcune utilizzano una singola immagine per generare la depthmap (per cui si parla di Monocular Depth Estimation), altre cercano di superare il margine di errore delle precedenti, aggiungendo una seconda immagine RGB come input (Stereo Depth Estimation), in modo da fornire in modo implicito informazioni preziose sulla parallasse della scena.

Figura 11: Modello AI di Monocular Depth Estimation. A sinistra l’immagine della fotocamera, a destra la Depthmap di profondità. (Autore: Priya Dwivedi)
SLAM (Simultaneous Localization and Mapping)
L’informazione di profondità è di vitale importanza non solo per superare il problema delle occlusioni, ma anche per abilitare nuove interessanti funzionalità: una di queste è la ricostruzione tridimensionale virtuale dell’ambiente reale tramite una tecnica chiamata SLAM (Simultaneous Localization and Mapping).
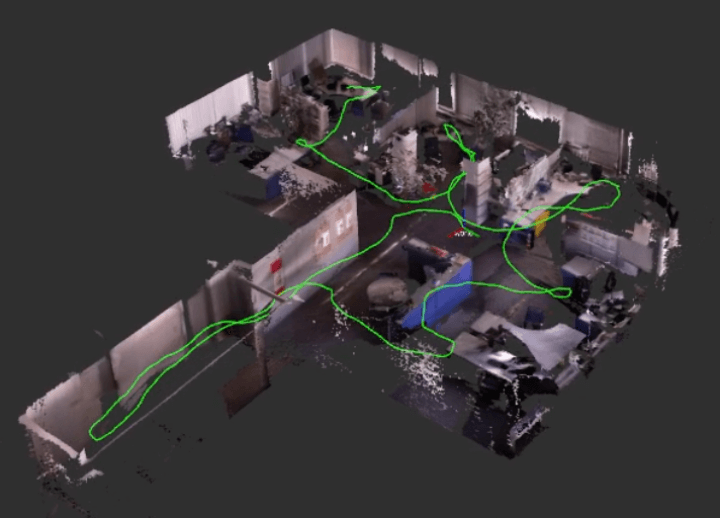
Figura 12: Ricostruzione 3D (Mapping) di un ambiente fisico mediante tecnica SLAM. All’interno della mesh è possibile vedere il percorso compiuto dalla fotocamera (Localization) evidenziato dalla linea verde
L’idea alla base della tecnica SLAM è che l’operazione di mappatura 3D della scena e quella di localizzazione della fotocamera all’interno della mappa migliorano nettamente le loro performance se eseguite simultaneamente con lo scambio continuo delle informazioni elaborate. Gli algoritmi sviluppati in ambito SLAM sono innumerevoli, taluni basati su Computer Vision classica ed altri basati su soluzioni di AI. Molte delle big tech che si occupano di AR e VR hanno investito capitali per riuscire a rendere la tecnica più precisa possibile e meno proibitiva a livello computazionale.
Un esempio di algoritmo SLAM è quello sviluppato da Facebook Reality Labs per il visore Oculus. Attraverso le immagini provenienti dalle telecamere di controllo, poste agli angoli del visore, e i dati inerziali collezionati dalle unità IMU, è possibile costruire una versione 3D della stanza in cui l’utente si trova, localizzando in modo molto preciso la posizione e l’orientamento del visore all’interno di questa ricostruzione. Gli sforzi dei ricercatori stanno portando all’implementazione di un sistema totalmente basato sui AI, dove dati sensoristici e immagini vengano fusi insieme all’interno di un unico modello in grado di sostituirsi al sistema attuale.
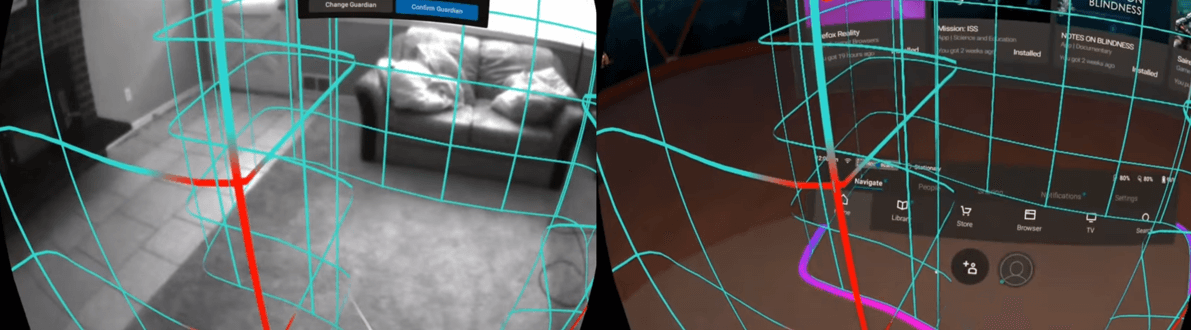
Figura 13: Sistema Oculus Insight. I confini dell’area di gioco vengono disegnati dall’utente sull’ambiente reale; il tutto è possibile grazie alla tecnologia SLAM
Un esempio di come la tecnologia SLAM sia di grande aiuto per la realtà aumentata è il suo utilizzo nell’industria dell’arredamento. Molti brand stanno sviluppando soluzioni che permettono ai clienti di utilizzare lo smartphone (specialmente quelli dotati di sensori di profondità ToF) per ottenere una mappatura 3D della loro casa e poter collocare al suo interno qualsiasi articolo disponibile a catalogo. Il sistema genera un modello in scala reale dell’articolo selezionato e consente all’utente di spostarlo o ruotarlo a proprio piacimento all’interno dell’ambiente domestico e giudicarne la resa.
Le possibilità di sviluppo della realtà aumentata sono davvero tante, e l’intelligenza artificiale gioca un ruolo di primo piano, sia a livello di performance che a livello di efficienza. L’utilizzo dell’AI sarà sempre più frequente e permetterà di abbattere molte barriere tecnologiche attuali, ampliando i confini e le modalità di utilizzo dell’AR.


