
In questo periodo in cui è di attualità la transizione digitale e si focalizza l’attenzione sull’intelligenza artificiale, è forse il caso di ripercorrerne alcuni punti chiave per capire che non ci troviamo davanti a una branca completamente nuova e che da molti anni si muove secondo diversi paradigmi, alcuni dei quali sarebbe utile provare a rivalutare. Parliamo soprattutto di linguaggio naturale.
Indice degli argomenti:
Primavere e inverni dell’AI
L’intelligenza artificiale è antica più o meno quanto l’informatica; il primo congresso, quello di Washington, ebbe luogo nel 1969. La specifica branca nota come trattamento del linguaggio naturale risale ai primi programmi di traduzione automatica (anni ‘50).
La sua storia è caratterizzata da un alternarsi incessante di primavere e di inverni (così si chiamano i periodi di crisi). I principali furono segnati da rapporti negativi sui risultati, come il rapporto ALPAC (1966) che stroncò per un certo periodo la ricerca in traduzione automatica, il rapporto Lighthill (1973) che mise in crisi l’intero settore dell’intelligenza artificiale, il progressivo orientamento dell’agenzia DARPA verso la diminuzione dei finanziamenti di progetti applicativi (1971-1973), il crollo negli anni ‘90 dei sistemi esperti, a causa dell’eccessivo costo di mantenimento e aggiornamento.
Gli inverni dell’AI
1966: il fallimento della traduzione automatica
1970: l’abbandono del connessionismo
1971-75: la frustrazione della DARPA con il programma di ricerca sulla comprensione del parlato alla Carnegie Mellon University
1973: forte diminuzione della ricerca dell’AI nel Regno Unito in risposta al rapporto Lighthill
1973-74: il taglio della DARPA alla ricerca accademica generale
1987: il crollo del mercato delle macchine Lisp
1993: sistemi esperti che raggiungono lentamente il fondo
Anni ’90: la tranquilla scomparsa degli obiettivi originali del progetto informatico di quinta generazione e la reputazione generalmente negativa che AI ha avuto da allora.
Quali siano le ragioni di tali inverni è difficile da chiarire. Probabilmente gli addetti ai lavori, gli ‘AI practitioners’, sono stati troppo ottimisti nel presentare i loro prototipi come soluzioni miracolose a problemi in genere enormi, come è stato rimarcato perfino da alcuni ricercatori del settore. Può trattarsi anche di un’eccessiva impazienza del mondo politico ed economico che esigeva risposte immediate e di costo contenuto.
Nell’ambito del linguaggio naturale, la crisi derivò da un lato dal cambiamento di obiettivi, e dall’altro dalla necessità di risparmiare sulla mano d’opera qualificata. I sistemi di trattamento del linguaggio naturale si sono concentrati, fin verso la metà degli anni ‘90, su applicazioni ristrette nel dominio dell’interazione uomo-macchina, della traduzione automatica, della generazione automatica di risposte.
La tecnologia si fondava, principalmente, sull’implementazione di complessi algoritmi che utilizzavano sistemi di regole formali come modelli del comportamento linguistico a tutti i livelli (sintattico, semantico, pragmatico). I risultati furono in genere piuttosto validi, ma molto ristretti e forse sarebbe valsa la pena di approfondire gli studi nella direzione di sistemi di regole più sofisticati. Ma la necessità di interagire con un computer in linguaggio naturale fu presto annullata dall’affermazione sul mercato delle cosiddette interfacce grafiche. Dal versante della traduzione automatica giunse la rinuncia esplicita al requisito base “high quality fully automatic translation”. Tutto questo mentre i problemi che si affacciavano dal mondo del consumo erano la classificazione automatica di testi o la sommarizzazione. Con questo, l’input è divenuto molto voluminoso e in continua evoluzione, e sono emersi con chiarezza i limiti dell’approccio tradizionale. D’altro canto, la produzione di sistemi robusti e funzionali fondati sul vecchio approccio richiedeva l’impegno di personale altamente qualificato come esperti di grammatiche formali, di semantica e logica.
L’era del machine learning
Così in tutti i settori si sono cercate soluzioni poco costose e capaci di trattare input di grandi dimensioni. Ed ecco che, con un salto temporale, giungiamo alle soluzioni dettate dal machine-learning. Si tratta di un approccio che richiede competenze diverse da quelle finora utilizzate nell’ambito dei modelli di linguaggio naturale. È difficile caratterizzare in breve l’approccio attuale, l’apprendimento automatico (deep learning), in quanto si fonda su diverse tecniche. Si può dire, sostanzialmente, che si basa sull’estrazione automatica di schemi di comportamento, anche linguistici, basati su grandi quantità di dati. In pratica, a una certa sequenza di parole si associa un certo comportamento, che può essere una traduzione, una segnalazione di parole significative mediante etichette, il riconoscimento di entità nominate. Naturalmente possono esistere collezioni di dati (corpora) in cui tale associazione è stata operata manualmente e che servono come “istruttori” del sistema di apprendimento. Successivamente, sarà l’utilizzo stesso che metterà in evidenza i casi non trattati, che richiedono un metodo qualsiasi di aggiornamento di quanto è stato appreso. Occorrono quindi competenze di analisi dei dati, di gestione di grandi quantità di dati (big data), di statistiche, di reti neurali, ma in ogni caso si resta “al di fuori” del linguaggio, delle sue sfumature, dei sottintesi e, in ultima analisi, del senso di un testo.
Le domande dell’AI
La domanda che ci dobbiamo porre è se questo approccio, che in ogni caso sta dando alcuni buoni risultati, è adeguato a tutte le applicazioni a cui al momento il trattamento del linguaggio è orientato. In subordine, ci dobbiamo chiedere se non sarà necessario, a un certo punto della nostra evoluzione, mirare a obiettivi più sofisticati.
Per rispondere alla prima domanda inizierei con ricordare una conversazione tra alcuni ‘vecchi’ dell’AI europea e statunitense, cui abbiamo avuto la ventura di partecipare. Se possiamo raffinare i nostri sistemi di ‘learning’ è possibile anche che si debbano mettere a punto sistemi di ‘unlearning’, dal momento che il web ci mette a disposizione una quantità enorme di dati, tra cui ne appaiono di spuri, falsi o sbagliati, che possono essere utilizzati, con qualche sofisticato intervento, per minare certe performance di un sistema a regime.
Inoltre, per quanto i sistemi messi a punto finora siano efficienti e precisi, è molto difficile che possano rispondere a una domanda fondamentale, “perché mi dai questa risposta?”, che richiederebbe l’attivazione di complesse catene causali.
Un altro argomento che evidenzia la differenza tra elaborare delle parole e capire il linguaggio naturale è la flessibilità dell’interazione. Molti di noi hanno dovuto confrontarsi con la rigidità di certi sistemi d’interazione (ad es. telefonica) o con sistemi di classificazione grossolani. Qualche anno fa, una mia collega italianista non ricevette nessuna informazione su un congresso su “sesso in letteratura”, perché i sistemi di controllo identificarono il titolo come connesso con il pericolo di accesso a siti pornografici. Oggi i sistemi sono sicuramente più sofisticati, ma non si può mai escludere che un caso simile possa ripresentarsi.
Ne possiamo concludere, quindi, che anche i migliori sistemi fondati sul learning possono essere indefinitamente migliorati.
Per rispondere alla seconda domanda, invece, dovremo chiederci se i servizi forniti dagli attuali prodotti che reclamano l’attuazione di tecniche di AI soddisfino completamente le nostre esigenze presenti e, soprattutto, future. Al momento, compiere una ricerca su Google richiede l’uso di parole appropriate come chiavi; ma se un utente non ha un’idea chiara può usare parole non precise, che non hanno nessuna attinenza a quelle necessarie. Non sarà opportuno prevedere un sistema di riconoscimento delle intenzioni di quell’utente? Siamo sicuri di interagire in maniera “naturale” con i receptionist robot? Non chiederemmo ai social robot un’interazione più “simpatica”? Non vorremmo che le risposte generate dai sistemi di ricerca fossero più flessibili e più adattate al contesto in cui vengono date? Non vorremmo che l’intuizione dei nostri obiettivi nell’utilizzo di un servizio informatico fosse più completa del semplice user’s modelling?
Tutte queste domande rinviano certamente non solo alla forma della frase o del testo, ma a tutto ciò che ne costituisce il contenuto, includendo ciò che non è esplicito nell’enunciato linguistico.
Linguaggio naturale: la differenza fra NLP e NLU
È forse utile, a questo punto, chiarire meglio la differenza tra NLP e NLU. Il primo, Natural Language Processing, si riferisce a tutte quelle tecniche di trattamento del linguaggio che si inseriscano in applicazioni efficienti e utili. Al contrario Natural Language Understanding presume una reale “comprensione” dell’input linguistico cui si associa la capacità di calcolare reazioni e risposte complesse, simili a quelle umane. Va precisato che l’attuale modello di NLP, fondato sull’apprendimento, si ispira al paradigma del Probably Approximatively Correct, contando sul fatto che anche nell’interazione tra umani, l’approssimazione trova una sua degna collocazione.
Ma mettere a punto sistemi del tipo “fondati su regole”, “cognitivamente motivati”, o come altro si vogliano chiamare è certamente più difficile e più costoso in termini di tempo di ricerca e qualificazione degli addetti ai lavori.
Partiamo dalla difficoltà principe: il “fenomeno del testo mancante” (MTP), che riteniamo sia al centro di tutte le sfide nella comprensione del linguaggio naturale. La comunicazione linguistica avviene come mostrato nell’immagine qui sotto: un parlante codifica un pensiero come un’espressione linguistica in un linguaggio naturale, e l’ascoltatore quindi decodifica quell’espressione linguistica nel pensiero che l’oratore intendeva trasmettere!
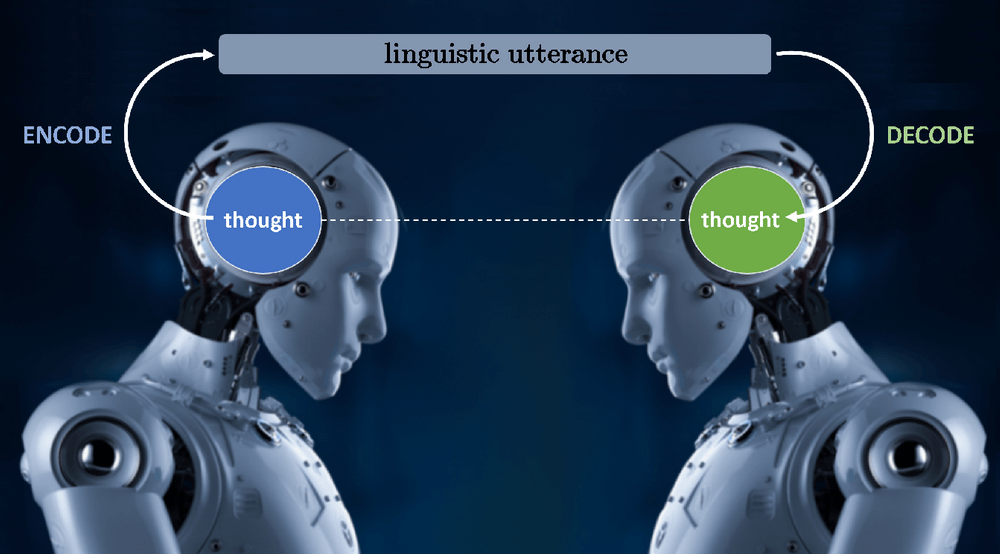
Altre difficoltà ben note in NLU sono mostrate (solo alcune) in figura 3 – dove il problema nella linguistica computazionale è indicato con l’etichetta e il testo mancante evidenziato in rosso.

Fonte Walid Saba
Nessun approccio di Machine Learning può risolvere i problemi elencati sopra. Infatti, come già accennato, il paradigma sottostante a tali approcci è quello semplicistico <stimolo – reazione>, che in fondo era lo stesso paradigma dei primi sistemi di Question-answering (anni ‘60 e ‘70). Quello che manca è un salto verso un paradigma fondato sul ciclo della comunicazione, che richiede l’utilizzo di un modello cognitivamente fondato, secondo cui un input linguistico è solo la chiave d’ingresso a un intero mondo concettuale nella testa dell’utente. Un approccio che focalizza più l’intenzione sottostante a una domanda che non il rapporto domanda-risposta. È probabile che un tale modello non sia utile per semplici sistemi di categorizzazione di testi, ma sarebbe già indubbiamente più applicabile nella Sentiment Analysis o nel riconoscere il linguaggio figurato e intenderne il senso implicito (è forse un caso che la IARPA – Intelligence Advanced Research Project Activity finanzi un progetto sulla metafora?).
Empirismo e razionalismo
John R. Pierce, lo scienziato che nel 1964 stroncò i finanziamenti per la machine translation (a ragion veduta), definiva quello dell’apprendimento automatico e del riconoscimento vocale belle applicazioni di pattern matching, di euristiche approssimanti, di “inganno abile-artful deception che sono adatti a riuscire meglio e più rapidamente della scienza”.
Non bisogna vendere la scienza come qualcosa di diverso da quello che è (ad esempio, applicazioni). Il lavoro applicato dovrebbe essere valutato come lavoro applicato (basato su casi aziendali) e la scienza dovrebbe essere valutata come scienza (basata su una revisione peer to peer)
Le due aree sono distinte: la ricerca accademica di base, a lungo termine, è quella della linguistica; quella del lavoro pratico, la linguistica computazionale, ricerca applicata, caratterizzata dal breve termine ad es. ricerca applicata per migliorare la traduzione automatica.
Le proposte nella prima area dovrebbero essere valutate da un’analisi approfondita sulla base del merito scientifico, mentre le applicazioni nella seconda area dovrebbero essere valutate in termini di altre metriche: velocità, costi, ricavi…
Se Pierce fosse vivo oggi sarebbe profondamente infastidito dallo stato attuale della scienza, che investe molto in tecniche di valutazioni numeriche che distraggono il campo da quelle che considererebbe le domande scientifiche fondamentali.
Allo stato dell’arte dopo le stagioni dell’empirismo e del razionalismo, con una continua oscillazione, tra le due posizioni, vale la inesorabile legge che coloro che ignorano la storia dei diversi approcci e dei risultati conseguiti, sono condannati a riviverla.
1950: approccio Empiristico (Shannon, Skinner, Firth, Harris).
Anni ‘70: razionalismo (Chomsky, Minsky).
Anni ‘90: approccio Empiristico (IBM SpeechGroup, AT&T BellLabs).
Anni 2010: ritorno al Razionalismo?
Conclusioni
Naturalmente sarebbe stupido buttare il bambino con l’acqua sporca, cioè rinunciare a quanto di buono il modello Machine learning ha prodotto. Piuttosto il modello del futuro dovrebbe essere un ritorno ai modelli dettati dal razionalismo, sistemi basati su regole, ma associate e controllate da dati derivanti dall’apprendimento. Per realizzare questo modello il percorso è chiaro, ma difficile: occorre che si colmino le lacune delle scienze di base come la linguistica e la logica, che si studino meglio i processi di apprendimento umani, che riescono ad integrare i due percorsi, occorre, in ultima analisi, migliorare il rapporto tra ricerca di base e ricerca applicata.
Ma sarà destinata a sopravvivere la ricerca di base sulla linguistica se un professore che fa ricerche fondamentali guadagna in Italia qualche migliaio di euro al mese mentre gli smanettoni senior del Natural Language Processing viaggiano su salari di 300mila dollari l’anno?



