
La teoria dei giochi è una branca della matematica utilizzata per modellare l’interazione strategica tra diversi giocatori in un contesto con regole e risultati predefiniti.
La teoria dei giochi può essere applicata in diversi ambiti dell’intelligenza artificiale:
– sistemi di intelligenza artificiale multi-agente.
– apprendimento dell’imitazione e del rinforzo.
– addestramento sugli avversari nelle reti generative degli avversari (GAN).
La teoria dei giochi può anche essere usata per descrivere molte situazioni nella nostra vita quotidiana e nei modelli di apprendimento automatico.
Ad esempio, un algoritmo di classificazione come SVM (Support Vector Machines) può essere spiegato come se fosse un gioco a due attori in cui un giocatore sta sfidando l’altro a trovare il miglior iperpiano che gli dia i punti più difficili da classificare. Il gioco converge in una soluzione che sarà un compromesso tra le abilità strategiche dei due giocatori (tanto più il primo giocatore sarà bravo a sfidare il secondo attore nel classificare punti dati difficili, tanto più il secondo giocatore dovrà essere abile nell’identificare i limiti della decisione migliore).
Indice degli argomenti:
Cos’è la teoria dei giochi
La teoria dei giochi può essere divisa in 5 tipi principali di giochi:
1) Giochi cooperativi contro giochi non cooperativi: nei giochi cooperativi i partecipanti possono stabilire alleanze al fine di massimizzare le loro possibilità di vincere la partita (ricorrendo ad esempio a delle trattative). Nei giochi non cooperativi i partecipanti non possono invece formare alleanze (come ad esempio nelle guerre).
2) Giochi simmetrici contro giochi asimmetrici: in una partita simmetrica tutti i partecipanti hanno gli stessi obiettivi e solo le loro strategie messe in atto per raggiungerli determineranno chi vince la partita (ne è un esempio classico il gioco degli Scacchi). Nei giochi asimmetrici invece, i partecipanti hanno obiettivi diversi o contrastanti.
3) Giochi di informazione perfetta contro giochi di informazione imperfetta: nei giochi di informazione perfetta tutti i giocatori possono vedere le mosse degli altri giocatori (come negli Scacchi). Invece, nei giochi con informazioni imperfette, le mosse degli altri giocatori sono nascoste (come ad esempio nei principali giochi di carte).
4) Giochi simultanei e giochi sequenziali: nei giochi simultanei i diversi giocatori possono intraprendere azioni contemporaneamente. Nei giochi sequenziali, al contrario, ogni giocatore è a conoscenza delle precedenti azioni degli altri giocatori (cosa che avviene per esempio nei comuni giochi da tavolo).
5) Giochi a somma zero contro giochi a somma non zero: nei giochi a somma zero un giocatore che guadagna qualcosa provoca una perdita agli altri giocatori. Nei giochi con somma diversa da zero, invece, più giocatori possono trarre vantaggio dai guadagni di un altro giocatore.
Diversi aspetti della teoria dei giochi sono comunemente usati nell’intelligenza artificiale, come ad esempio Nash Equilibrium, Inverse Game Theory. Nei prossimi paragrafi spiego perché fornendo anche qualche caso pratico.
Nash Equilibrium, l’equilibrio di Nash applicato all’intelligenza artificiale
L’equilibrio di Nash è una condizione in cui tutti i giocatori coinvolti nel gioco concordano sul fatto che non c’è soluzione migliore per il gioco se non quella della situazione reale in cui si trovano in quel dato punto/momento. In altre parole, nessuno dei giocatori avrebbe un vantaggio nel cambiare la propria strategia attuale (in base alle decisioni prese dagli altri giocatori).
Tornando all’esempio di prima (l’algoritmo di classificazione SVM), l’equilibrio di Nash si verifica quando il classificatore SVM concorda su quale iperpiano utilizzare per classificare i nostri dati.
Uno degli esempi più comuni usati per spiegare l’equilibrio di Nash è il dilemma del prigioniero. Immaginiamo che due criminali vengano arrestati e tenuti in isolamento senza avere alcuna possibilità di comunicare tra loro (Figura 2):
– se uno dei due prigionieri confesserà che l’altro ha commesso un crimine, il primo verrà liberato mentre l’altro passerà 10 anni in prigione;
– se nessuno dei due confessa, trascorrono solo un anno in prigione per ciascuno;
– se entrambi confessano, invece trascorrono entrambi 5 anni in prigione.

In questo caso, l’equilibrio di Nash viene raggiunto quando entrambi i criminali si tradiscono.
Un modo semplice per scoprire se una partita ha raggiunto un equilibrio di Nash può essere quello di rivelare la tua strategia ai tuoi avversari. Se dopo la tua rivelazione nessuno di loro cambia la propria strategia, l’equilibrio di Nash è dimostrato.
Sfortunatamente, un equilibrio di Nash è più facile da ottenere nei giochi simmetrici che asimmetrici. Un limite per poterlo applicare all’AI: i giochi asimmetrici sono infatti i più comuni nelle applicazioni del mondo reale e nell’intelligenza artificiale.
Inverse game theory, la teoria dei giochi “inversa” importante per l’AI
La teoria dei giochi mira a comprendere le dinamiche di un gioco per ottimizzare il possibile risultato dei suoi giocatori. L’inverse game theory, la cosiddetta teoria dei giochi “inversa”, mira invece a progettare un gioco basato sulle strategie e gli obiettivi dei giocatori. La teoria dei giochi inversi svolge un ruolo importante nella progettazione di ambienti degli agenti di intelligenza artificiale.
Esempi pratici di teoria dei giochi applicata ad alcuni ambiti dell’intelligenza artificiale
Addestramento dell’avversario nella GAN, Generative Adversarial Network (rete generativa avversaria)
Una rete generativa avversaria è composta da due componenti: un modello generativo, o generatore, un modello discriminativo, o discriminatore, entrambi realizzati tramite reti neurali.
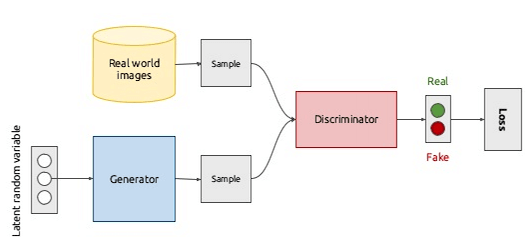
I modelli generativi prendono come input alcune funzionalità, esaminano le loro distribuzioni e cercano di capire come sono state prodotte. Alcuni esempi di modelli generativi sono Hidden Markov Models (HMMs) e Restricted Boltzmann Machines (RBMs).
I modelli discriminatori utilizzano invece le funzionalità di input per prevedere a quale classe potrebbe appartenere un campione. Support Vector Machines (SVM) è un esempio di modello discriminante.
Nelle GAN, il modello generativo utilizza le funzionalità di input per creare nuovi campioni che mirano ad assomigliare abbastanza da vicino alle caratteristiche principali dei campioni originali. I campioni generati vengono quindi passati con quelli originali al modello discriminatorio che deve riconoscere quali campioni sono autentici e quali sono falsi.
Un’applicazione di esempio di GAN può essere quella di generare immagini e quindi distinguere tra quelle reali e false.

Questo processo ricorda abbastanza da vicino le dinamiche di un gioco. In questo gioco, i nostri giocatori (i due modelli) si sfidano a vicenda. Il primo crea campioni falsi per confondere l’altro, mentre il secondo giocatore cerca sempre meglio di identificare i campioni giusti.
Questo gioco viene quindi ripetuto in modo iterativo e in ogni iterazione, i parametri di apprendimento vengono aggiornati al fine di ridurre la perdita complessiva. Questo processo continuerà fino al raggiungimento dell’equilibrio di Nash (i due modelli diventano competenti nell’esecuzione dei loro compiti e non sono più in grado di migliorare).
Multi-Agents Reinforcement Learning (MARL)
Il cosiddetto Reinforcement Learning (RL) mira a far apprendere un agente (il nostro “modello”) attraverso l’interazione con un ambiente (può essere virtuale o reale).
Il Reinforcement Learning è stato inizialmente sviluppato per aderire ai processi decisionali di Markov (framework matematico per la modellizzazione del processo decisionale in situazioni in cui i risultati sono in parte casuale e in parte sotto il controllo decisionale – fonte Wikipedia). In questo ambito, un agente viene posto in un ambiente stocastico stazionario e cerca di apprendere una politica attraverso un meccanismo di ricompensa/punizione. In questo scenario, è dimostrato che l’agente converge in una politica soddisfacente.
Tuttavia, se più agenti vengono inseriti nello stesso ambiente, questa condizione non è più vera. In effetti, nel primo scenario l’apprendimento dell’agente dipende solo dall’interazione tra l’agente e l’ambiente, nel secondo scenario (dove ci sono più agenti) l’apprendimento dipende anche dall’interazione tra agenti.

Immaginiamo che stiamo cercando di migliorare il flusso del traffico in una città usando un gruppo di auto a guida autonoma alimentate dall’intelligenza artificiale. Da sola, ciascuna delle auto può interagire perfettamente con l’ambiente esterno, ma le cose possono diventare più complicate se vogliamo “far pensare” le auto in gruppo. Ad esempio, un’auto potrebbe entrare in conflitto con un’altra perché per entrambi è più conveniente seguire un determinato percorso.
Questa situazione può essere facilmente modellata usando la teoria dei giochi. In questo caso, le nostre auto rappresenterebbero i diversi giocatori e l’equilibrio di Nash il punto di equilibrio tra la collaborazione delle diverse auto.
La modellazione di sistemi con un gran numero di agenti può diventare un compito davvero difficile. Questo perché aumentando il numero di agenti, aumenta esponenzialmente il numero di possibili modi in cui i diversi agenti interagiscono tra loro.
In questi casi, la modellazione di modelli di apprendimento di rinforzo multi-agente con scenari di campo medio (MFS) potrebbe essere la soluzione migliore. Gli scenari sul campo medio possono, infatti, ridurre la complessità dei modelli MARL rendendo a priori il presupposto che tutti gli agenti abbiano funzioni di ricompensa simili.
***

*Pier Paolo Ippolito è uno studente all’ultimo anno del master in Intelligenza Artificiale all’Università di Southampton, Regno Unito. E’ anche Microsoft Ambassador e organizza Workshop, Hackathons ed eventi usando la tecnologia Microsoft Azure. E’ un editor di Towards Data Science dove è stato pubblicata anche la versione originale (in inglese) di questo articolo.


