
Le aziende ricevono centinaia di mail al giorno dai propri clienti ed è necessario che vengano smistate, dividendole per argomenti, in modo che il personale dedicato possa occuparsi di dare una risposta esaustiva. Il mail classifier automatizza il processo di smistamento. La soluzione comprende tecniche di Natural Language Process per interpretare la mail e tecniche di Machine Learning per classificarla in modo corretto.
Indice degli argomenti:
Un progetto di CSI Piemonte
Il progetto del mail classifier è nato dalla collaborazione fra CSI e Regione Piemonte per la gestione delle mail della tassa automobilistica, il bollo auto. Gli uffici regionali ricevono per il bollo auto una grande quantità di mail sia da cittadini che da altri enti regionali.
Le mail venivano smistate manualmente in 15 categorie. Vista la varietà di contenuti di queste mail il CSI ha proposto una soluzione basata su machine learning: usare lo storico delle mail già classificate in precedenza per insegnare a un algoritmo a riconoscere nuove mail. L’approccio innovativo si è rivelato corretto, ad oggi il mail classifier è utilizzato con profitto dagli uffici regionali che si occupano del bollo auto.
Come funziona il mail classifier
Quando si riceve una nuova mail, questa viene automaticamente “letta”, classificata e spostata nella cartella opportuna. La soluzione non cambia il modus operandi degli operatori dell’azienda. Quando l’operatore apre il client mail si trova le mail già smistate nelle cartelle corrispondenti.
Per l’azienda, adottare questa soluzione significa ridurre effort e tempo per lo smistamento delle mail quindi una risposta più rapida e attenta a tutti i clienti.
La soluzione proposta comprende le fasi di:
- allenamento del modello di machine learning
- lettura di una nuova mail
- filtro della mail secondo regole definite dall’azienda
- classificazione della mail tramite modello
- spostamento della mail nella categoria
- eventuale risposta automatica alla mail secondo la categoria
I moduli di cui si compone il mail classifier
Mail classifier
Questo modulo è in ascolto sulla casella mail: ogni volta che arriva una nuova mail la classifica. A seconda della classificazione questo modulo sposta la mail nella cartella corrispondente. La classificazione avviene in due fasi: regole e modello.
Classificazione tramite regole
L’azienda può definire alcune regole utilizzate per classificare le mail. Le regole possono riguardare mittente, soggetto e contenuto della mail. Nel caso del mittente si possono definire una serie di indirizzi mail o di domini. Nel caso di soggetto e contenuto si possono definire una serie di parole chiave da cercare.
Quando una nuova mail arriva passa attraverso tutte le regole. La prima regola che viene rispettata decide la categoria della mail.
Esempio regole:
| Campo | Contenuto | Classificazione |
| mittente | (dominio) | clienti importanti |
| soggetto | urgente (parola chiave) | mail urgenti |
Quando arriva una nuova mail da mario.rossi@acme.com questa rispetta la prima regola e quindi viene subito classificata e spostata nella cartella “clienti importanti”.
Quando arriva una mail con oggetto “pagamento urgente” questa viene classificata come “mail urgenti”.
Il sistema a regole è uno strumento efficace per le mail di cui si conosce a priori un modo definito per la classificazione. Allo stesso tempo è impossibile definire tutte le regole necessarie a classificare tutte le mail, perché in un testo libero è possibile esprimere lo stesso concetto in modi diversi e imprevedibili.
Ad esempio, potremmo scrivere tutti i sinonimi di “urgente” come parole chiave della seconda regola, ma la mail di un cliente potrebbe non contenere nessuna parola che faccia esplicitamente riferimento all’urgenza, mentre un operatore leggendo il testo della mail si accorgerebbe subito che è una mail ad alta priorità.
Per questo motivo è necessario utilizzare un modello di machine learning che abbia imparato a classificare le mail “leggendo” il loro contenuto.
Seguendo il paradigma del machine learning, non vogliamo scrivere tutte le regole ma vogliamo che un algoritmo le impari da solo guardando degli esempi.
Classificazione tramite modello
Quando la mail non rispetta nessuna regola questa viene classificata utilizzando il modello allenato tramite il mail trainer. Soggetto e contenuto della mail vengono passati come input al modello che restituisce la classificazione.
Tutti gli algoritmi di machine learning quando compiono una classificazione (prediction) danno un grado di confidenza della predizione stessa. Nel nostro caso la confidence indica quanto il modello è sicuro che quella mail appartenga alla categoria predetta. Rispetto a questo grado di confidenza viene impostata una soglia minima da superare, in modo che il mail classifier sposti solo le mail di cui si è sufficientemente sicuri appartenere a quella categoria. Le mail con una classificazione incerta rimangono nella casella principale senza essere smistate.
Una importante metrica di business verso il cliente risulta essere: su tutte le mail ricevute quante sono state smistate.
Risposta automatica
Per ogni categoria è possibile impostare una risposta automatica. Quando una nuova mail viene classificata con successo e la categoria lo prevede il mail classifier risponde alla mail automaticamente.
Esempio risposta automatica:
| Classificazione | Risposta |
| clienti importanti | Gentile cliente… |
Quindi ogni volta che riceviamo una mail e questa viene classificata come “clienti importanti” il mailclassifier risponde autonomamente con il testo impostato.
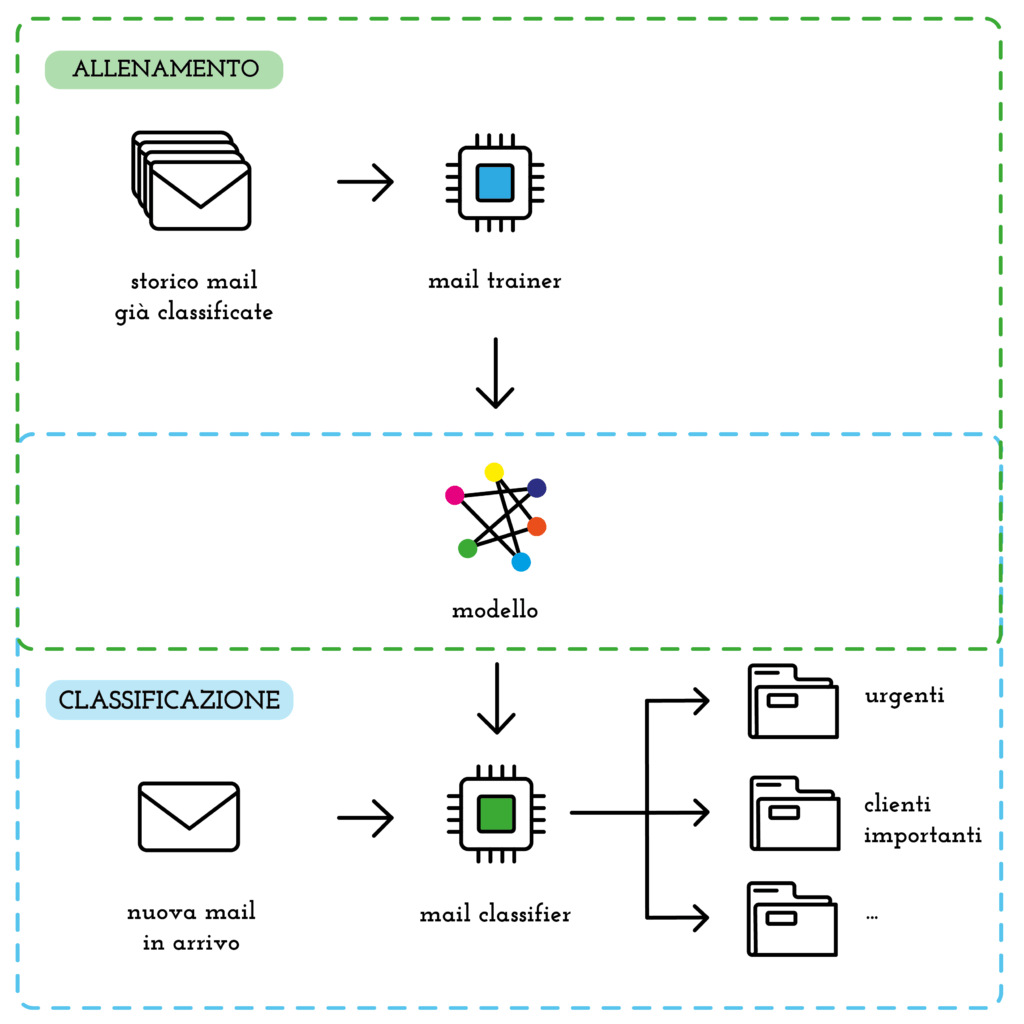
Mail Trainer
Per allenare il modello è necessario preparare un set consistente di mail, ognuna con la categoria (etichetta) di appartenenza. Possiamo pensare a questo set come lo storico delle mail ricevute e già smistate in precedenza dall’azienda. Vogliamo insegnare al modello come smistare le mail facendogli “vedere” tutte le mail ricevute e come queste sono state categorizzate.
Il dataset, l’insieme di mail con categoria corrispondente, è l’input del modulo mail trainer che ha il compito di allenare e testare diversi modelli di machine learning al fine di trovare il più performante.
Questo processo può essere diviso in due parti: vettorizzazione e modello.
La vettorizzazione consiste nel trasformare le parole in numeri in modo che un testo possa essere l’input di un algoritmo di machine learning. Nel nostro caso, i campi di soggetto e contenuto della mail vengono trasformati in un vettore. Questo vettore è l’input per l’allenamento del modello di machine learning.
Nella soluzione di CSI Piemento la vettorizzazione viene fatta con diversi algoritmi fra cui TF-IDF, che considera la frequenza delle parole che caratterizzano la mail, e FastText algoritmo di Facebook.
Una volta che le mail sono state trasformate in vettori, viene fatto un allenamento supervisionato provando diversi algoritmi fra i quali random forest, naive bayes e support vector machine. Per ogni algoritmo viene applicato una procedura chiamata ottimizzazione degli iperparametri (grid search) per massimizzare le performance di ciascun algoritmo.
Una volta allenati tutti i modelli si sceglie il migliore. Per valutare le prestazioni di un modello si ricorre a diverse metriche: accuracy, f-score e ROC-AUC. Il modello con le metriche migliori è, di fatto, il modello che meglio riesce a classificare nuove mail.
L’output di questo modulo è il miglior modello allenato sul dataset iniziale, il mail classifier utilizza questo modello per la classificazione.




