
Nel campo dell’Intelligenza Artificiale, pur costruendo i migliori algoritmi di Machine Learning oppure la più performante Rete Neurale, la qualità del prodotto finale è basata sull’affidabilità dei dati coi quali viene allenata.
Indice degli argomenti:
Affidarsi ad un AI significa affidarsi al database con il quale viene addestrata
Per capire meglio questo concetto, riprendo un pezzo scritto in un mio articolo precedente pubblicato su AI4Business: Blockchain e Intelligenza Artificiale – La corsa all’oro nella validazione dei dati
“In questo ambito la quantità e la qualità dei dati sono cruciali ed affidarsi ad algoritmi di Artificial Intelligence – AI con dati manipolabili è pericolosissimo per un qualsiasi ente. Gli ambiti dove sono stati riscossi i migliori risultati in ambito AI difatti sono ecosistemi chiusi, non manipolabili e ben delineati, come videogame… In ambienti complessi come social media o big data, gli algoritmi odierni di AI hanno risultati meno performanti o addirittura pericolosamente errati”.
In ambienti con script ben definiti e limitati, come i videogiochi, è possibile addestrare un’IA basata su un numero limitato di azioni predefinite, leggendo il codice del gioco. In questo tipo di ambiente, gli algoritmi di apprendimento automatico possono prendere decisioni basate non solo su input (dati) ma sulla tipologia dell’input (script), capendo così la qualità dell’interazione e del risultato.
In ambienti aperti e non delineati, le cose sono un pò più complicate. Ad esempio, nei social media gli algoritmi di AI devono fare i conti con notizie false, dati auto referenziali, bot e così via. In ambienti di questo tipo è possibile creare algoritmi che sono abbastanza intelligenti da riconoscere e valutare alcune delle problematiche elencate precedentemente, ma con una spesa in termini di potere computazionale eccessive nell’eseguire calcoli complessi e con una percentuale di errore altissima.

Gli algoritmi di intelligenza artificiale più utili e performanti in ambienti aperti vengono utilizzati e sviluppati dalla stessa compagnia proprietaria di una piattaforma di riferimento e del suo database. Infatti, il vantaggio che ha una piattaforma proprietaria nell’utilizzare algoritmi di AI basati sul proprio database è di conoscere gli script che vengono utilizzati quando ogni singolo dato viene generato, il che gli permette di capire di default la qualità di ogni singolo dato generato e di conseguenza quanto affidarsi ad esso.
Secondo Tomas C. Redman in un articolo pubblicato su Harvard Business Review “If Your Data Is Bad, Your Machine Learning Tools Are Useless”:
“Una bassa qualità di dati è il nemico numero uno ad una diffusione profittevole della tecnologia di Machine Learning. L’osservazione, “immondizia, spazzatura” ha afflitto l’analisi e il processo decisionale per generazioni, ed è molto più significativo per tecnologie di apprendimento automatico.”
Lo scenario moderno di tecnologie di Intelligenza Artificiale in sintesi è determinato dai dati sulle quali vengono allenati gli algoritmi, rendendo più performanti compagnie con grandi moli di dati proprietari e con la proprietà degli script, quindi di conseguenza un riconoscimento qualitativo di essi, a discapito di compagnie con una mole bassa di dati ed allo stesso momento basate su integrazioni di database esterni. Il che delimita un monopolio in questa tecnologia totalmente irraggiungibile per nuovi attori sul mercato.
Sorvolando questa problematica, la situazione odierna che rende pericoloso affidarsi ad algoritmi di intelligenza artificiale, nasconde tre domande da porsi ben più terrificanti ed irrisolvibili per un fattore tecnologico del web centralizzato.
Affidarsi ad algoritmi di intelligenza artificiale: 3 domande da porsi
Jeremy Epstein ha scritto in un articolo su Venture Beat: “Why you want blockchain-based AI, even if you don’t know it yet”:
“Se hai fiducia nel tuo processo decisionale verso una fonte di IA centralizzata, devi avere il 100% di fiducia in:
1- L’integrità e la sicurezza dei dati (gli input sono accurati e affidabili e possono essere manipolati o rubati?
2) Gli algoritmi di apprendimento automatico che informano l’IA (sono inclini a errori o bias eccessivi e possono essere controllati?)
3- L’interfaccia dell’IA (rappresenta in modo affidabile l’output dell’IA e acquisisce in modo efficace nuovi dati?)”
Inizio questa analisi con questa affermazione: “Affidarsi ad un intelligenza artificiale basata su dati centralizzati è una scelta altamente pericolosa!” Nel momento nel quale noi ci affidiamo ad una tecnologia di Intelligenza Artificiale, ci stiamo in realtà affidando ai dati con i quali viene allenata.
Domanda 1: il database può essere manipolato?
La prima domanda da porsi è “è possibile che il database a cui mi affido possa essere manipolato da un ente per una qualunque ragione?” In breve, è affidabile eseguire scelte basate su un database che può essere manipolato sia dalla compagnia proprietaria che da hackers esterni?
Maria Korolov intervistando vari CTO di compagnie di Intelligenza Artificiale in un articolo di CIO Magazine “AI’s biggest risk factor: Data gone wrong” sottolinea:
“Raccogliere, classificare ed etichettare set di dati, utilizzati per addestrare gli algoritmi di AI è un lavoro difficile, soprattutto in dataset abbastanza complessi da riflettere il mondo reale. Anche se disponi dei dati, puoi comunque riscontrare problemi con la sua qualità, così come pregiudizi nascosti nei tuoi set di allenamento. Questi tipi di pregiudizi intrinseci possono essere difficili da identificare in più ci sono anche fonti di dati che cercano attivamente di rovinare i risultati. Prendi la diffusione di notizie false sui social media, ad esempio, dove il problema sta peggiorando.”
Domanda 2: chi detiene i dati ha il potere?
La seconda domanda da porsi è “Chi detiene i dati, ha il potere di dominare tutto?”
Nel caso in cui un ente detiene il dataset ed un altro ente affida le proprie decisioni attraverso algoritmi di AI che utilizzano i dati del primo, tecnicamente e letteralmente il primo ente ha il potere di dominare il secondo. Per esempio, oggi la maggior parte dei business stanno dando fiducia a ciò che viene definito “FAANG” (Facebook, Amazon, Apple, Netflix e Google), ovvero il cartello di dataset delle “Big Tech”. Oggi queste compagnie sono famose per essere affidabili e per lavorare con la missione di interconnettere il mondo per il bene comune. La loro credibilità si basa sul fatto che alla luce del sole queste compagnie non hanno alcun incentivo economico nel manipolare i propri dati per fini secondari dal loro business model per un concetto di “Piattaforma” ovvero di enti che si deresponsabilizzano dalla qualità dei contenuti all’interno, creando strumenti di valutazione alla community di utenti, prendendosi però la piena responsabilità sulla qualità del servizio.
Il problema su cui concentrarsi in futuro legato alle “Big Tech” è che sono guidate da esseri umani nei loro consiglio di amministrazione ed oggi come oggi le loro intenzioni positive sono guidate da azionisti visionari, ma questo scenario nei prossimi anni può cambiare e potranno essere governate da altre persone non benevolenti.
Caroline Sofiatti nella sua presentazione “The role of a decentralized data marketplace in the future of AI” svolta durante la Artificial Intelligence Conference di San Francisco ha detto:
“Nel momento nel quale ti affidi i tuoi dati a un normale database centralizzato, diventi dipendente anche dall’organizzazione umana proprietaria di quel database. Perdendo totalmente il controllo”
Un’altra citazione per comprendere meglio questo importante punto è di Peter Thiel pubblicata da MIT Technology Review:
“Il mondo delle Crypto (Blockchain) è decentralizzato, quello dell’AI è centralizzato. O meglio, se volete vederla più in termini ideologici, Crypto (Blockchain) è un ideale Libertarian (ideologia non traducibile in italiano, da non confondersi con liberalismo), AI è comunismo.”
Domanda 3: come capire la qualità dei dati?
La terza domanda è “Come possiamo capire la qualità dei dati se non abbiamo la possibilità di leggere gli script che li hanno generati??”
Nel caso in cui un ente voglia costruire algoritmi di Intelligenza Artificiale in ambienti aperti che riescano ad essere affidabili, essi devono essere capaci di comprendere l’affidabilità dei dati con i quali interagiscono, l’unica modalità tecnologicamente sostenibile è di leggere gli script utlizzati nella generazione di ogni singola informazione salvata.
Il problema del web centralizzato (2.0) è che se un ente non è il proprietario del dataset, esso non ha la possibilità di leggere il codice che è stato eseguito quando un determinato dato è stato salvato, solo il dato in se. Nel web 2.0 infatti gli script sono totalmente privati ed eseguiti privatamente nei server dei proprietari. Con moderni algoritmi di Intelligenza Artificiale è possibile calcolare a posteriori quali dati posso essere più credibili di altri, con complesse procedure, utilizzando moltissimo potere computazionale, con costi poco accessibili ed allo stesso tempo risultati non totalmente performanti.
Blockchain + AI è la chiave per costruire tecnologie davvero affidabili?
I problemi di affidabilità del dataset e di riconoscimento qualitativo dei dati sono risolvibili, rendendo tecnologie di Intelligenza Artificiale performanti ed economicamente accessibili ad ogni business o utilizzo grazie alle proprietà base della tecnologia di Blockchain.
Analizzando le opportunità che la Blockchain offre partendo dalle caratteristiche base della rete Bitcoin per esempio, ogni azione intrapresa dagli utenti è pensata per generare dati perpetui, non manipolabili e specialmente senza un proprietario con diritti sul dataset, il che suona molto bene come punto di partenza per allenare algoritmi di Intelligenza Artificiale affidabili.
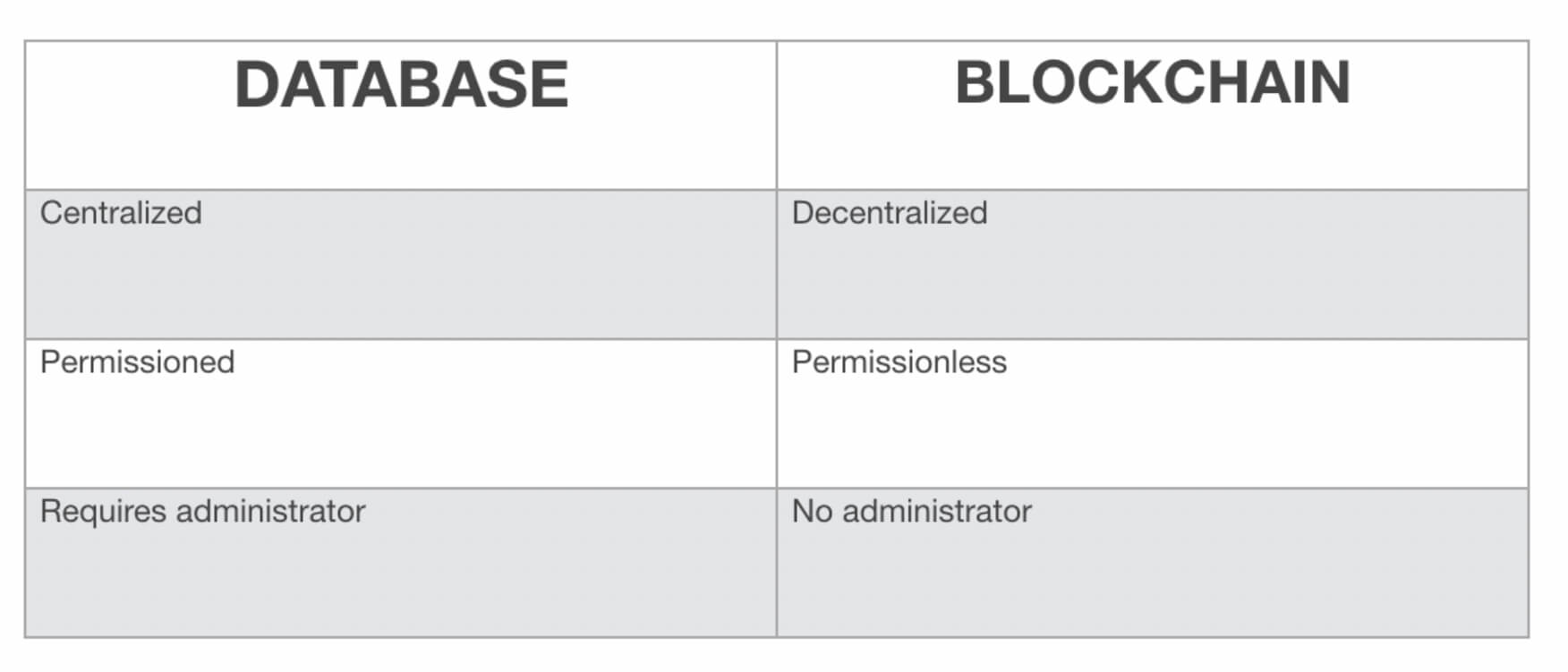
Salih Sarikaya in un articolo di Towards Data Science intitolato “How Blockchain Will Disrupt Data Science: 5 Blockchain Use Cases in Big Data” scrive:
“Se Big(Data) è la quantità, Blockchain è la qualità. Per capire meglio, la Blockchain è focalizzata sulla validazione dei dati, mentre la Data Science o i Big Data implicano solo predizioni quantitative su grande massa di dati.”
L’applicazione più importante nella tecnologia di Blockchain che apre possibilità prima impossibili di costruire in futuro tecnologie di Intelligenza Artificiale sempre più affidabili è l’idea degli “Smart Contract”, introdotti dal primo progetto di seconda generazione di Blockchain Ethereum.
Per comprendere come gli “Smart Contract” sono uno strumento di raccolta dati che risolve il problema di tracciamento qualitativo di informazioni, analizziamo la loro anatomia, ovvero dei perpetui e decentralizzati script che vengono eseguiti pubblicamente, ovvero il codice e la richiesta degli utenti utilizzatori è validata quanto il dato finale ottenuto.
Come ho scritto in un articolo su Hacker Noon “Decentralized Data: “Why Blockchain is meaningless and Trustless is everything”:
“Con l’introduzione degli Smart Contract, in sostanza, uno sviluppatore per interagire con la rete Ethereum deve decentralizzare delle funzioni. Così facendo, ogni volta che un utente interagisce con una funzione precedentemente decentralizzata deve eseguire una transazione Ethereum, convalidando all’interno di un blocco la funzione chiamata, la richiesta ed il risultato. Questi tre aspetti sono fondamentali per fornire dati decentralizzati e totalmente affidabili.”
In sostanza gli Smart Contract possono scrivere dati validati che tracciano la funzione, la chiamata ed il risultato senza alcuna possibilità di manipolazione. Questo è un grande passo avanti per l’industria dell’AI perché affidandosi a questa nuova tipologia di dati, si può tracciarne la qualità, avendo la possibilità di lettura dello script e della richiesta di un’informazione.

Prima del rilascio della prima versione stabile di Ethereum le transazioni in blockchain erano puramente finanziarie o comunque le funzioni non finanziarie erano comunque eseguite su server centralizzati o strati esterni non pubblici e validati, il che non avrebbe aggiunto alcun tipo di validazione ai dati generati utilizzabile per migliorare delle tecnologie di Intelligenza Artificiale.
Iniziando a collezionare un grande ammontare di dati puliti e decentralizzati, potremo finalmente affidarci a tecnologie di AI per scelte automatiche o predizioni, senza temere della bontà di grandi compagnie tecnologiche assicurandoci un futuro ben distante da un’idea distopica simile a “1984”.
In più a livello qualitativo la sicurezza sugli script semplifica la complessità di ambienti aperti, in termini di AI, rendendoli più simili a ambienti chiusi, riducendo sempre di più le complessità del nostro mondo in codice, il che permetterà di far crescere la qualità e la sicurezza che poniamo in tecnologie di AI e riducendo ai minimi termini la maggior parte delle costosissime e complessissime problematiche di Data Science, come la pulizia dei dataset.
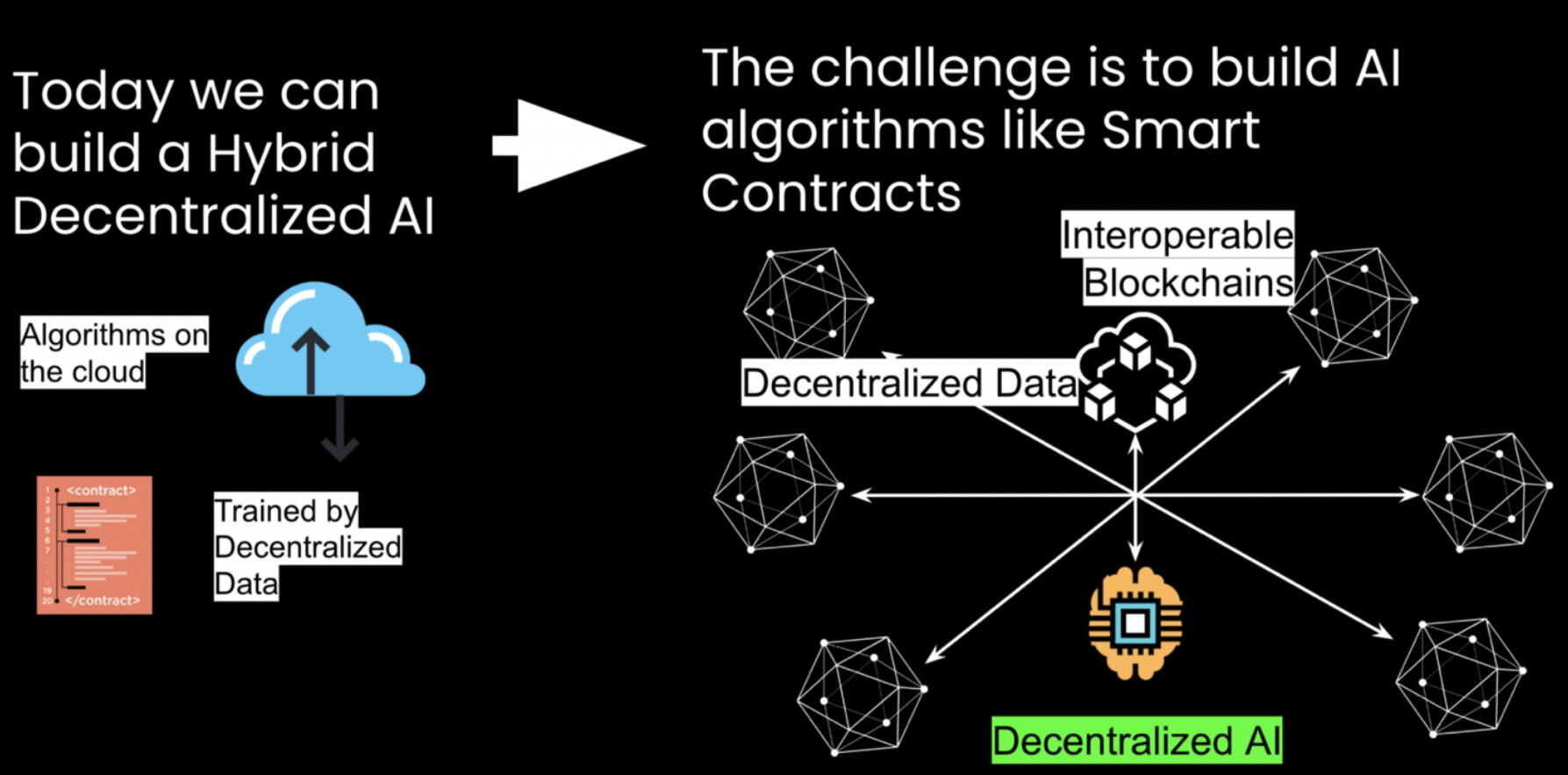
Oggi come oggi possiamo già costruire delle tecnologie di Intelligenza Artificiale Decentralizzate ibride, ovvero algoritmi di AI che vengono eseguiti in ambienti privati come server cloud ma che utilizzano dati decentralizzati in Blockchain. Lo step successivo ed una delle grandi sfide tecnologiche di questa decade e di raggiungere una tecnologia di Intelligenza Artificiale Decentralizzata, ovvero di eseguire algoritmi di AI pubblicamente attraverso tecnologie di blockchain, nello stesso modo nel quale possiamo eseguire semplici funzioni come gli Smart Contract.
***
Per approfondimenti potete seguire Decentralized AI, community nata per diventare un punto di ritrovo tra figure che trattano del punto di incontro tra AI e Blockchain sia in termini tecnologici che etici, regolamentari e di management, in modo tale da condividere il più velocemente possibile le visioni di questa tecnologia prima che sia troppo tardi!


