
Si sente spesso citare il termine AI (Artificial Intelligence o intelligenza artificiale) in modo abusato, fuori luogo. È necessario perciò dare una definizione chiara di cosa sia un’AI.
Il concetto è composto da due termini: “artificial” e “intelligence”. Il primo si riferisce a qualcosa che non è presente in natura, non è tipicamente generato da un essere umano. Non si parla quindi necessariamente di un sistema: ad esempio, un software si può considerare come un artefatto artificiale, perchè non presente in natura ma generato da un essere umano, lo sviluppatore.
Per spiegare il concetto di intelligenza, ci piace molto questa definizione: “alcuni identificano l’intelligenza (in questo caso l’intelligenza pratica) come la capacità di un agente di affrontare e risolvere con successo situazioni e problemi nuovi o sconosciuti; nel caso dell’uomo e degli animali, l’intelligenza pare inoltre identificabile anche come il complesso di tutte quelle facoltà di tipo cognitivo o emotivo che concorrono o concorrerebbero a tale capacità. Per alcune scuole di pensiero, soprattutto antiche, la sede dell’intelligenza non è il cervello e la si identifica come la qualità, esclusivamente umana, di capire un fenomeno e le sue relazioni con tutti gli aspetti non apparenti che interagiscono con tale fenomeno, la capacità quindi di leggervi dentro”. (fonte Wikipedia)
L’intelligenza si contrappone alla saggezza: la prima è quanto sopra, la seconda fa riferimento all’esperienza che si trasforma in un bagaglio culturale che diventa strumento decisionale (cosa non automatica).
L’AI, quindi, è lo studio di come “formare” i computer perché possano fare cose (tipicamente prendere decisioni) che al momento gli uomini sanno prendere meglio dei computer, migliorando nel tempo in autonomia.
Indice degli argomenti:
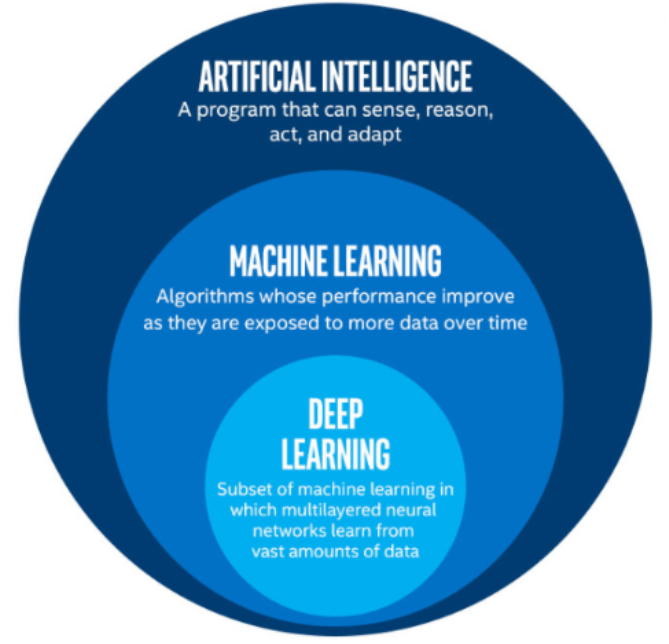
Intelligenza artificiale e Machine Learning
Una confusione tipica dei nostri tempi è accomunare AI e ML (Machine Learning).
Machine Learning è il processo di apprendimento mediante il quale le macchine posso apprendere senza essere programmate per fare una determinata azione. Si tratta di un’applicazione dell’AI che permette alle macchine di imparare e migliorare le loro decisioni nel tempo, accumulando esperienza. Più scientificamente, una macchina (spesso si pensa a oggetti fisici ma tipicamente ci si riferisce ad algoritmi) impara quando dato un task T, la funzione di Performance P, migliora nel tempo.
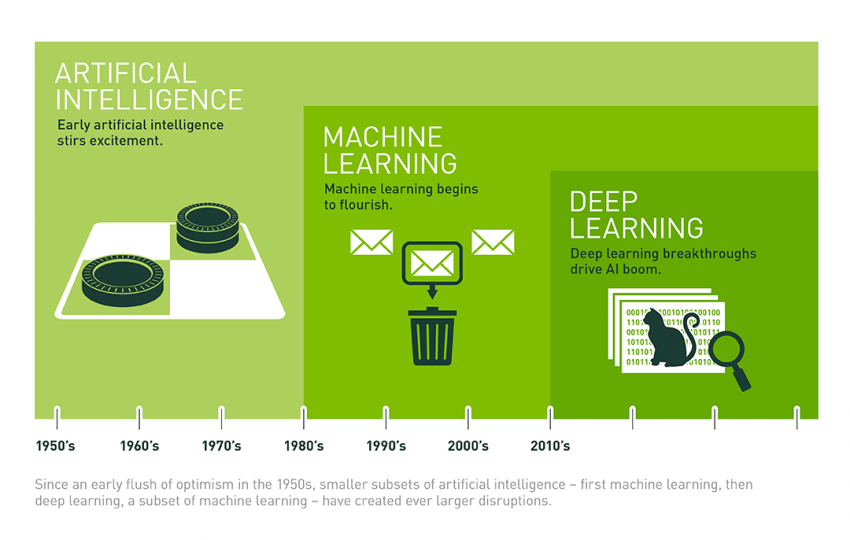
Sia l’AI che la ML non sono invenzioni di questi ultimi anni. Chi scrive è stato l’autore di una tesi, nel 2003, su machine learning, in particolare su un algoritmo di miglioramento per la clusterizzazione di oggetti definiti da vettori di informazioni (miglioramento di P nel task T=clusterizzazione).
All’epoca era difficile trovare set di informazioni utili all’apprendimento, perchè l’algoritmo di apprendimento, una volta definito, aveva bisogno di imparare e per imparare aveva bisogno di dati. I dati inoltre dovevano essere strutturati, quindi si presero dataset conosciuti alla comunità scientifica, che venivano usati per sviluppare algoritmi migliorativi a partire da basi di dati comuni.
E proprio i dati sono una delle spiegazioni più evidenti del recente boom dell’AI. Si dice che ognuno di noi, per esempio, sia rappresentato da almeno 300 caratteristiche nei database delle big del tech, ovvero sia rappresentato da 300 dati di tipo diverso (numeri, stringhe, record, vettori, timbro voce, modo di scrivere, altro). Si tratta quindi di dati parzialmente strutturati (presi da fonti diverse ma uniti da un senso: rappresentare me). Il machine learning in generale, che tipicamente usa metodi statistici, non è la tecnica migliore per i dati destrutturati, o parzialmente strutturati, mentre lavora bene per cogliere “gruppi somiglianti” (cluster) laddove ci sia una struttura informativa, perché riconosce il vettore che rappresenta il singolo dato come un oggetto in uno spazio multidimensionale e riesce a trovare gruppi statisticamente affini in questo spazio.
Nei dati destrutturati, non c’è una dimensionalità multispaziale, ma solo dei dati da cui bisogna “minare” (mining) informazioni.
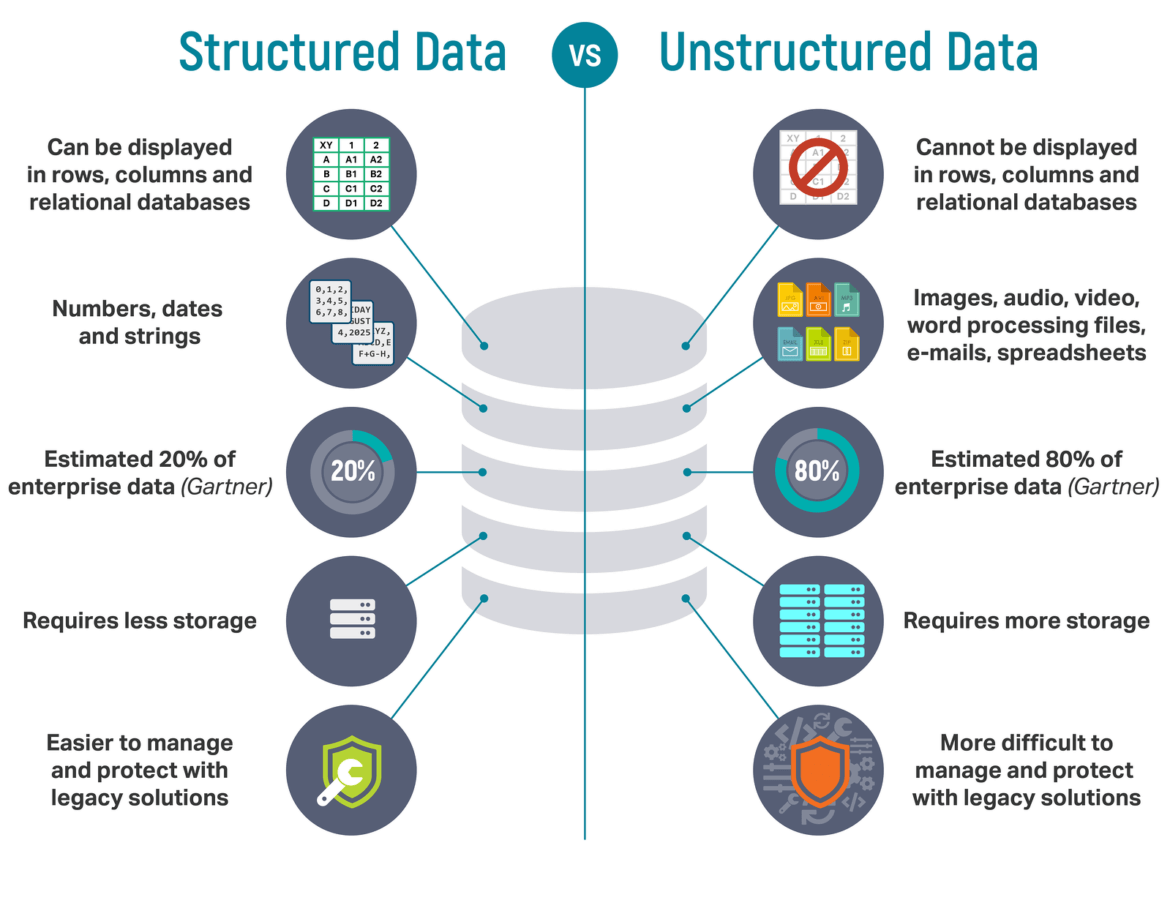
Entriamo quindi nel mondo del big data (il mondo dei dati destrutturati è molto più ampio di quello strutturati), ma non solo tanti dati, anche che cambiano velocemente e che arrivano sempre freschi in un flusso continuo.

Come possiamo processare questi dati destrutturati velocemente e in quantità così importante? Viene in soccorso il boom del deep learning (secondo aspetto che ha permesso l’esplosione dell’AI, e che è una “tecnica” di machine learning). Anche le reti neurali, che sono alla base del deep learning, non sono un’invenzione recente. Sono il tentativo di replicare il meccanismo del cervello mediante reti di neuroni (piccolo oggetti software che ricevuto un input danno un output secondo un’equazione detta transfer function).
Una rete neurale è molto semplice: un livello di input, un livello di output, e un livello hidden intermedio. Nel livello hidden ci sono i neuroni che processano l’input e generano l’output. Tipicamente una rete neurale viene “allenata” con un set di esempio in modo da far imparare ai neuroni che output generare in base all’input e poi quando la rete “ha capito”, può proseguire da sola, evolvendo progressivamente in base all’input ricevuto. È come se una volta fatta una configurazione iniziale, questa possa dare il risultato voluto ma anche evolvere nel tempo.
Nel deep learning i livelli hidden aumentano, in modo che l’input venga processato a più livelli, come avviene nel cervello umano. L’apprendimento diventa quindi più articolato e la rete è in grado di fare “ragionamenti” e di “apprendere” concetti più complessi, ovvero di prendere decisioni “output” più complesse.
L’AI ha bisogno di processori più potenti e veloci
Perchè il deep learning ha preso piede solo oggi? Non si poteva fare deep learning anche “ieri”, visto che le neural net erano già conosciute?
Dal 2015, sul mercato sono state rese disponibili le Gpu ovvero processori in grado di rendere il calcolo parallelo più veloce, meno costoso e più potente. Questo ha permesso di implementare reti neurali sempre più potenti, o deep, che hanno anche la caratteristica di poter apprendere da sole (senza che venga loro dato in pasto un set di esempio, nell’unsupervised learning) e soprattutto grazie alla potenza di calcolo disponibile di poter essere eseguite continuamente e non una tantum.
Questo aiuta nell’ambito degli unstructured data, con unsupervised learning, a trovare pattern (percorsi) interessanti nei dati che continuamente fluiscono sempre freschi. Se a questo sommiamo il flusso continuo di dati, immagini, text, transazioni, mappatura dei dati, tag, connessioni, trasferimenti, digitalizzazione degli ultimi anni, possiamo capire come l’AI possa essere una delle tecnologie centrali oggi e disruptive nel prossimo decennio.


