
PyTorch 2.0 è finalmente disponibile su larga scala da parte di PyTorch Foundation. Il progetto open source PyTorch è tra le tecnologie più utilizzate per l’addestramento all’apprendimento automatico (ML). Originariamente avviato da Facebook (ora Meta), PyTorch 1.0 è uscito nel 2018 e ha beneficiato di anni di miglioramenti incrementali.
Nel settembre 2022, è stata creata la PyTorch Foundation nel tentativo di consentire una governance più aperta e incoraggiare una maggiore collaborazione e contributi. Il beta di PyTorch 2.0 è uscito in anteprima a dicembre 2022.
PyTorch 2.0 beneficia di 428 diversi collaboratori che hanno fornito nuovo codice e funzionalità allo sforzo open source.
Le prestazioni sono un obiettivo primario per PyTorch 2.0. In effetti, una delle nuove funzionalità chiave è Accelerated Transformers, precedentemente noto come “Better Transformers”. Questi sono al centro dei moderni modelli di linguaggio di grandi dimensioni (LLM) e dell’intelligenza artificiale generativa, consentendo ai modelli di creare connessioni tra concetti diversi.
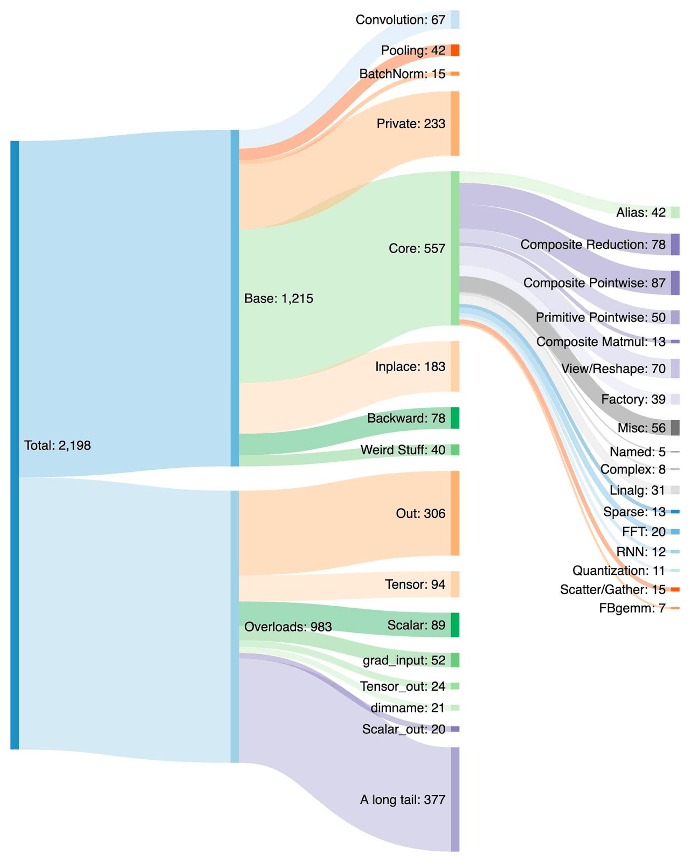
Una ripartizione degli oltre duemila operatori PyTorch
Indice degli argomenti:
Come PyTorch 2.0 accelererà il panorama ML
Uno degli obiettivi del progetto PyTorch è rendere la formazione e l’implementazione di modelli di trasformatori all’avanguardia più semplici e veloci.
I trasformatori sono la tecnologia fondamentale che ha contribuito a rendere possibile l’era dell’AI generativa, compresi i modelli OpenAI come GPT-3 (e ora GPT-4). Nei trasformatori accelerati PyTorch 2.0 è disponibile un supporto ad alte prestazioni per l’addestramento e l’inferenza utilizzando un’architettura kernel personalizzata per un approccio noto come SPDA (Scaled dot product attention).
Poiché esistono diversi tipi di hardware in grado di supportare i trasformatori, PyTorch 2.0 può supportare più kernel personalizzati SDPA. Facendo un ulteriore passo avanti, PyTorch 2.0 integra una logica di selezione del kernel personalizzata che sceglierà il kernel con le prestazioni più elevate per un determinato modello e tipo di hardware.
L’impatto dell’accelerazione non è banale, in quanto consente agli sviluppatori di addestrare i modelli più velocemente rispetto alle precedenti iterazioni di PyTorch.
“Con una sola riga di codice da aggiungere, PyTorch 2.0 offre una velocità tra 1,5x e 2x nell’addestramento dei modelli Transformers”, spiega Sylvain Gugger, manutentore dei trasformatori HuggingFace, in una dichiarazione pubblicata dal progetto PyTorch. “Questa è la cosa più eccitante da quando è stato introdotto l’allenamento di precisione mista!”
Anche Intel guidare il lavoro sul miglioramento di PyTorch per le CPU
Tra i molti contributori di PyTorch 2.0 c’è Intel. Arun Gupta, VP e GM degli ecosistemi aperti di Intel, afferma che la sua azienda è molto favorevole al software open source e al passaggio di PyTorch a un modello di governance aperto nella PyTorch Foundation ospitata dalla Linux Foundation. Gupta fa osservare che Intel è uno dei primi tre contributori di PyTorch ed è attivo all’interno della comunità.
Mentre il lavoro di AI e ML è spesso strettamente associato alle GPU, c’è un ruolo anche per le CPU, e questa è stata un’area di interesse per Intel. Gupta afferma che Intel guida le ottimizzazioni di TorchInductor per le CPU e spiegato che l’ottimizzazione della CPU TorchInductor consente ai vantaggi del nuovo compilatore PyTorch – che fa parte della versione 2.0 – di funzionare sulle CPU.
PyTorch integra anche funzionalità indicate dal progetto come Unified Quantization Backend per piattaforme CPU x86. Il backend unificato offre a PyTorch la possibilità di scegliere la migliore implementazione per la quantizzazione per una piattaforma di addestramento. Intel ha sviluppato la propria tecnologia oneDNN, disponibile anche per la rivale libreria open source TensorFlow ML. Il nuovo backend unificato ha anche il supporto per l’approccio FBGEMM originariamente sviluppato da Facebook / Meta.
“Il vantaggio dell’utente finale è che basta selezionare un singolo backend CPU, con le migliori prestazioni e la migliore portabilità”, afferma Gupta. “Intel vede la compilazione come una potente tecnologia che aiuterà gli utenti di PyTorch a ottenere grandi prestazioni anche quando si eseguono modelli nuovi e innovativi”.


